15-Hive统计1
需积分: 0 16 浏览量
2022-08-08
18:41:34
上传
评论
收藏 1.94MB DOCX 举报

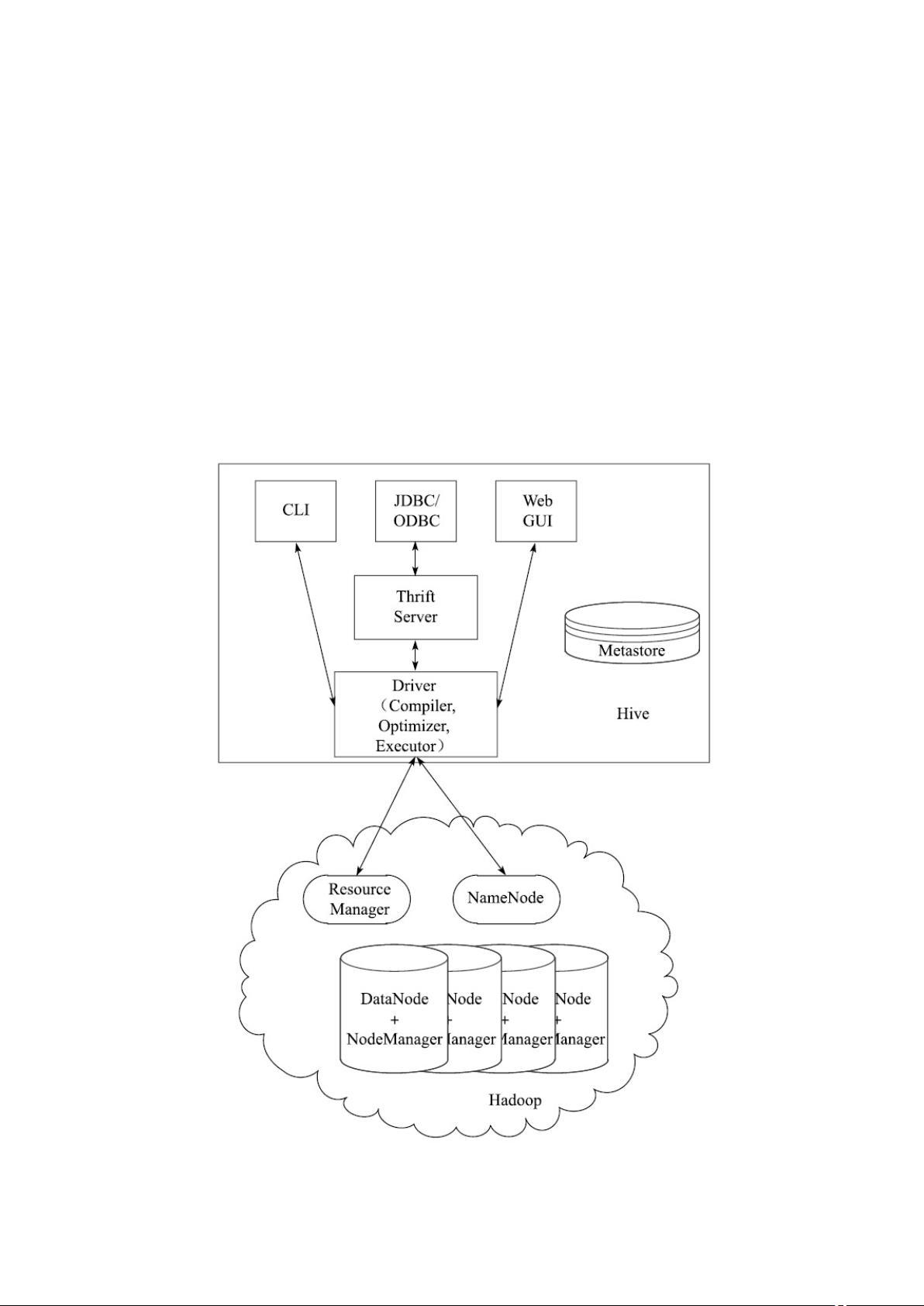
17. Hive 统计
一、基础概述
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,
并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运行。
其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开发专
门的 MapReduce 应用,十分适合数据仓库的统计分析。
Hive 构建在基于静态批处理的 Hadoop 之上,由于 Hadoop 通常都有较高的延迟并且在作业
提交和调度的时候需要大量的开销。因此,Hive 并不适合那些需要低延迟的应用,它最适
合应用在基于大量不可变数据的批处理作业,例如,网络日志分析。
Hive 的特点是:可伸缩(在 Hadoop 集群上动态的添加设备)、可扩展、容错、输出格式的
松散耦合。
Hive 将元数据存储在关系型数据库(RDBMS)中,比如 MySQL、Derby 中。


剩余17页未读,继续阅读
资源评论













