
17.5.3(K-Means、PCA、异常检测)
K-Means聚类算法是常用的非监督学习聚类算法。
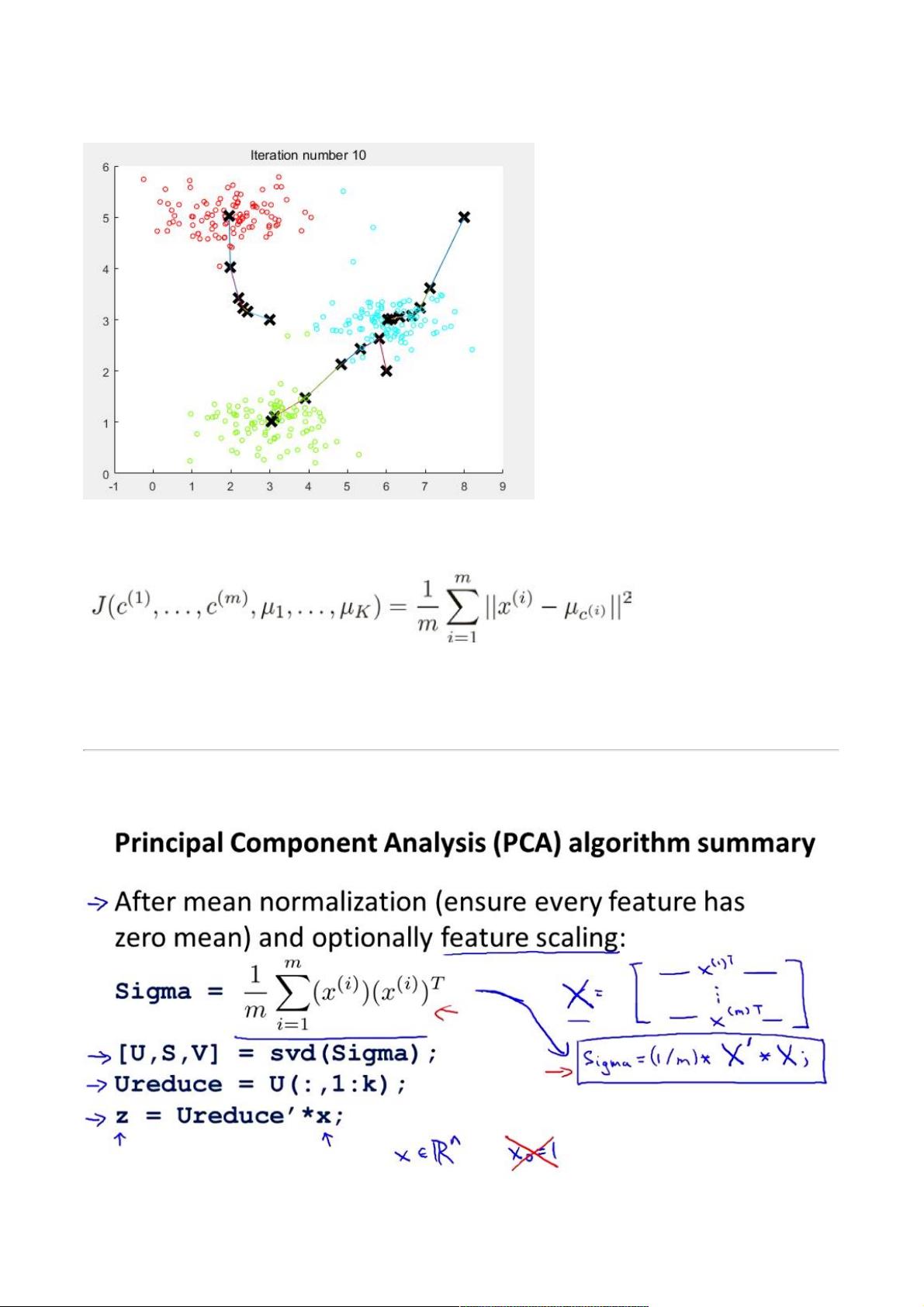
如上图所示:执行算法时,先初始化聚类数(簇的数量)和聚类中心,然后把每个样本进行分类,分好类求出当前类的平均值作为新的聚
类中心,然后再分类,再求聚类中心,直到求得的聚类中心不再变化。就是把我们的样本给聚类成功了。在初始化聚类中心的时候聚类中
心数要小于样本数,聚类中心可以随机从样本中获取。
K-Means算法的cost function如上,求得结果是所有样本到其聚类中心的距离之和。上面算法求得最后聚类中心就是最小化cost
function。
第二种非监督学习问题是降维,降维可以压缩数据,节省计算机运行内存,加快学习算法。还有助于将数据可视化。
Principal Component Analysis,主成分分析(PCA)是最常见的降维算法。
PCA算法,首先是要进行归一化处理,让每个特征的均值为0,然后用公式求sigma(协方差矩阵),然后用svd函数求sigma的特征向
量,我们是从n 维降到k 维,svd函数求得的U 是n*n维的矩阵,我们取n*k维,作为我们的新特征向量,然后用Ureduce(新特征向量)
的转置*X ,就得出最后的k * 1 维的特征结果。
PCA算法根据每个特征的权重大小,近似的丢掉一些特征。













评论0