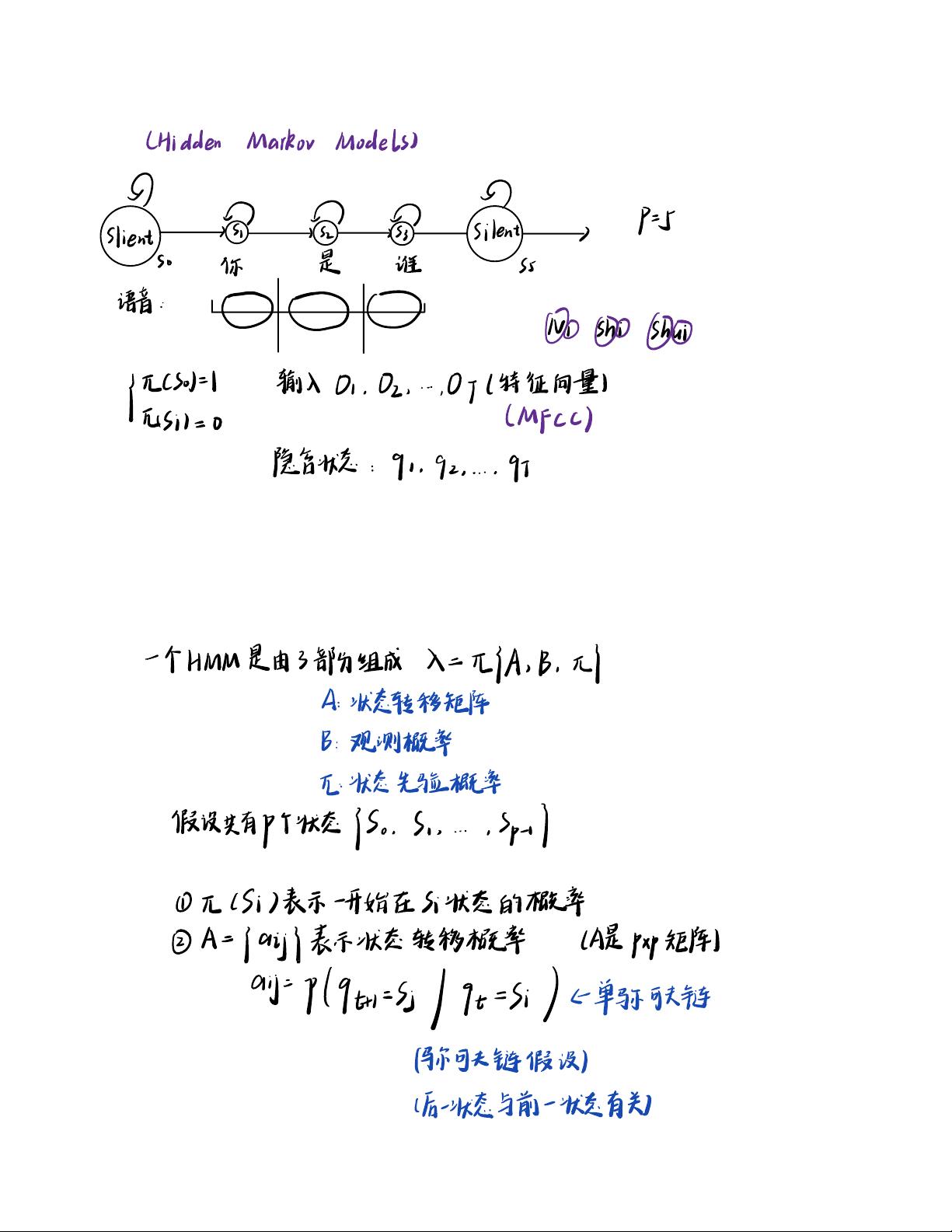
隐含马尔科夫模型(Hidden Markov Model,HMM)是一种统计模型,常用于处理序列数据,如语音识别、自然语言处理等领域。HMM主要由三部分组成:初始状态概率、状态转移矩阵和观测概率。
1. **初始状态概率**:
在HMM中,`lSi`表示开始处于状态`Si`的概率。这个概率是模型的先验概率,它定义了模型开始时处于各状态的可能性分布。
2. **状态转移矩阵**:
矩阵`A`描述了状态之间的转移概率,其中`aj`表示从状态`j`转移到状态`i`的概率。矩阵`A`是一个`pxp`的矩阵,其中`p`是状态的数量。例如,`1到1`表示在单个马尔科夫链中,当前状态与下一状态之间直接转移的概率。
3. **观测概率**:
`B`表示观测序列与状态之间的概率,即在每个状态`Si`下观测到观测值`Oj`的概率,用`bjl`表示。在传统方法中,这些概率通常使用高斯混合模型(GMM)进行估计。
HMM面临三个主要问题:
1. **识别问题**:
给定一个观测序列和HMM模型(`A`和`B`),求解最可能的状态序列。这通常通过维特比算法(Viterbi Algorithm)解决,找到使得观测序列概率最大的状态路径。
2. **训练问题**:
在给定观测序列的情况下,估计HMM的参数(初始状态概率`π`,状态转移矩阵`A`和观测概率`B`)。常用的方法包括Baum-Welch算法,它是一种基于期望最大化(EM)算法的迭代方法。
3. **解码问题**:
给定一个观测序列和已知的HMM模型,找到最有可能生成该观测序列的状态序列。这可以通过维特比算法实现,找出具有最高概率的路径。
在HMM中,`at`表示在时刻`t`观察到观测值`O`时,状态`S`处于状态`Si`的概率。`lik`或`Li`表示在已知观测序列和模型参数下,观测序列出现的概率。`al`和`bj`分别对应于状态转移和观测概率中的元素。
维特比算法(Viterbi Algorithm)是解决HMM中解码问题的一种高效方法,通过动态规划计算出每个时刻每个状态的最大概率路径,并记录路径来源。
对于训练问题,HMM的训练包括初始化模型参数(如随机化`A`)、计算概率(如`pcq`表示从状态`q`转移到状态`Si`的概率)以及更新参数以优化模型,使得观测序列的似然性最大化。
隐含马尔科夫模型是一种强大的工具,能够处理隐藏状态和观测序列之间的关系,广泛应用于语音识别、文本分析等场景。通过理解和应用HMM的这些核心概念,我们可以解决序列数据中的许多复杂问题。







评论0
最新资源