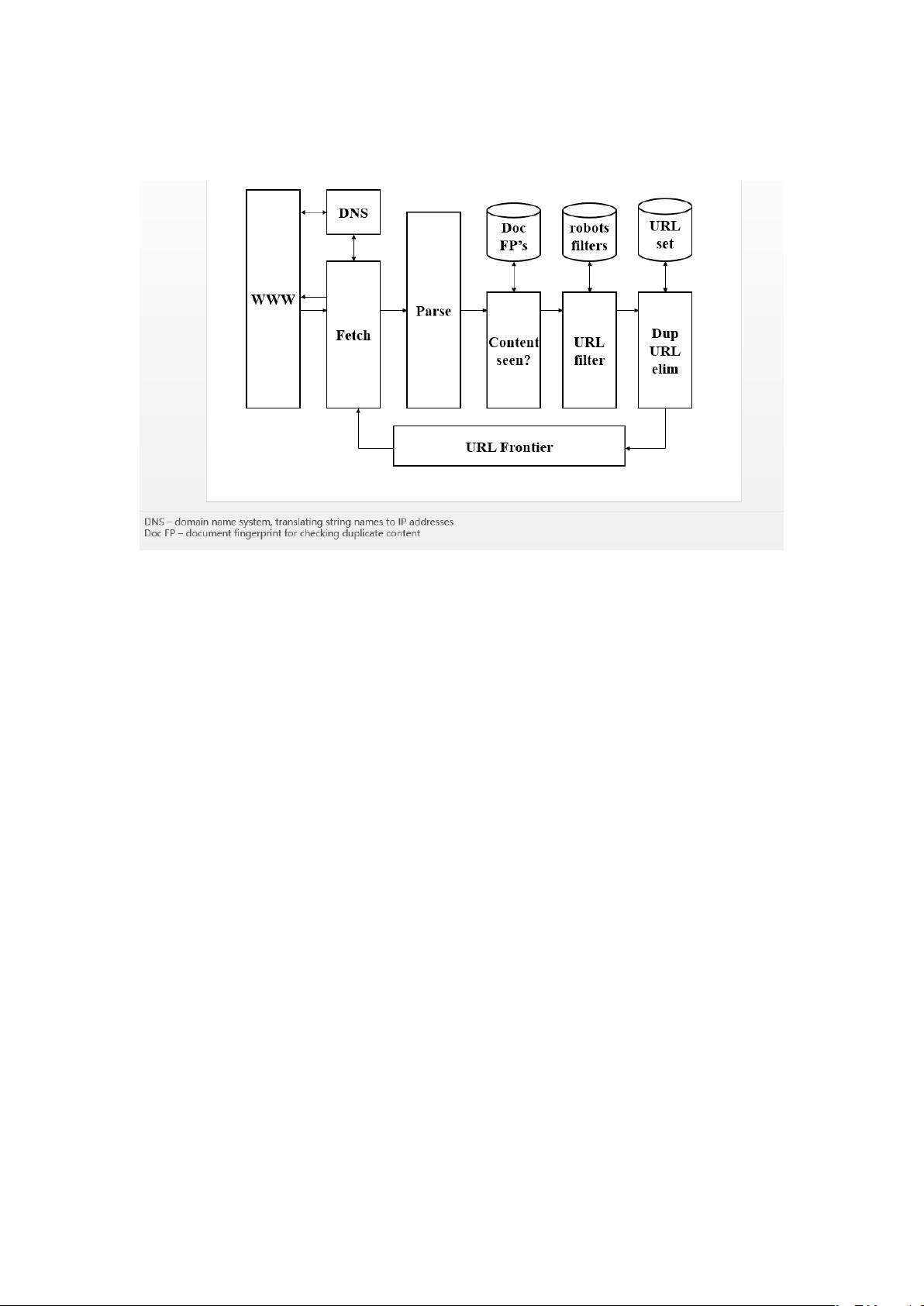
【爬虫守则详解】 爬虫,全称为网络爬虫,是一种自动抓取网页信息的程序,用于数据挖掘和分析。在使用爬虫时,必须遵循一定的规则,以确保网络的稳定运行和对网站的尊重。 1. **避免对网站造成DOS攻击**:分布式拒绝服务(DOS)攻击是指通过大量请求使服务器资源耗尽,导致正常用户无法访问。爬虫设计时要限制请求频率,避免短时间内发送过多请求。可以通过设置延时、限制同一IP地址的并发请求等方式避免对目标服务器造成压力。 2. **遵守robots.txt协议**:robots.txt文件是网站向爬虫提供的指导性文件,指示哪些部分允许或禁止爬取。在开始爬取前,应先读取该文件,按照其中的规则进行操作。例如: - `User-agent: webcrawler` 表示该规则适用于名为webcrawler的爬虫。 - `Disallow:` 表示允许所有爬虫访问。 - `Disallow: /` 表示禁止所有爬虫访问整个网站。 - `Disallow: /tmp` 表示除了`/tmp`目录外,其他地方都可以访问。 3. **处理Spider Traps**:爬虫陷阱是指网站设计用来捕获爬虫的机制,如动态URL、无限循环链接等。应对策略包括: - 对于动态URL,可尝试识别并统一处理。 - 遇到循环链接时,设定循环检测阈值,超过阈值则停止爬取。 4. **HTML元素中的URL识别**:爬虫需要识别并处理的URL可能隐藏在不同的HTML标签中,如`<a>`、`<option>`、`<area>`、`<frame>`、`<img>`等。同时,需处理相对路径与绝对路径,使用`<base>`标签设定基础URL。 5. **调度策略**:根据网站重要性和更新频率制定合理的爬取策略,高排名的网页应更频繁地刷新,但也要避免对服务器造成过大负担。 6. **DNS优化**:DNS查询是爬虫性能瓶颈之一,可使用缓存DNS解析结果或预加载DNS记录来提高效率。 7. **动态设置User-Agent**:为了避免被识别为爬虫,可以定期更换或随机设置User-Agent,模拟不同浏览器或设备的请求。 8. **禁用Cookie**:某些网站通过Cookie识别爬虫,禁用Cookie能降低被识别的风险。 9. **延迟下载**:在访问页面后等待一段时间再下载资源,减少对服务器的冲击。 10. **处理登录和Cookie**:如果网站需要登录,而某些页面只需Cookie即可访问,可以模拟登录获取Cookie后再进行爬取。 11. **编程语言的选择**:Java、Python和C++是常见的爬虫开发语言。Java解析能力强,适合复杂网页处理;Python网络功能强大,适合模拟登陆和解析JavaScript;C++适合处理大规模数据,但解析能力较弱。Scrapy是Python中的知名爬虫框架,Nutch是Java的开源爬虫项目。 爬虫开发需兼顾效率、合法性和礼貌,理解并遵守这些原则能够构建出高效且负责任的爬虫系统。
本内容试读结束,登录后可阅读更多
下载后可阅读完整内容,剩余6页未读,立即下载







评论0
最新资源