
自然语言处理 期末大作业1

自然语言处理是一个涵盖广泛领域的研究,它涉及到计算机理解和生成人类语言。在这个期末大作业中,学生需要实现一个基于编码器-解码器架构的神经网络模型,用于将中文翻译成英文。这个任务属于机器翻译(Machine Translation),是自然语言处理中的一个重要应用。
对于神经网络模型的输入数据,有一个特定的格式要求。每个样本序列需要通过添加特殊标记来标准化长度,例如使用`<pad>`符号填充较短的序列,使其与批次内的其他序列等长。这是为了确保在批处理中所有输入数据能够同时处理。此外,每个句子的开头标识为`<bos>`(beginning of sentence),表示句子的起点;而`<eos>`(end of sentence)则表示句子的结束,这些标记对于模型理解句子的边界至关重要。
实验环境是在Windows 10操作系统下,使用PyCharm作为集成开发环境(IDE),并结合Python 3.6和PyTorch框架进行开发。实验还依赖于其他Python包,如jieba用于中文分词,matplotlib和nltk用于数据处理和可视化,以及numpy和torchvision,这些都是实现神经网络模型所必需的库。
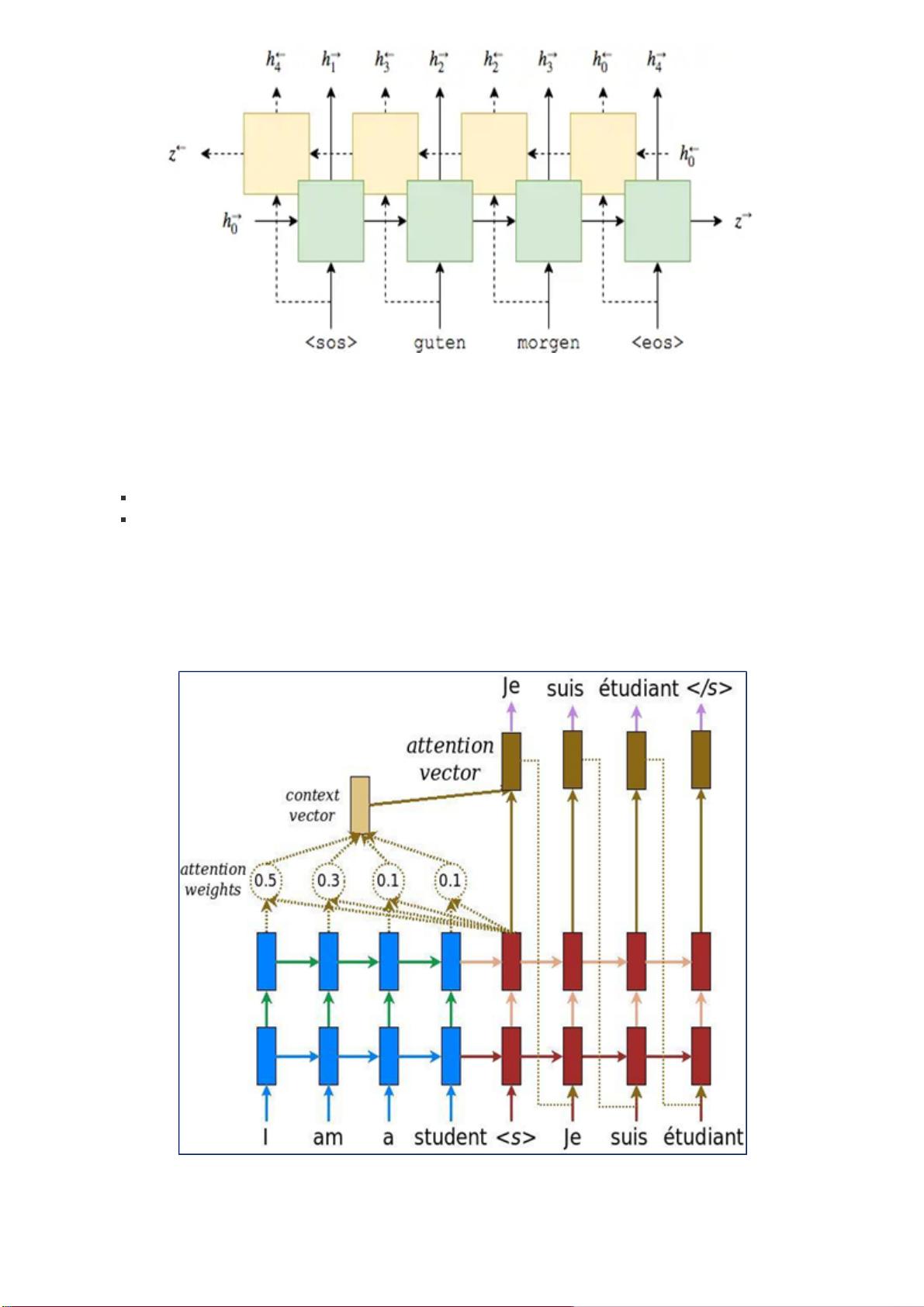
模型的核心是使用LSTM(长短时记忆网络)作为编码器和解码器。编码器部分是一个双向LSTM,它可以捕获中文句子的时间序列特征,并将其转化为固定维度的向量。双向LSTM意味着它同时考虑了前向和后向的信息流,提高了模型的表示能力。解码器部分则采用单向LSTM,利用编码器的最终状态作为初始状态,逐词进行翻译。
在解码过程中,有两种策略可选:教师强制(Teacher Forcing)和课程学习(Curriculum Learning)。教师强制是指在训练时,直接使用真实标签的上一个词作为当前时间步的输入,而课程学习则引入一定的随机性,根据概率p决定是否使用上一步模型预测的词或真实标签。
进一步增强解码器性能的方法是引入注意力机制(Attention)。它允许解码器在解码每个词时,根据源语言句子的不同部分分配不同的权重,形成一个上下文向量(context_vector)。这个向量与解码器当前的隐藏状态拼接,提供更丰富的源语言语境信息,从而提高翻译质量。
输出层通过线性映射和softmax函数将拼接后的向量转换为每个单词的概率分布,使用交叉熵作为损失函数,通过反向传播优化模型参数。最终,编码器和解码器共同构成一个简单的神经网络翻译模型。
在数据预处理阶段,首先对文本进行分词,建立词典,并将文本中的词语替换为对应的数字表示。测试数据的词典必须与训练数据一致,以处理训练集中未出现的词汇。此外,需要在句子前后添加`<BOS>`和`<EOS>`标记,以便模型识别句子边界。分词后,还需对数据进行额外处理,以满足模型输入的要求。

自然语言处理 期末大作业
数据科学与计算机学院
17341190 叶盛源
实
验
环
境
本次实验是在windows10操作系统下进行的。使用的IDE为pycharm
我使用的神经网络框架搭配为pytorch+python3.6。
其他需要安装的包在代码包requirement.txt中包含,可以直接导入。在这里列出生关键的一些依赖包的名
称和版本号:
实
验
原
理
本次实验的目标是用编码器和解码器实现一个中文到英文的神经网络的翻译模型。
编码器使用LSTM的序列神经网络,将 我们的目标句子通过时间序列输入,最 终将一个中文的文本句子
编码成一个特定维数的向量。我们 这里使用的是双向的LSTM模型,最后将前 向和后向的隐藏层输出值
对应位置求和。
jieba==0.39
matplotlib==3.1.1
nltk==3.4.5
numpy==1.17.4
torch==1.3.1
torchvision==0.4.2
剩余11页未读,继续阅读
182 浏览量
2019-07-07 上传
181 浏览量
2022-08-04 上传
2022-08-03 上传
103 浏览量
105 浏览量
124 浏览量
190 浏览量
139 浏览量
170 浏览量
129 浏览量
169 浏览量
139 浏览量
156 浏览量
资源评论

 SanguineYankeeboy2022-11-29这个有配套的代码和数据吗?
SanguineYankeeboy2022-11-29这个有配套的代码和数据吗?- m0_644227312022-12-15你好,请问有代码吗,可以有偿










