数据科学——电影数据集关联度分析1
需积分: 0 61 浏览量
2022-08-03
15:33:05
上传
评论
收藏 354KB PDF 举报


利用 FP-Growth 算法对“电影推荐数据集”进行处理,给出处理结果,给出结
论描述。
电影数据集关联度分析
胡成成——41724260——通信 1701
随着时代的变迁,科技的发展,看电影也成了人们生活的一部分。该篇报
告对 2017 年之前的上映过的电影及其分类的数据集进行处理,旨在通过关联度
分析对电影的一些类别联系进行研究,并对各类电影类别占比分析,对未来电
影上映类别的预测。现在通过 FP-Growth 算法对这样的数据进行分析,通过支
持度和置信度得到关联规则,通过对关联规则的分析处理得到我们要的结论。
并在对电影数据集的处理中,通过实际操作处理,实践学习 FP-Growth 算法的
关联度处理过程以及一般的流程。
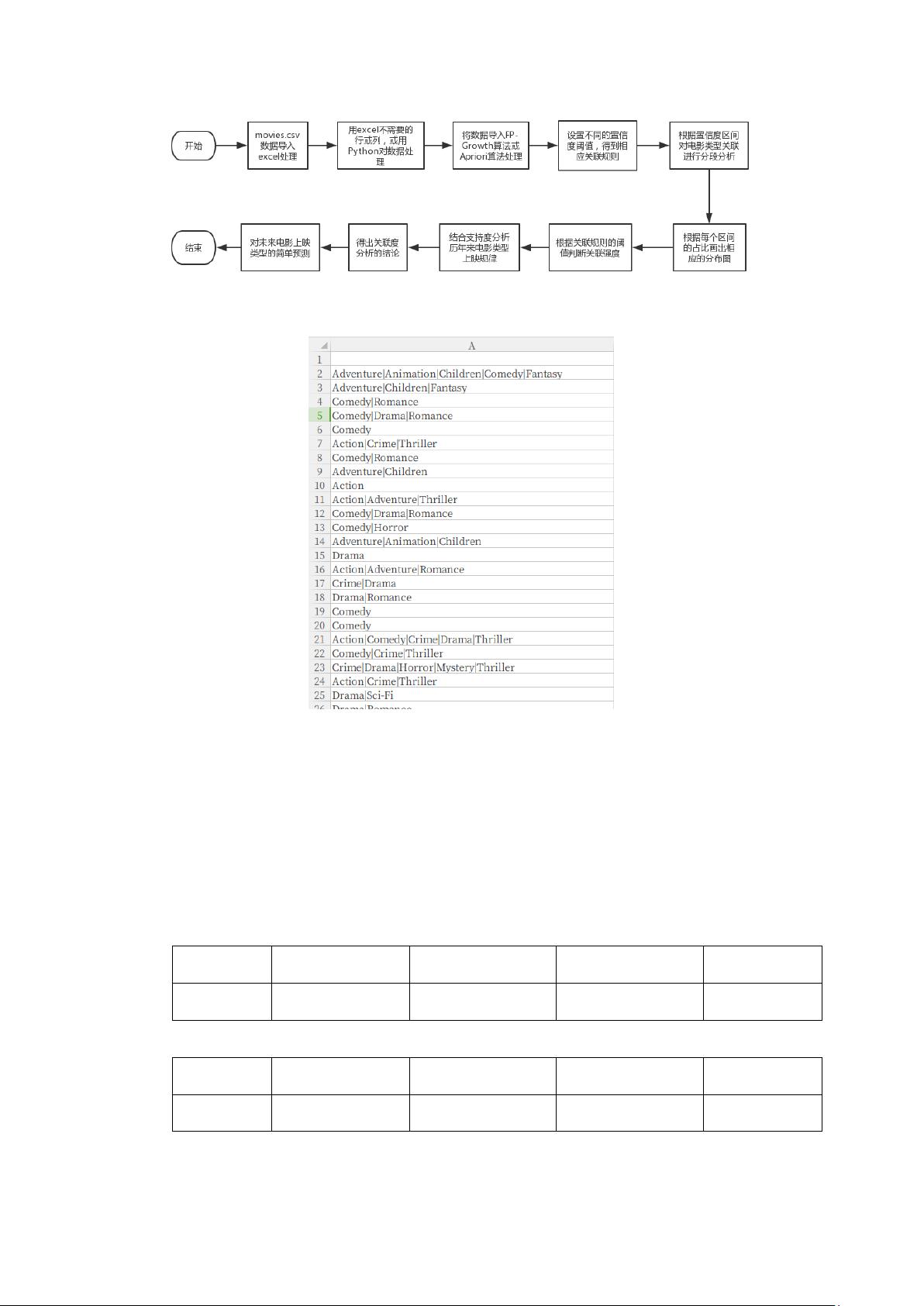
1.数据集引入分析:
第一列:电影的 id 编号,第二列,电影名称及其年份,第三列,电影所属
的类别:包括 Adventure(冒险),Animation(动画),Children(儿童),Comedy
(喜剧),Fantasy(幻想)等等类型。数据一共 9125 条。
2.数据分析流程

剩余12页未读,继续阅读













评论0