

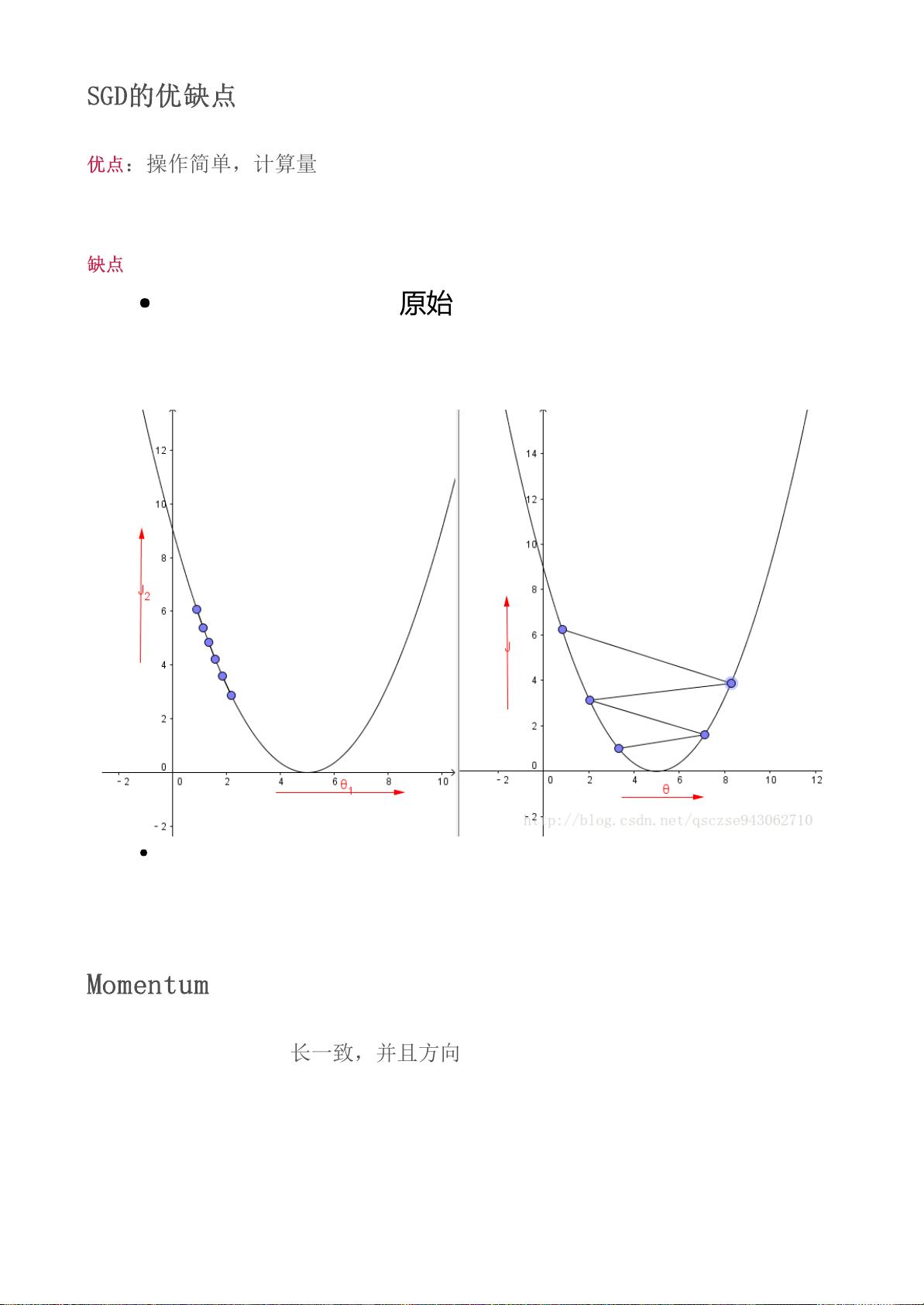
在机器学习中,有很多的问题并没有解析形式的解,或者有解析形式的解但
是计算量很大(譬如,超定问题的最小二乘解),对于此类问题,通常我们会选
择采用一种迭代的优化方式进行求解。
这些常用的优化算法包括:梯度下降法(Gradient Descent),共轭梯度法
(Conjugate Gradient),Momentum算法及其变体,牛顿法和拟牛顿法(包括L-
BFGS),AdaGrad,Adadelta,RMSprop,Adam及其变体,Nadam。
梯
度
下
降
法
(
Gradient Descent
)
想象你在一个山峰上,在不考虑其他因素的情况下,你要如何行走才能最快
的下到山脚?当然是选择最陡峭的地方,这也是梯度下降法的核心思想:它通过
每次在当前梯度方向(最陡峭的方向)向前“迈”一步,来逐渐逼近函数的最小
值。
在第n次迭代中,参数θn=θn−1+Δθ
我们将损失函数在θn−1处进行一阶泰勒展开:
L(θn)=L(θn−1+Δθ)≈L(θn−1)+L′(θn−1)Δθ
为了使L(θn)<L(θn−1),可取Δθ=−αL′(θn−1),即得到我们的梯度下降的
迭代公式:
θn:=θn−1−αL′(θn−1)
梯度下降法根据每次求解损失函数L带入的样本数,可以分为:
全
量
梯
度
下
降
(计算所有样本的损失)
,
批
量
梯
度
下
降
(每次计算一个batch样本的损失)
和
随
机
梯
度
下
降
(每次随机选取一个样本计算损失)。
PS:现在所说的SGD(随机梯度下降)多指Mini-batch-Gradient-Descent(批量
梯度下降),后文用gn来代替L′(θn)
剩余8页未读,继续阅读

型爷
- 粉丝: 24
- 资源: 337









最新资源
- 基于javaweb+Mysql 实现的卖鞋网站课程设计
- 【java毕业设计】在线环保网站源码(完整前后端+说明文档+LW).zip
- 业务安全渗透测试案例汇总.zip
- 【java毕业设计】供暖企业信息化报修平台源码(完整前后端+说明文档+LW).zip
- 一款适用于渗透测试、红队、src挖掘的弱口令生成工具.zip
- 【java毕业设计】个人网站管理系统源码(完整前后端+说明文档+LW).zip
- C++实现的三国杀桌面游戏代码解析
- C#大型药品进销存管理系统源码数据库 Access源码类型 WinForm
- student_distribution_map.html
- 【java毕业设计】个人理财管理系统源码(完整前后端+说明文档+LW).zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0