基于网约车的语义网络分析11

需积分: 0 187 浏览量
更新于2022-08-04
收藏 1.83MB PDF 举报
【基于网约车的语义网络分析】是通过收集和分析用户在百度贴吧和微博社区对“滴滴出行”等网约车服务的评论,以理解消费者对服务的看法和体验。在这一过程中,涉及到了多个步骤和关键技术。
从百度贴吧和微博社区收集了860条来自百度贴吧、862条滴滴出行的微博评论以及795条滴滴打车的微博评论,共计2517条数据。这些数据包含了用户对网约车服务的各种评价,如便利性、价格、司机素质等方面。
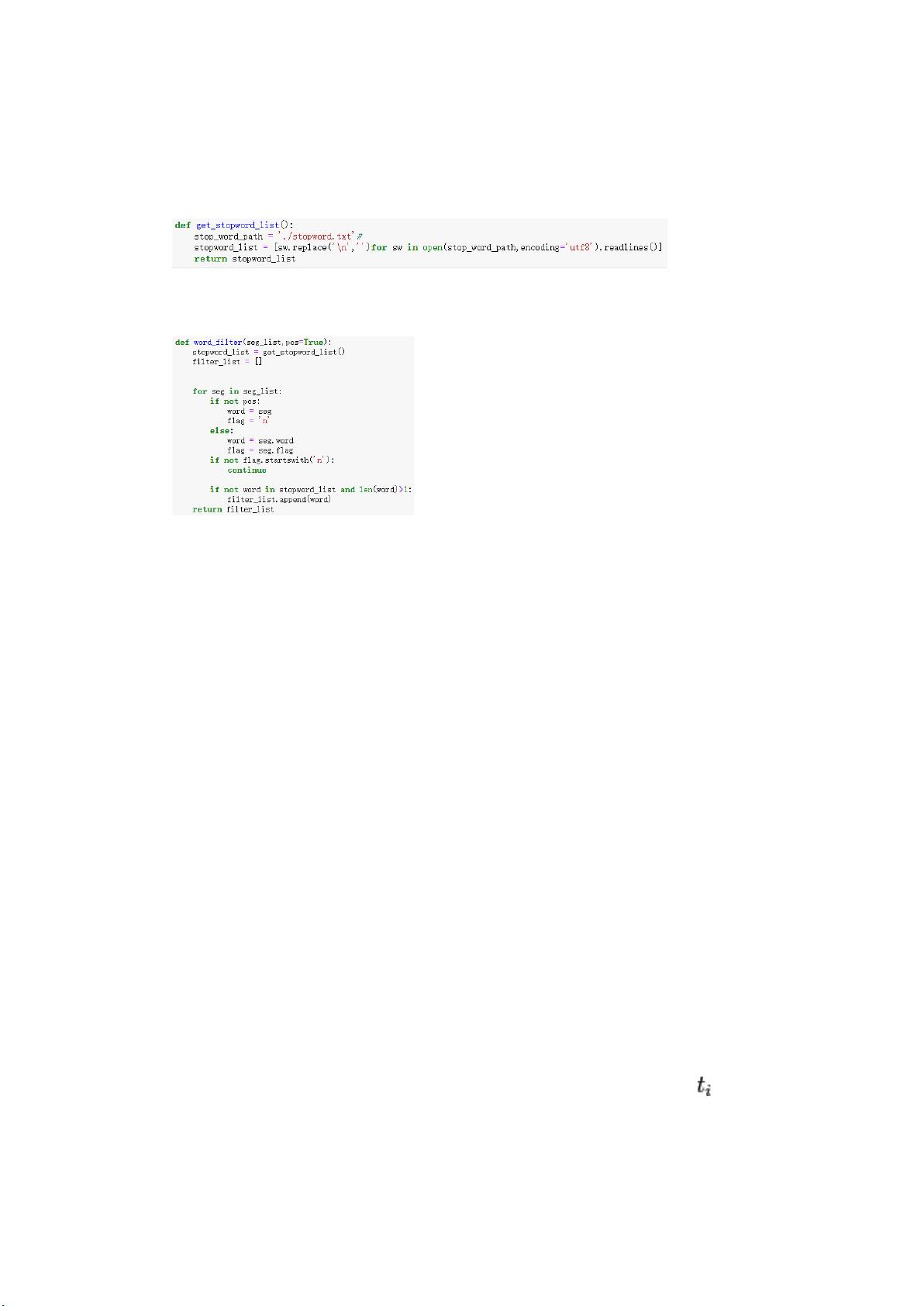
数据预处理是分析的基石。对重复的评论进行了去重处理,利用Python的`drop_duplicates()`函数,将数据量从2517条减少到2482条,确保每条评论的独特性。接着,对去重后的文本数据进行了分词处理,采用Python的jieba库,其`cut()`方法能有效地将中文文本拆分成单词或词组,便于后续分析。
在分词后,为了进一步净化数据,进行了停用词剔除。停用词是那些在语言中常见但往往没有太多含义的词汇,例如“的”、“和”、“在”等。通过加载内置的停用词表,移除了这些干扰信息,使得分析更加聚焦于核心内容。此外,还进行了干扰词过滤,剔除了一些无实际意义或频繁出现但不具分析价值的词汇,比如长度小于2个字符的词。
在预处理完成后,使用Ucient6软件进行语义网络分析。语义网络是一种模型,用于揭示文本中词汇之间的关系,它能解析句子的句法结构,识别关键概念和语义联系。在这个过程中,关键词提取和中心度分析是关键步骤。关键词提取采用了TF-IDF方法,它结合了词频(Term Frequency, TF)和逆文档频率(Inverse Document Frequency, IDF)。TF衡量词在文档中的出现频率,而IDF则反映了词在所有文档中的稀有程度。TF-IDF值高的词,既在文档中频繁出现,又在整体文档集中少见,这样的词往往能够有效区分文档类别。
TF-IDF的计算公式是TF * IDF。TF表示词在文档中的频率,IDF则是对文档中包含该词的文档数的对数倒数。如果一个词在很多文档中都出现,那么它的IDF值就低,反之则高。因此,高TF-IDF值的词是文档主题的重要标志。
中心度分析则包括点度中心性(Degree Centrality)、中间中心性(Between Centrality)和特征向量中心性(Eigenvector Centrality)。点度中心性衡量节点的连接数量,中间中心性关注节点在网络中作为路径中介的角色,特征向量中心性则基于节点邻居的重要性来评估节点的重要性。这三种中心度可以帮助识别网络中最重要或最具影响力的概念。
通过以上分析,我们可以深入了解消费者对网约车服务的态度,识别出讨论中的热点问题,如价格、便利性、安全性和司机质量等,为网约车平台提供改进服务和策略制定的依据。

1. 百度贴吧、微博社区’滴滴出行’网约车评论文本信息展示,其中百度贴吧数据 860 条,
微博社区滴滴出行 862 条,微博社区滴滴打车 795 条,共 2517 条评论数据进行分析
1
经常用,一款实用的 APP,希望能再多点优惠
2
并且打车的发票在手机端就可以直接开出,而且我觉得打车的补贴还是比较
多的,滴滴打车的优势是方便...
3
滴滴出行是个不错的出行平台,最大限度的提高了出行者的权益,但在司机
的准入上要求不严,以致连续...
4
滴滴就是出了事情或者责任就会逃避
5
很想给滴滴好评的,因为它确实方便我出行了,而且滴滴司机给我的印象也
不错。无奈最近它的大众形象...
2.消费者关于网约车的评论文本数据预处理
(1)文本去重
剔除重复的文本数据,加强数据的可用性,利用 python 的 drop_duplicates()函数对
dataframe 结构进行去重处理
文本数据去重之前数据为 2517 条
文本数据去重之后数据为 2482 条
(2)基于语义网络的消费者网约车评论分析分词处理
加载需要处理的文本数据,利用 Python 的 jieba 库进行分词处理,利用 jieba 库的 cut 方法
进行分词处理,文本数据分词部分结果展示:
[['一款', '实用', 'APP', '希望', '多点', '优惠'],['打车','发票','手机',
开出','打车','补贴','滴滴','打车','优势','方便快捷','一竿子','推翻','滴滴
','社会','行业','贡献','网友','历史','出门在外','流量','变得','完善','支
付','方式','一会','专车','来接','滴滴','女子','外出','遭受','侵害','例子
','确实','出行','价格','明朗','十点','县城']]
(3)停用词剔除处理
要对去重后的文本数据进行停用词剔除处理,加载库中的停用词表,对文本数据进行处
理,剔除已经停用的词

剩余14页未读,继续阅读
115 浏览量
2024-02-20 上传
173 浏览量
176 浏览量
188 浏览量
130 浏览量
139 浏览量
142 浏览量
2024-03-01 上传
165 浏览量
130 浏览量
141 浏览量
110 浏览量
159 浏览量
180 浏览量
197 浏览量
2023-05-23 上传
194 浏览量
资源评论


熊比哒
- 粉丝: 35
- 资源: 292









最新资源
- 兆瓦充电系统市场分析:2023年全球市场规模大约为19.6百万美元.docx
- 折叠自行车行业深度分析:2023年全球市场规模大约为151820百万美元.docx
- 脂肪酸行业深度分析:2023年全球市场规模大约为12540百万美元.docx
- 正己烷市场分析:2023年全球市场规模大约为900百万美元.docx
- 研学报告.pptx - 大数据技术研究与应用案例深度剖析
- 脂质体维生素补充剂行业分析:2023年全球市场规模大约为169百万美元.docx
- 植物糖原粉市场分析:2023年全球市场规模大约为231百万美元.docx
- 重型编码器行业分析:2023年全球市场规模大约为312百万美元.docx
- 中空纤维透析器行业分析:2023年全球市场规模大约为5992百万美元.docx
- 质子交换膜(PEM)行业分析:2023年全球市场规模大约为1294百万美元.docx
- 自动血红蛋白仪行业深度分析:2023年全球市场规模大约为1131百万美元.docx
- 自动生化仪行业分析:2023年全球市场规模大约为3289百万美元.docx
- 自覆膜标签市场分析:2023年全球市场规模大约为450百万美元.docx
- 工业级水滑石行业分析:亚太是全球最大的市场.docx
- 工业用压缩机市场分析:2023年全球市场规模大约为31360百万美元.docx
- 固态硬盘(SSD)行业市场:2023年全球市场规模大约为29410百万美元.docx
