
论 文
中国科学 : 信息科学 2016 年 第 46 卷 第 9 期 : 1298–1320
SCIENTIA SINICA Informationis
引用格式: 刘望舒, 陈翔, 顾庆, 等. 软件缺陷预测中基于聚类分析的特征选择方法. 中国科学: 信息科学, 2016, 46: 1298–1320, doi:
10.1360/N112015-00276
c
2016《中国科学》杂志社 www.scichina.com info cn.scichina.com
软件缺陷预测中基于聚类分析的特征选择方法
刘望舒
¬
, 陈翔
¨
, 顾庆
¬
*
, 刘树龙
¬
, 陈道蓄
¬
¬ 南京大学计算机软件新技术国家重点实验室, 南京 210023
南京大学计算机科学与技术系, 南京 210023
® 南通大学计算机科学与技术学院, 南通 226019
* 通信作者. E-mail: guq@nju.edu.cn
收稿日期: 2016–04–25; 接受日期: 2016–05–31; 网络出版日期: 2016–09–18
国家自然科学基金 (批准号: 61373012, 61321491, 91218302, 61202006)、国家重点基础研究发展计划 (973 计划)(批准号: 2009C
B320705)、江苏省高校自然科学研究项目 (批准号: 12KJB520014)、南京大学计算机软件新技术国家重点实验室开放课题 (批准号:
KFKT2016B18) 和南京大学软件新技术与产业化协同创新中心资助项目
摘要 软件缺陷预测通过挖掘软件历史仓库, 构建缺陷预测模型来预测出被测项目内的潜在缺陷程
序模块. 但有时候搜集到的缺陷预测数据集中含有的冗余特征和无关特征会影响到缺陷预测模型的
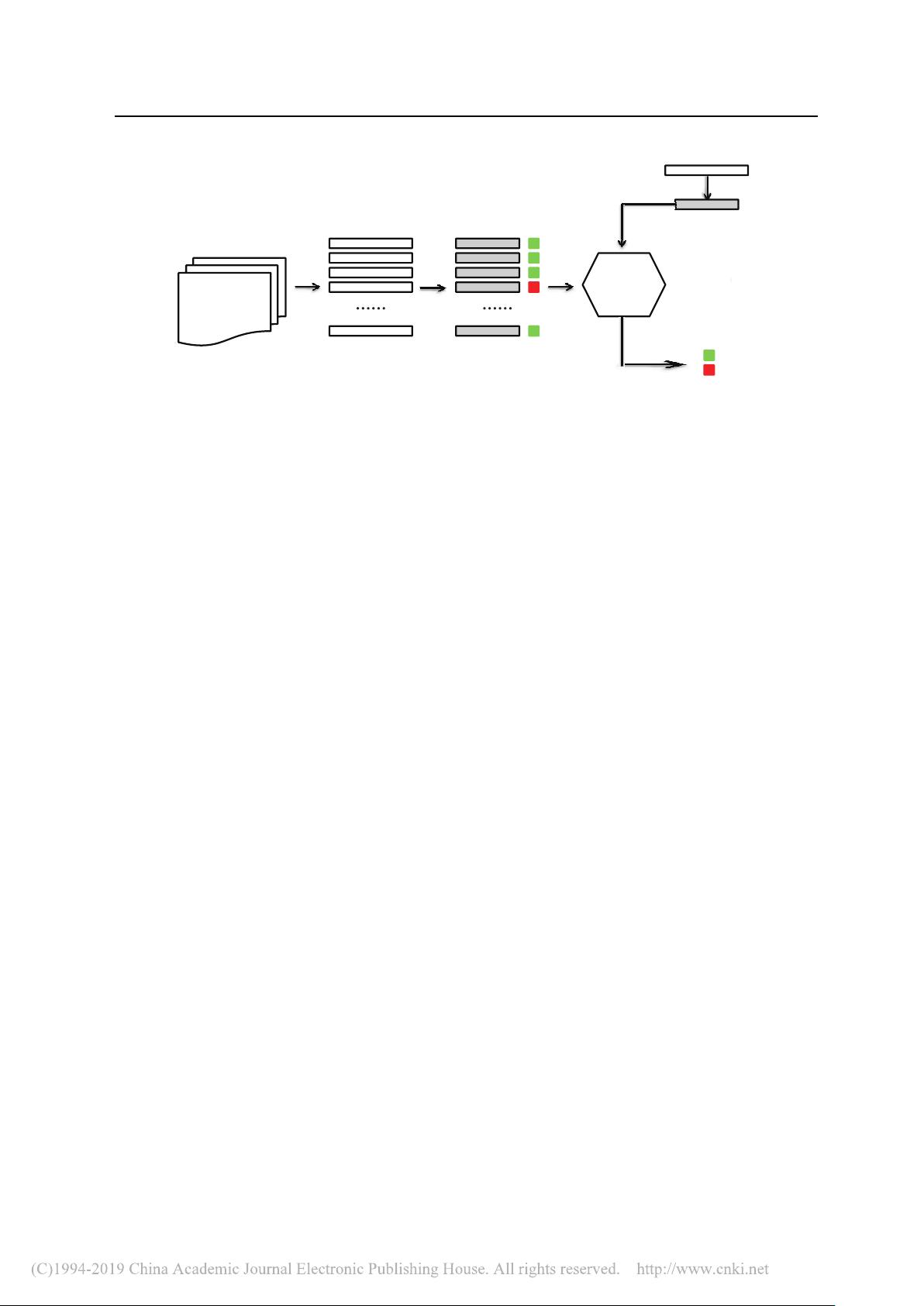
性能. 提出一种基于聚类分析的特征选择方法 FECAR. 具体来说, 首先基于特征之间的关联性 (即
FFC), 将已有特征进行聚类分析. 随后基于特征与类标间的相关性 (即 FCR), 对每个簇中的特征从
高到低进行排序并选出指定数量的特征. 在实证研究中, 借助对称不确定性 (symmetric uncertainty)
来计算 FFC, 借助信息增益 (information gain)、卡方值 (chi-square) 或 ReliefF 来计算 FCR. 以 Eclipse
和 NASA 数据集等实际项目为评测对象, 重点分析了应用 FECAR 方法后的缺陷预测模型的性能,
FECAR 方法选出的特征子集冗余率和比例. 结果验证了 FECAR 方法的有效性.
关键词 软件质量保障 缺陷预测 数据挖掘 特征选择 聚类分析
1 引言
软件缺陷产生于开发人员的编码过程. 需求理解不正确, 软件开发过程不合理或开发人员的经验
不足, 均有可能产生软件缺陷. 而含有缺陷的软件在运行时可能会产生意料之外的结果或行为, 严重
的时候会给企业造成巨大的经济损失, 甚至会威胁到人们的生命安全. 软件缺陷预测 (software defect
prediction, 简称 SDP)
[1, 2]
通过分析软件代码或开发过程, 设计出与软件缺陷相关的度量元 (metrics),
随后通过挖掘软件历史仓库 (software historical repositories) 来创建缺陷预测数据集. 最后基于上述搜
集的缺陷预测数据集, 构建缺陷预测模型, 并用于预测出被测项目内的潜在缺陷程序模块.
但在构建缺陷预测数据集时, 若考虑了大量度量元 (即特征), 会造成数据集中的部分特征是冗余
特征 (redundant feature) 或无关特征 (irrelevant feature). 这类特征的存在会提高缺陷预测模型的构建
时间, 甚至有时会降低模型的预测性能. 因此如何设计出新颖有效的特征选择方法来移除这类特征具
有重要的研究意义.


剩余22页未读,继续阅读













评论0