

尚硅谷大数据技术之 HBase
—————————————————————————————
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
第 1 章 HBase 简介
1.1 什么是 HBase
HBASE 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用 HBASE
技术可在廉价 PC Server 上搭建起大规模结构化存储集群。
HBASE 的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就
能够处理由成千上万的行和列所组成的大型数据。
HBASE 是 Google Bigtable 的开源实现,但是也有很多不同之处。比如:Google Bigtable
利用 GFS 作为其文件存储系统,HBASE 利用 Hadoop HDFS 作为其文件存储系统;Google
运行 MAPREDUCE 来处理 Bigtable 中的海量数据,HBASE 同样利用 Hadoop MapReduce 来
处理 HBASE 中的海量数据;Google Bigtable 利用 Chubby 作为协同服务,HBASE 利用
Zookeeper 作为对应。
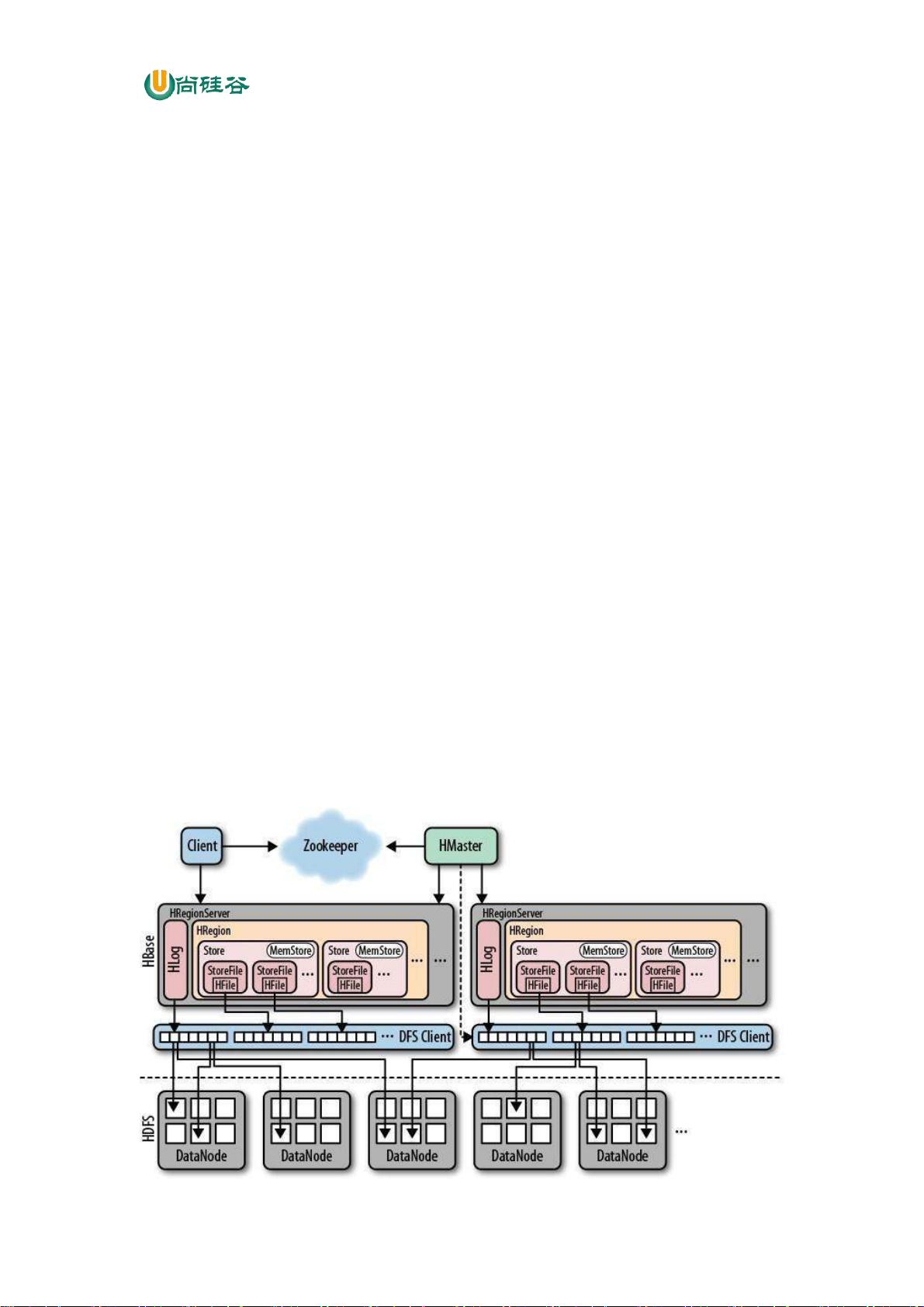
1.2 HBase 中的角色
1.2.1 HMaster
功能:
1) 监控 RegionServer
2) 处理 RegionServer 故障转移
3) 处理元数据的变更
4) 处理 region 的分配或移除
5) 在空闲时间进行数据的负载均衡
6) 通过 Zookeeper 发布自己的位置给客户端
1.2.2 RegionServer
功能:
1) 负责存储 HBase 的实际数据
2) 处理分配给它的 Region
3) 刷新缓存到 HDFS
4) 维护 HLog
5) 执行压缩



剩余32页未读,继续阅读













评论0