《网络数据采集》第6章课件201912011

需积分: 0 195 浏览量
更新于2022-08-03
收藏 885KB PDF 举报
Scrapy是一个强大的Python爬虫框架,专为网络数据采集、数据挖掘、网络监控以及自动测试而设计。在构建健壮的爬虫系统时,Scrapy提供了高效和灵活的解决方案。以下是对Scrapy框架的深入解释。
2.2.1 Scrapy的主要功能:
Scrapy的核心功能是爬取网页并提取所需数据。它可以用于各种用途,如数据挖掘以发现有价值的信息,网络监控以跟踪网站变化,以及自动测试以确保网页功能的正确性。它的设计目标是简化和加速爬虫的开发过程。
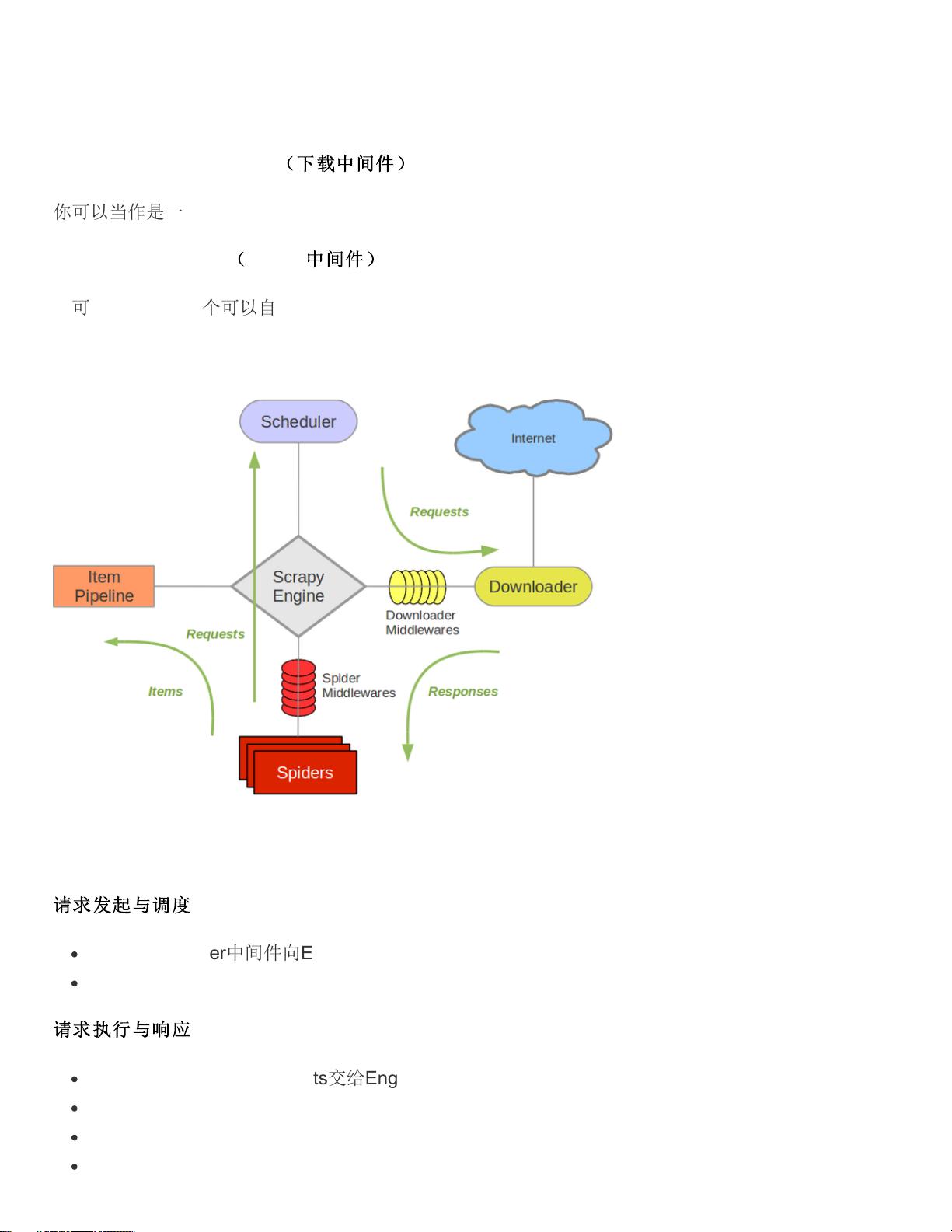
2.2.2 Scrapy的基本结构:
Scrapy由多个核心组件组成,包括Scrapy Engine(引擎)、Scheduler(调度器)、Downloader(下载器)、Spider(蜘蛛)和Item Pipeline(物品管道)。下面简要介绍一下这些组件的作用:
- Scrapy Engine:作为整个框架的心脏,它协调各个组件的工作,处理数据流和信号。引擎通过调度器安排爬取任务,与下载器通信获取网页内容,然后将数据传递给蜘蛛解析,最后通过物品管道处理和存储数据。
- Scheduler:调度器负责接收引擎发来的请求,并按照一定策略进行排队和调度,决定何时向下载器发送下一个请求。
- Downloader:下载器负责实际的网络请求,获取网页的HTML或其他内容,并将其返回给引擎,供蜘蛛解析。
- Spider:蜘蛛是用户编写的具体爬取逻辑,用于解析由下载器返回的网页内容,提取所需的数据,并生成新的请求(如果需要进一步爬取)。
- Item Pipeline:物品管道处理从蜘蛛中获取的数据,进行清洗、验证、存储等操作,确保数据质量,并将其导出到指定的存储格式或系统。
2.2.3 Scrapy的特性与优势:
Scrapy采用了异步请求处理,允许并发执行多个请求,极大地提高了爬取效率。此外,它还提供了一些关键特性:
- 自动检测和处理编码问题,确保数据的正确性。
- 支持多种数据提取方式,如正则表达式、CSS选择器和XPath表达式。
- 提供了交互式shell,方便开发者进行实时调试和测试。
- 数据可以导出为JSON、CSV、XML等多种格式,方便进一步分析和存储。
- 具有强大的扩展性,用户可以通过编写自定义中间件和插件来实现特定功能。
- 内置多种中间件,如处理HTTP缓存、身份验证、代理设置等,增强了爬虫的适应性和礼貌性。
- 支持远程控制台和爬行深度限制,便于管理和监控爬虫行为。
2.2.4 Scrapy工作原理:
Scrapy的工作流程如下:
1. 引擎启动,向调度器添加起始URL。
2. 调度器返回一个待爬取的URL给引擎。
3. 引擎将URL传递给下载器,下载器获取网页内容。
4. 下载器将内容返回给引擎,引擎将内容传递给相应的蜘蛛进行解析。
5. 蜘蛛解析网页,提取数据,可能还会生成新的请求。
6. 引擎将新请求放入调度器,重复步骤2-5,直到所有请求都被处理。
7. 蜘蛛提取的数据通过物品管道进行处理,最终存储或导出。
通过以上讲解,我们可以看出Scrapy是一个强大而灵活的爬虫框架,它为构建复杂和健壮的网络数据采集系统提供了全面的支持。无论是初学者还是经验丰富的开发者,都能从中受益,实现高效的网络数据抓取。

网络
数
据
采
集
第
七
章
构
建
健
壮
的
爬
虫
系
统
讲师姓名:
授课时间:
共32课时,第23-28课时
1
上
节
回
顾
上节课介绍了Selenium爬取网页的基本方法,同时介绍了几个案例。
2
本
节
课
程
主
要
内
容
内容列表:
本节目标
Scrapy爬虫框架基础
scrapy具体操作与应用
本节总结
课后练习
2.1
本
节
目
标
掌握Scrapy框架的构成要素
掌握Scrapy框架的工作原理
能够应用Scrapy设计网络数据采集系统
2.2 Scrapy
爬
虫
框架
基
础
这一讲,我们介绍网络爬虫框架Scrapy的基本组成、工作原理,并介绍使用Scrapy构建较为健壮的网络
爬虫应用程序的方法。



剩余38页未读,继续阅读
2022-08-04 上传
2022-08-03 上传
2021-11-19 上传
140 浏览量
134 浏览量
137 浏览量
178 浏览量
2022-12-17 上传
2021-12-02 上传
2021-09-29 上传
2021-09-29 上传
137 浏览量
159 浏览量
184 浏览量
166 浏览量
182 浏览量
176 浏览量
2012-05-01 上传
131 浏览量
187 浏览量
2020-02-15 上传
2009-04-05 上传
2021-12-05 上传
2018-05-18 上传
117 浏览量
175 浏览量
资源评论


内酷少女
- 粉丝: 20
- 资源: 302









最新资源
- 机械手自动排列控制PLC与触摸屏程序设计
- uDDS源程序publisher
- 中国风格, 节日 主题, PPT模板
- 生菜生长记录数据集.zip
- 微环谐振腔的光学频率梳matlab仿真 微腔光频梳仿真 包括求解LLE方程(Lugiato-Lefever equation)实现微环中的光频梳,同时考虑了色散,克尔非线性,外部泵浦等因素,具有可延展
- 企业宣传PPT模板, 企业宣传PPT模板
- jetbra插件工具,方便开发者快速开发
- agv 1223.fbx
- 全国职业院校技能大赛网络建设与运维规程
- 混合动力汽车动态规划算法理论油耗计算与视频教学,使用matlab编写快速计算程序,整个工程结构模块化,可以快速改为串联,并联,混联等 控制量可以快速扩展为档位,转矩,转速等 状态量一般为SOC,目
