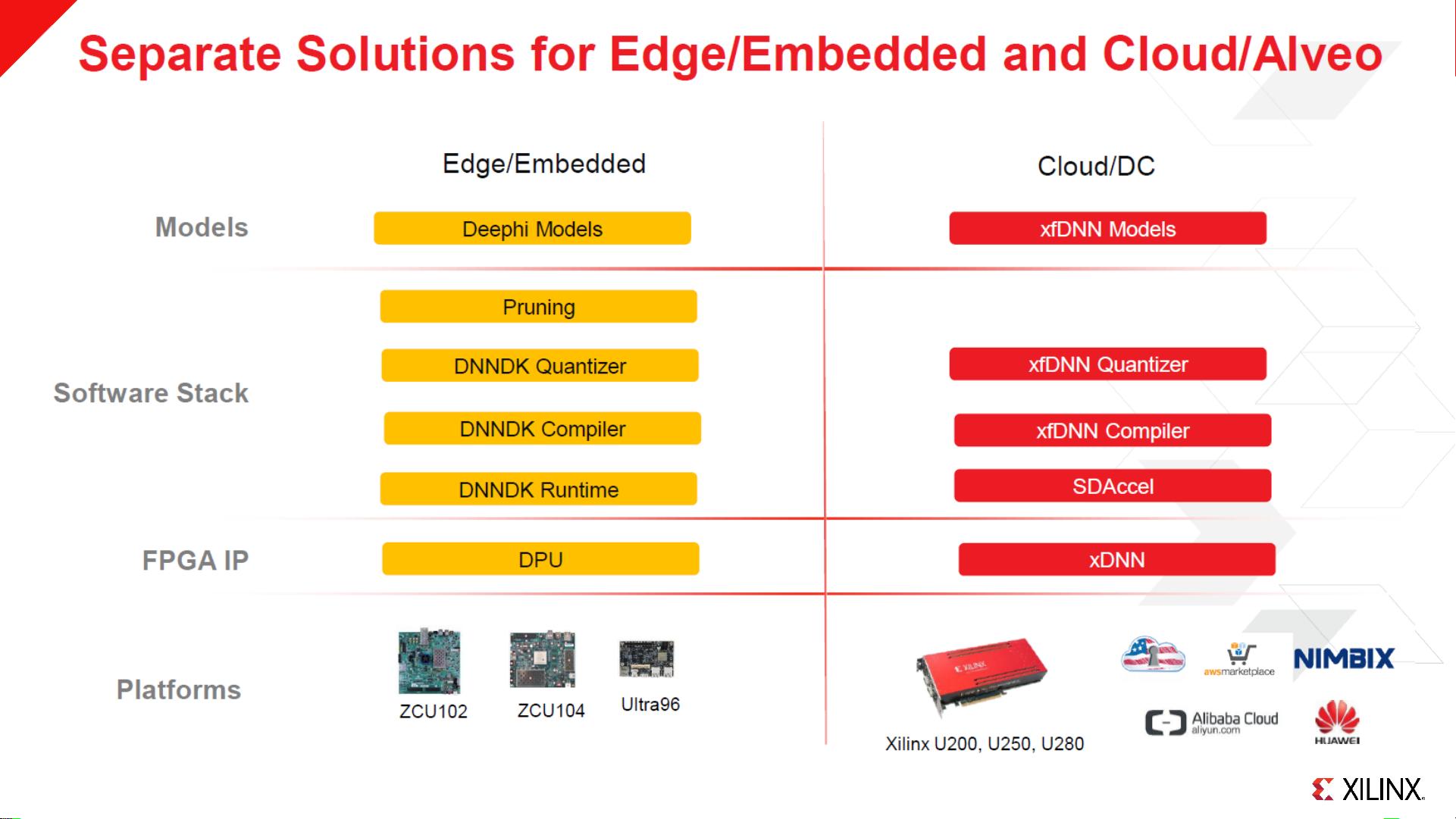
Xilinx边缘深度学习加速器是针对人工智能领域在边缘计算中高效运行设计的一种解决方案。Xilinx作为一个专注于可编程逻辑器件的公司,其在AI领域的焦点主要在于推理阶段,即模型在实际应用中的实时决策过程。他们提供的AI开发者中心(AI Developer Hub)为开发者提供了丰富的资源和工具,以支持深度学习模型的优化和部署。 Xilinx的独特之处在于其专利的深度学习加速技术,这包括突破性的DL加速和压缩技术。这些技术能够将深度学习加速器的尺寸减小到更小的设备上,同时提高每瓦性能,即在保持高性能的同时降低能耗。此外,独特的修剪技术提供了显著的竞争优势,通过量化和修剪,进一步优化模型,减少内存占用,提高运行效率。 Xilinx边缘AI解决方案栈涵盖了从模型到硬件平台的全链条。例如,他们提供了一系列开发板和系统级模块(SOM),如Z7020板、Z7020 SOM、ZU2 SOM、ZU2/3卡、ZU9卡、ZCU102、ZCU104以及Ultra96等,这些硬件平台广泛应用于人脸识别、姿态估计、视频分析、车道检测、物体检测和分割等边缘计算场景。 为了方便开发者进行深度学习模型的开发和优化,Xilinx推出了DNNDK(Deep Neural Network Development Kit)。DNNDK包括了DECENT(DEep ComprEssion Tool)、DNNC(Deep Neural Network Compiler)、Runtime N2Cube以及Profiler DSight等工具。DECENT用于模型的压缩,DNNC则负责模型的编译,N2Cube作为运行时环境,而DSight则是性能分析工具。DNNDK支持多种框架,包括Quantization、Beta版本的Pruning功能,以及将模型转换为Caffe框架的工具。 在硬件层面,Xilinx的DPU(Deep Learning Processing Unit)提供了多种选项和接口,如B4096和B1152核心,利用三级并行性(像素、输入通道、输出通道)来提升处理速度。例如,B1152核心适合Z7020/ZU2/ZU3这样的小型核心,提供4*12*12的并行处理能力,而B4096核心则适用于更大的并行计算需求。 Xilinx边缘深度学习加速器的设计与应用结合了高效的硬件平台、专用的开发工具和全面的解决方案栈,旨在帮助开发者在边缘计算环境中实现深度学习模型的高效、低功耗运行,满足各种智能应用的需求。通过不断的技术创新和优化,Xilinx致力于推动AI在边缘计算领域的快速发展。
剩余41页未读,继续阅读


















评论0