
逻辑回归
分类算法与回归算法的不同在于因变量是否是连续变量,逻辑回归可用于分
类,本文的内容包括:(一)线性回归分类算法的弊端,(二)逻辑回归函数,
(三)、正则化。
一、线性回归分类算法的弊端
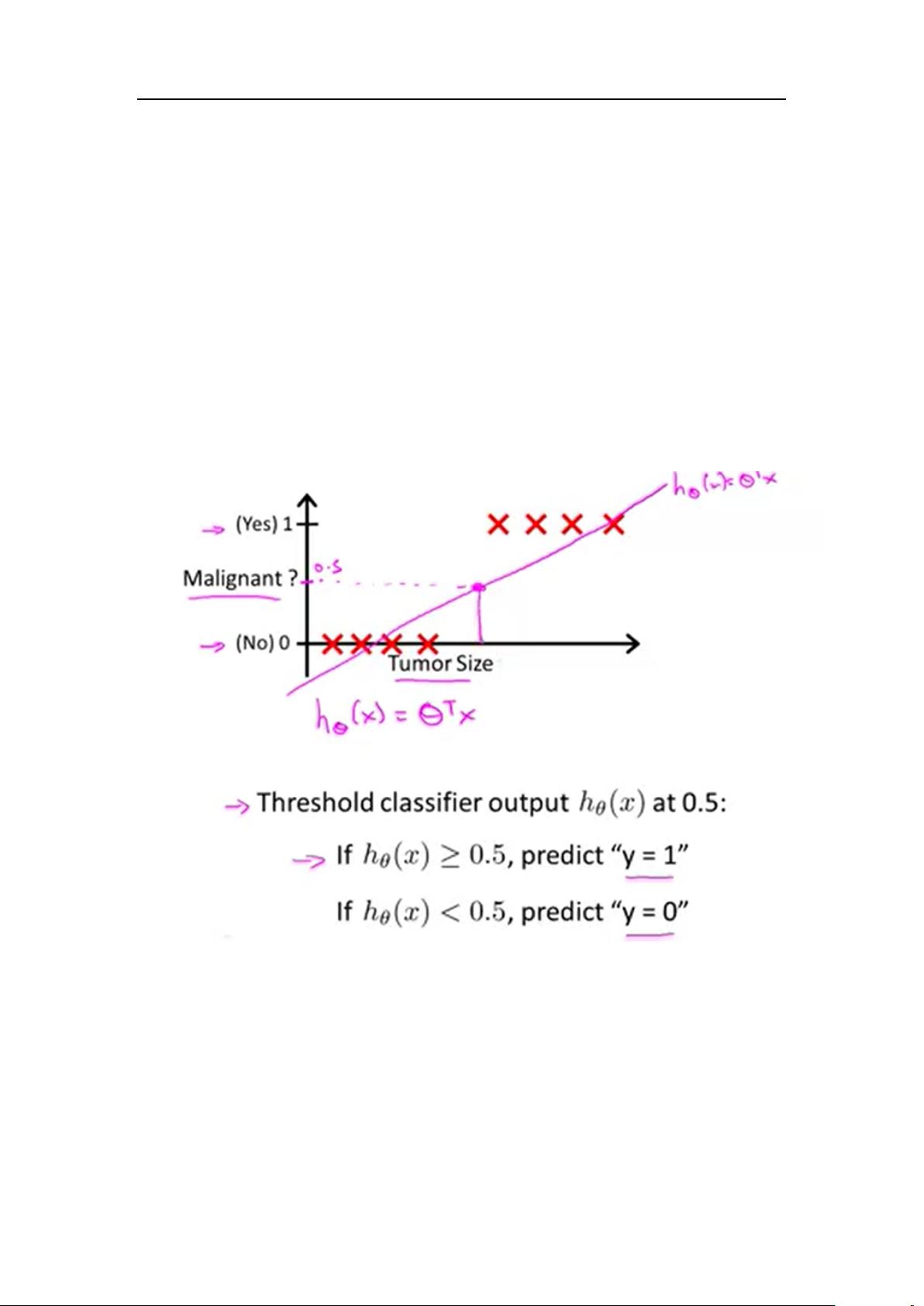
线性回归算法预测值为连续的,线性回归分类算法受到训练样本的影响,如
下图:
(一)对训练样本进行建模,当阈值大于等于 0.5 时则判断为恶性肿瘤,反
之为良性。对于该训练样本的分布,线性回归分类算法能够正确分类,但假如一
个特征分布偏离分布区域的训练样本时,则导致线性建模公式发生了改变,如下
图蓝色曲线:

剩余10页未读,继续阅读

今年也要加油呀
- 粉丝: 26
- 资源: 312









最新资源
- 基于增量容量分析(ICA分析)和差分电压分析(DVA分析)的锂离子电池SOH和RUL预测 包括对原始数据的处理、滤波、绘制IC和DV曲线、提取特征、预测模型的构建
- 基于java的企业员工信息管理系统论文.doc
- 基于java的扫雷游戏的设计与实现论文.doc
- 毕业设计Jupyter Notebook基于深度网络的垃圾识别与分类算法研究项目源代码,用PyTorch框架中的transforms方法对数据进行预处理操作,后经过多次调参实验,对比不同模型分类效果
- 鸿蒙学习记录http网络请求
- 基于javaweb的沙发销售管理系统论文.doc
- 机器人运动学控制,simulink仿真模型,基于滑膜边结构控制,学习滑膜控制的不二法门,文件包含模型的说明和模型原理讲解
- 小红书2024新年市集合作方案解析与品牌营销策略
- 微藻检测18-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- 基于LCL滤波器的单相光伏逆变器控制设计的MATLAB-Simulink仿真
- 用于Unity使用NuGet
- 2024年全球干式变压器行业规模及市场占有率分析报告
- 基于深度学习的视频描述综述:视觉与语言的桥梁
- NE555+74LS192+74LS48电子秒表课程设计报告(纯数电实现)
- 基于滑膜观测器和MTPA的内置式永磁同步电机无位置传感器模型
- 单相全桥逆变电路MATLAB仿真,原理图设计,单相全桥逆变器设计资料,ti的参考,可用做光伏并网逆变器,400V输入,220V输出 包括硬件ad原理图设计,pcb设计,设计指南,bom表等,资料齐全
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0