
林轩田《机器学习基石》课程笔记5 -- Training versus Testing1

需积分: 0 74 浏览量
更新于2022-08-03
收藏 1016KB PDF 举报
在《机器学习基石》课程笔记5中,作者探讨了机器学习中的核心问题——Training与Testing,以及它们在无限Hypothesis Set情况下的可行性。机器学习的目标是找到最佳的函数g,使得训练误差(training error)尽可能小,并且期望误差(expected error)也小,从而确保模型具有良好的泛化能力。
在前四节课中,课程主要围绕以下几个要点展开:
1. **机器学习定义**:机器学习旨在通过数据找到最佳函数g,最小化损失函数L。
2. **可行性条件**:基于NFL定理,若样本量足够大且假设空间(hypothesis set)有限,机器学习是可行的。这依赖于霍夫丁不等式,它保证了在大量数据下,即使存在很多假设,也可以避免因“Bad Data”导致的错误。
3. **算法应用**:介绍了如PLA(Perceptron Learning Algorithm)和Pocket算法等,用于解决监督学习中的二元分类问题。
4. **统计学联系**:利用统计学原理,将学习算法与概率理论相结合,证明在特定条件下,机器学习的期望误差可近似等于训练误差。
课程接着讨论了Hypothesis Set的大小(M)对机器学习的影响:
- **M较小**:霍夫丁不等式保证了低的训练误差,但由于选择的假设有限,可能无法找到使期望误差也极小的hypothesis。
- **M较大**:训练误差可能高,因为假设之间的差距大,但更大的M可能使得找到低期望误差的假设成为可能。
关键在于找到合适的M值,使其既能保证训练误差小,又能确保泛化性能。当M无限大时,问题在于如何处理无限假设空间。作者通过分析PLA算法,指出虽然直线的数目是无限的,但通过限制有效假设(Effective Number of Hypotheses)到有限个,依然可以保证学习的可能性。
为了量化有效假设的数量,文章举例分析了在二维平面上划分点的直线种类。随着点的数量增加,尽管总的直线种类看似无限,但实际上有效直线数量的增长受到限制,满足一定的函数关系,如2^N-2。这种分析表明,即使面对无限假设空间,只要能有效地限制实际参与决策的假设数量,机器学习仍然是可行的。
总结来说,机器学习的核心挑战在于平衡训练误差和泛化能力,这涉及到假设空间的大小、数据量以及数据分布。通过统计学方法和对无限假设空间的有效处理,可以确保机器学习在实际应用中具备良好的学习效果。这一节课程深化了对机器学习可行性的理解,揭示了在理论和实践中如何处理复杂性与效率之间的权衡。
作者:红色石头 公众号:AI有道(id:redstonewill)
上节课,我们主要介绍了机器学习的可行性。首先,由NFL定理可知,机器学习貌似
是不可行的。但是,随后引入了统计学知识,如果样本数据足够大,且hypothesis个
数有限,那么机器学习一般就是可行的。本节课将讨论机器学习的核心问题,严格证
明为什么机器可以学习。从上节课最后的问题出发,即当hypothesis的个数是无限多
的时候,机器学习的可行性是否仍然成立?
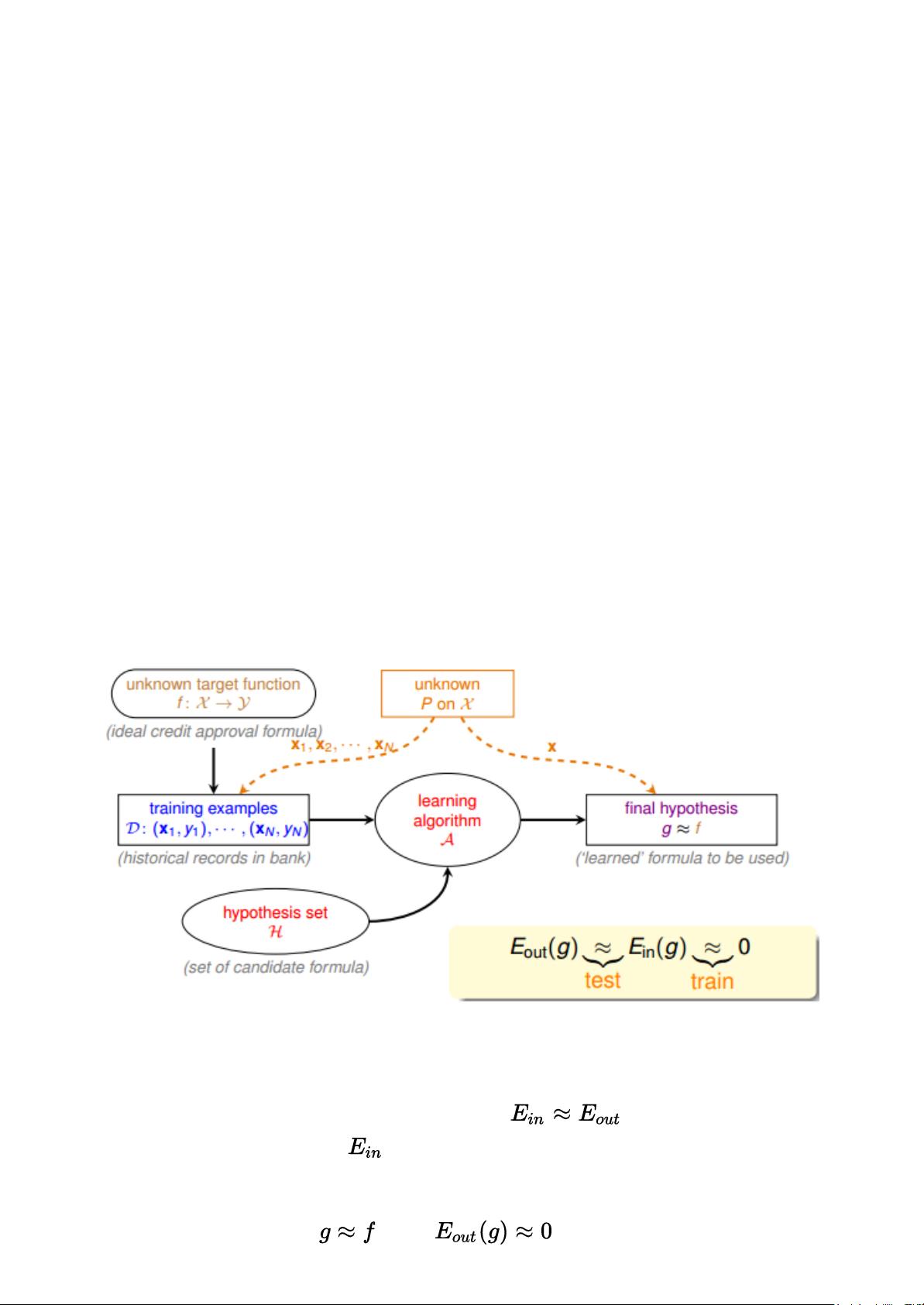
我们先来看一下基于统计学的机器学习流程图:
该流程图中,训练样本D和最终测试h的样本都是来自同一个数据分布,这是机器能够
学习的前提。另外,训练样本D应该足够大,且hypothesisset的个数是有限的,这样
根据霍夫丁不等式,才不会出现BadData,保证 ,即有很好的泛化能
力。同时,通过训练,得到使 最小的h,作为模型最终的矩g,g接近于目标函数。
这里,我们总结一下前四节课的主要内容:第一节课,我们介绍了机器学习的定义,
目标是找出最好的矩g,使 ,保证 ;第二节课,我们介绍了如何让
林轩田《机器学习基石》课程笔记5Trainingversus
Testing
一、RecapandPreview

剩余9页未读,继续阅读
182 浏览量
2011-12-29 上传
133 浏览量
150 浏览量
2021-02-07 上传
2021-06-29 上传
155 浏览量
188 浏览量
2016-04-01 上传
175 浏览量
147 浏览量
2022-02-24 上传
125 浏览量
资源评论


爱设计的唐老鸭
- 粉丝: 31
- 资源: 291









最新资源
- 538114a36f4815de38d10f977a2e7219.pdf
- mermaid代码转图片工具
- 基于PCA主成分分析的BP神经网络回归预测MATLAB代码详解-初学者上手指南,基于PCA主成分分析的BP神经网络回归预测MATLAB代码详解:数据预处理、KMO验证及神经网络预测,基于PCA主成分
- 基于分布式驱动电动汽车的路面附着系数估计:无迹与容积卡尔曼滤波方法的高效精准估算,基于分布式驱动电动汽车的路面附着系数估计:无迹与容积卡尔曼滤波方法的高效精准估算,基于分布式驱动电动汽车的路面附着系数
- CloudCompare版本v2.13完整源码
- 基于Python的Django-vue基于大数据技术的智慧居家养老服务平台源码-说明文档-演示视频.zip
- 基于TimeNet与TSMixer的先进时间序列预测模型:创新、优化与多变量处理的最佳选择,标题:TimesNet与TSMixer融合的先进时间序列预测模型:创新、高效且潜力无穷的预测新范式,Time
- 粒子群算法PSO优化随机森林RFR回归预测MATLAB代码:EXCEL数据读取与代码解析适用于初学者上手实践,教程粒子群算法(PSO)优化随机森林(RFR)的回归预测MATLAB代码,注释清楚+读
- Xray主动扫描报告1.html
- MYDB技术文档.zip
- 基于Python的Django-vue基于数据可视化的智慧社区内网平台设计与实现源码-说明文档-演示视频.zip
- 3月3日版代码-first-web.rar
- COMSOL多物理场耦合在瓦斯抽采中的应用案例研究:从理论模型到实践探索(涵盖钻孔瓦斯抽采、顺层抽采等),COMSOL瓦斯抽采案例:多物理场耦合的数值模拟与工程实践研究,涉及钻孔瓦斯抽采模型、复杂热流
- 基于Python的Django-vue基于协同过滤的儿童图书推荐系统实现源码-说明文档-演示视频.zip
- WordPress主题:Haida多功能响应式WordPress高级主题1.3.6最新版.zip
- 64位 WPS 支持的VBA插件
