
Facebook Haystack
https://www.cnblogs.com/yuki-lau/archive/2013/03/29/2988594.html
http://www.importnew.com/3292.html 差不多就是 Haystack 的论文以及与
TFS 的比较
Facebook 每张照片平均 80KB,用户每周新增照片 10 亿,总大小 60TB,平
均每秒新增照片数为 3500 次,也就是每秒约 3500 次写操作,读操作峰值可达每
秒百万次。用户上传超过 65 billion 的图片,对每个上传的照片,Facebook 生成
和存储 4 种不同大小的图片,这就产生了超过 260 billion 张图片,超过 20 PB 的
数据(考虑副本情况,而且一张照片被存储为 4 种不同大小的)。
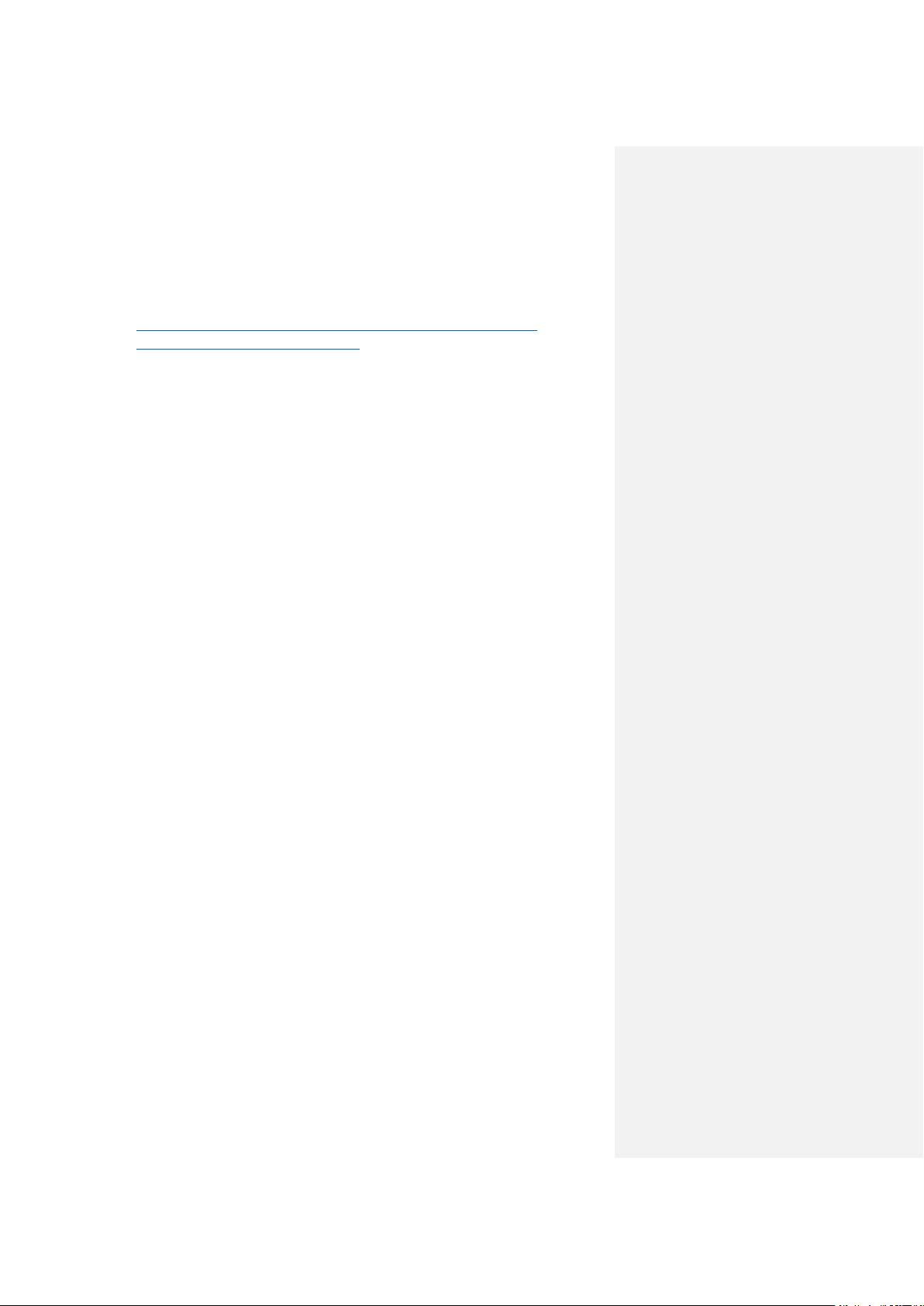
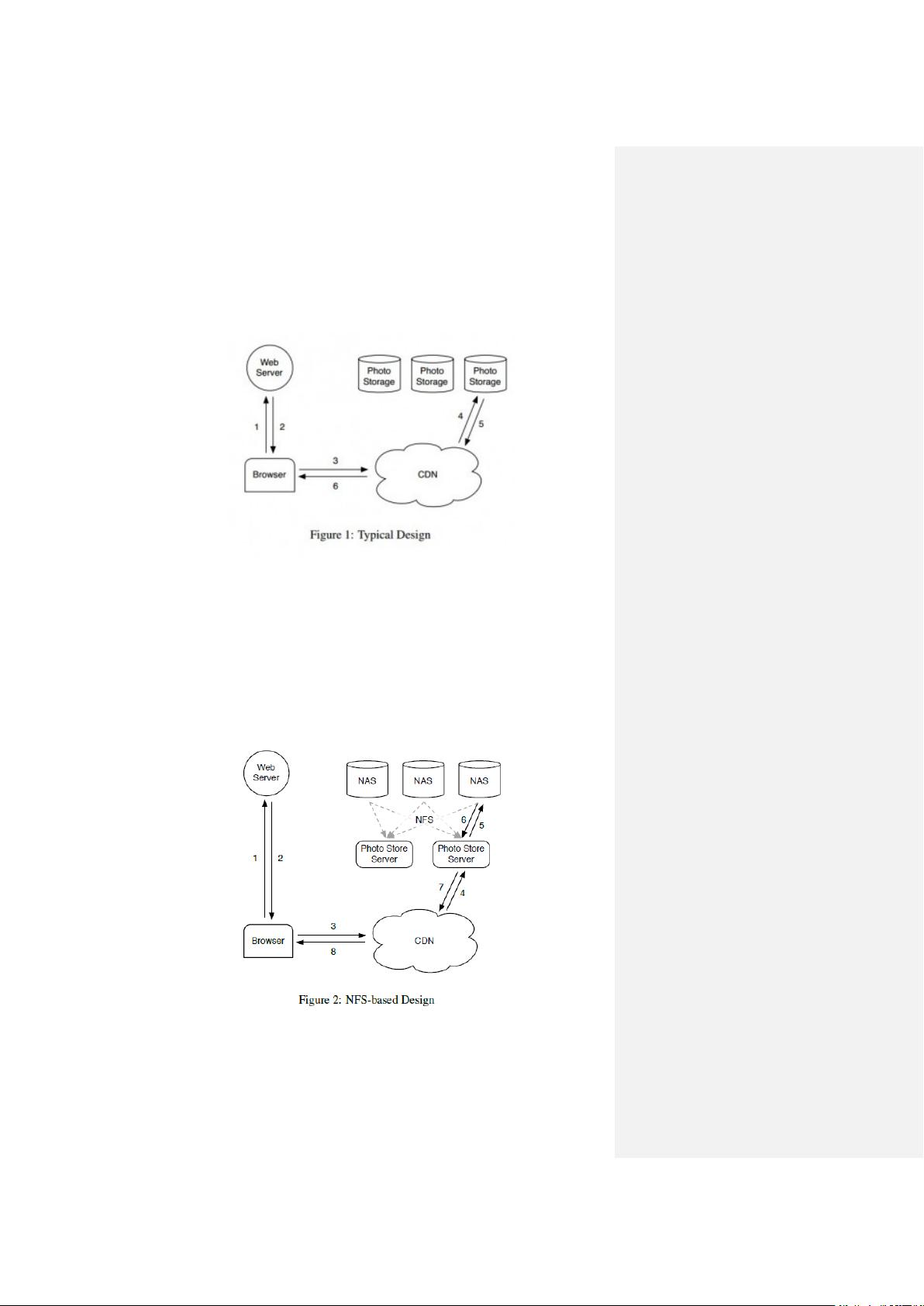
Facebook 最初采用的是 NAS(Network Attached Storage)和 NFS(Network File
System)存储图片,这种设计因为元数据查询而导致了过多的磁盘操作。所以要
竭尽全力的减少每个图片的元数据,让 Haystack 能在内存中执行所有的元数据
查询。这个突破让系统腾出了更多的性能来读取真实的数据,增加了整体的吞吐
量。
传统基于 POSIX 的文件系统的缺点主要是目录和每个文件的元数据。对于
图片应用,很多元数据(比如文件权限),是无用的而且浪费了很多存储容量。
而且更大的性能消耗在于文件的元数据必须从磁盘读到内存来定位文件。文件规
模较小时这些花费无关紧要,然而面对几百 billion 的图片和 PB 级别的数据,访
问元数据就是吞吐量瓶颈所在。
通常情况下,我们读取单个照片就需要好几个磁盘操作:一个(有时候更多)
转换文件名为 inode number,另一个从磁盘上读取 inode,最后一个读取文件本
身。简单来说,为了查询元数据使用磁盘 I/O 是限制吞吐量的重要因素。在实际
生产环境中,我们必须依赖内容分发网络来支撑主要的读取流量,即使如此,文
件元数据的大小和 I/O 同样对整体系统有很大影响。
Haystack 要实现高吞吐量和低延迟,满足海量用户的查询请求。通常超过处
理容量上限的请求,要么被忽略(对用户体验是不可接受的),要么被 CDN 处
理(成本昂贵而且可能遭遇一个性价比转折点)。想要用户体验好,图片查询必
须快速。Haystack 希望每个读操作至多需要一个磁盘操作,基于此才能达到高吞
吐量和低延迟。为了实现这个目标,我们竭尽全力的减少每个图片的必需元数据,
然后将所有的元数据保存在内存中。
存储场景
Haystack 的使用场景是:
1. write once, read often, never modified and rearly deleted;
2. 海量小文件。Facebook 存储了海量的图片文件;用户上传一张图片,
Facebook 会将其生产 4 种尺寸的图片,每种存储 3 份,因此写入量是用
户上传量的 12 倍(准确的说,由于尺寸的缩小,写入量不应该是 12 倍,
二是写入次数是 12 倍)。
剩余9页未读,继续阅读













评论0