zhuxingk#Python-100-Days-1#40.大数据平台和HiveSQL1
需积分: 0 192 浏览量
2022-07-25
14:35:41
上传
评论
收藏 6KB MD 举报

## Hive简介
Hive是Facebook开源的一款基于Hadoop的数据仓库工具,是目前应用最广泛的大数据处理解决方案,它能将SQL查询转变为 MapReduce(Google提出的一个软件架构,用于大规模数据集的并行运算)任务,对SQL提供了完美的支持,能够非常方便的实现大数据统计。
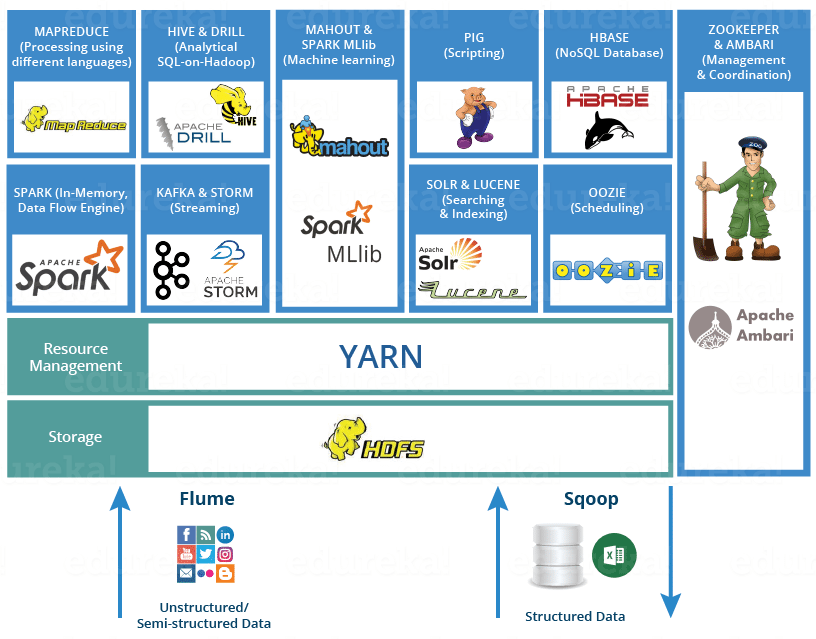 > **说明**:可以通过
> **说明**:可以通过来了解Hadoop生态圈。
如果要简单的介绍Hive,那么以下两点是其核心:
1. 把HDFS中结构化的数据映射成表。
2. 通过把Hive-SQL进行解析和转换,最终生成一系列基于Hadoop的MapReduce任务/Spark任务,通过执行这些任务完成对数据的处理。也就是说,即便不学习Java、Scala这样的编程语言,一样可以实现对数据的处理。
Hive和传统关系型数据库的对比如下表所示。
| | Hive | RDBMS |
| -------- | ----------------- | ------------ |
| 查询语言 | HQL | SQL |
| 存储数据 | HDFS | 本地文件系统 |
| 执行方式 | MapReduce / Spark | Executor |
| 执行延迟 | 高 | 低 |
| 数据规模 | 大 | 小 |
### 准备工作
1. 搭建如下图所示的大数据平台。

2. 通过Client节点访问大数据平台。

3. 创建文件Hadoop的文件系统。
```Shell
hadoop fs -mkdir /data
hadoop fs -chmod g+w /data
```
4. 将准备好的数据文件拷贝到Hadoop文件系统中。
```Shell
hadoop fs -put /ho
> **说明**:可以通过点击阅读更多
资源评论













