决策树与随机森林1

需积分: 0 129 浏览量
更新于2022-08-08
收藏 40KB DOCX 举报
决策树是一种常用的数据挖掘工具,它利用树状结构来表示可能的决策路径和结果。在机器学习领域,决策树主要用于分类和回归问题。其基本思想是通过一系列规则的建立,将数据逐步划分到不同的类别中。决策树由根节点、内部节点(也称为决策节点)和叶节点组成。根节点代表了原始数据集,内部节点对应于某个特征或属性的测试,叶节点则代表最终的分类结果。
决策树的构建过程通常包括以下几个步骤:
1. **选择最佳分割属性**:在每个内部节点上,算法会寻找最优的属性来划分数据,这通常是基于某种信息增益或信息增益比的标准,如ID3算法使用信息熵,C4.5使用信息增益,CART则采用基尼指数。
2. **分割数据**:基于选定的属性,数据被分成若干子集,每个子集沿着对应的分支向下传递。
3. **递归构建子树**:递归地在每个子集上重复上述过程,直到满足停止条件(如达到预设的最小叶节点数,或所有样本属于同一类别等)。
4. **剪枝处理**:为了避免过拟合,决策树可能需要进行剪枝,即删除部分分支以简化模型。
随机森林是一种集成学习方法,它通过集成多棵决策树来提高预测性能。随机森林中的每棵树都是独立训练的,它们之间存在以下差异:
1. **样本重采样**:随机森林使用Bootstrap抽样法从原始数据集中创建训练集。每个训练集包含了与原始数据大小相等的随机样本,且允许重复抽样。
2. **属性随机选择**:在每个节点进行分裂时,不是考虑所有属性,而是从一个包含m个随机属性的子集中选取最优属性。这个m通常取属性总数的平方根,以增加随机性。
3. **投票决策**:随机森林中的每棵树都独立预测,最终的分类或回归结果是所有树预测结果的多数投票或平均值。
随机森林克服了单棵决策树的一些缺点,如过拟合和偏向于选择数值多的特征。由于每棵树只使用部分样本和属性,随机森林能降低模型的方差,提高泛化能力。同时,随机森林还具有很好的并行计算特性,可以快速处理大规模数据。
在MATLAB中,可以使用`TreeBagger`函数来实现随机森林模型的构建和训练。该函数提供了参数调整,如树的数量、属性选择方法等,以优化模型性能。
总结来说,决策树是通过递归地基于属性测试划分数据的模型,而随机森林则是通过集成多棵决策树并引入随机性来提高预测准确性和鲁棒性的方法。两者在分类和回归任务中都有广泛的应用,并在处理复杂数据集时表现出色。
决策树与随机森林
决策树原理
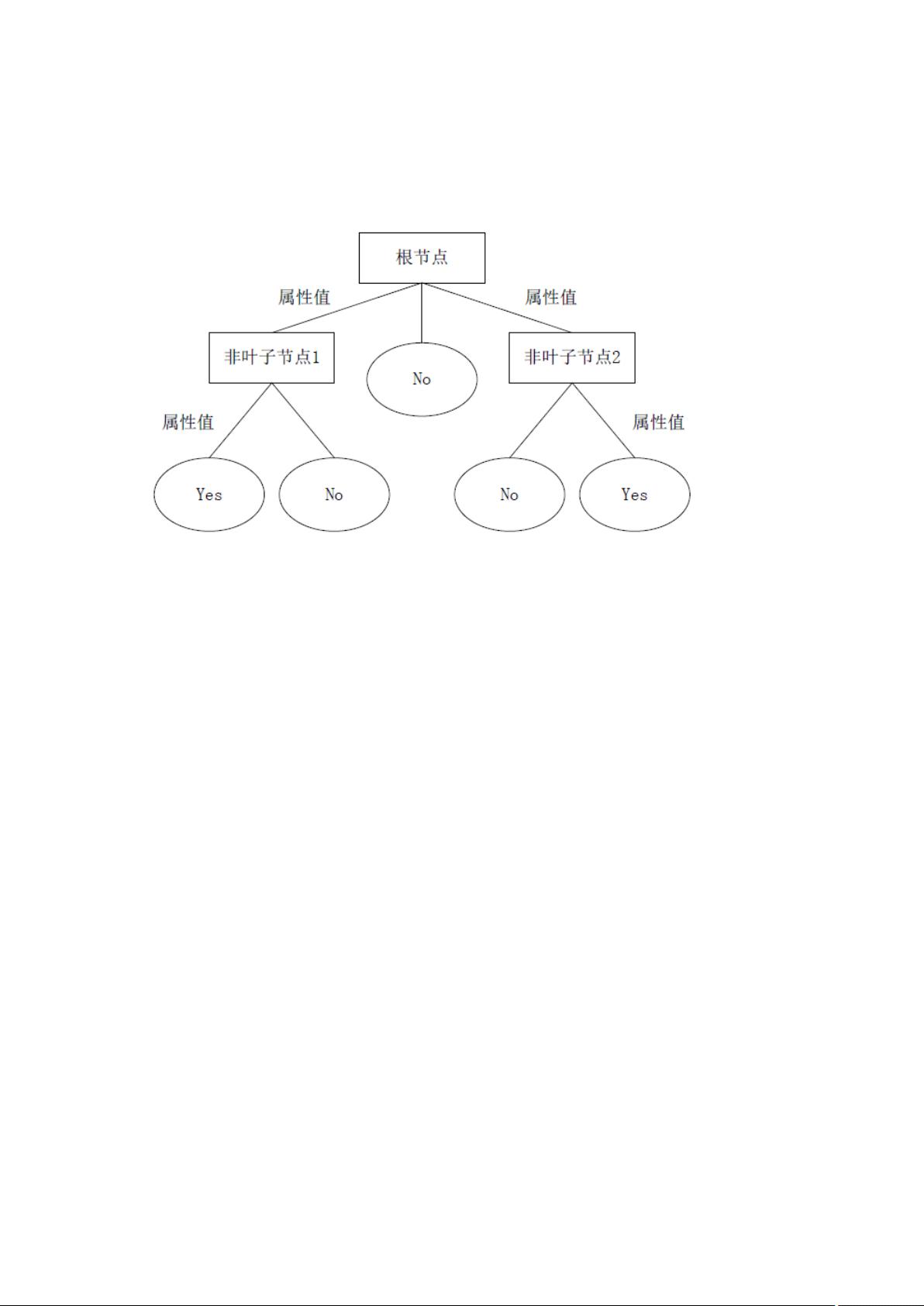
决策树通过把样本实例从根节点排列到某个叶子节点来对其进行分类。树上的每
个非叶子节点代表对一个属性取值的测试,其分支就代表测试的每个结果;而树上的
每个叶子节点均代表一个分类的类别,树的最高层节点是根节点。
决策树采用自顶向下的递归方式,从树的根节点开始,在它的内部节点上进行属
性值的测试比较。然后按照给定实例的属性值确定对应的分支,最后在决策树的叶子
节点得到结论。这个过程在以新的节点为根的子树上重复。
决策树的优点与缺点
优点:
决策树容易理解和实现。
对于决策树,数据的准备往往是比较简单或者是不必要的。其它技术往往要求先把数
据归一化,比如去掉多余的或者空白的属性。
能够同时处理数据型和常规型属性。其它的技术往往要求数据属性的单一。
是一个白盒模型。如果给定一个观察的模型,那么根据所产生的决策树很容易推出相
应的逻辑表达式。
缺点
下载后可阅读完整内容,剩余1页未读,立即下载
160 浏览量
177 浏览量
113 浏览量
198 浏览量
2019-03-01 上传
142 浏览量
2022-08-03 上传
资源评论


我就是月下
- 粉丝: 30
- 资源: 336









最新资源
- 被忽视的成本:中国城市扩张导致的生态系统服务损失从三耦合的角度来看
- 永磁同步电机PMSM参数辨识的粒子群优化算法实现流程解析与案例探索,基于粒子群优化算法的PMSM参数精准辨识与迭代更新策略,基于粒子群优化算法的永磁同步电机PMSM参数辨识 关键词:永磁同步电机 粒子
- 揭示城市扩张对植被碳的影响封存能力-以长江经济带为例(软件翻译)
- 双馈风电机组与同步发电机组四机两区域Simulink仿真建模及风光储联合调频与多种控制策略结合混合储能技术研究,双馈风电机组与同步发电机组四机两区域Simulink仿真建模及风光储联合调频控制策略,混
- 电气安装工 初级工.pdf
- 清华大学:普通人如何抓住DeepSeek红利
- Swift 编程语言的入门教程,适合零基础或有一定编程经验的读者快速上手
- 清华出品(104页)DeepSeek从入门到精通
- DeepSeek指导手册(24页)
- 研究机翼在不同速度下产生的噪音和性能表现
- JimuFlow RPA工具MacOS版v1.0.0
- MATLAB滚动轴承故障机理建模与仿真分析:基于ODE45的数值计算与多类型故障诊断预测研究,MATLAB轴承动力学模拟:滚动轴承故障机理建模与数值计算,多故障类型模拟及数据分析报告(含故障类型识别与
- 基于改进Relief算法的特征选取与关联向量机在短期负荷预测中的Matlab应用复现,基于改进Relief算法的特征选取与关联向量机在短期负荷预测中的实践(Matlab复现),相关向量机和特征选取技术
- COMSOL模拟技术揭秘:金属合金凝固过程及连铸工艺精确分析-相场流场与温度场的综合运用探究坯壳厚度计算,金属合金凝固与连铸过程数值模拟:相场流场温度场分析下的坯壳厚度计算,comsol数值模拟
- JimuFlow RPA工具Ubuntu版v1.0.0
- 煤层瓦斯渗透扩散与煤体孔隙裂隙二重介质特性研究-基于修正的P-M渗透率模型与气固耦合效应的模拟分析,煤层瓦斯渗透扩散的深部采煤模型研究:建立孔隙裂隙二重介质特性P-M渗透率模型与气固耦合模型的解析
