类 类的功能
ensemble.AdaBoostClassifier AdaBoost分类
ensemble.AdaBoostRegressor Adaboost回归
ensemble.BaggingClassifier 装袋分类器
ensemble.BaggingRegressor 装袋回归器
ensemble.ExtraTreesClassifier Extra-trees分类(超树,极端随机树)
ensemble.ExtraTreesRegressor Extra-trees回归
ensemble.GradientBoostingClassifier 梯度提升分类
ensemble.GradientBoostingRegressor 梯度提升回归
ensemble.IsolationForest 隔离森林
ensemble.RandomForestClassifier 随机森林分类
ensemble.RandomForestRegressor 随机森林回归
ensemble.RandomTreesEmbedding 完全随机树的集成
ensemble.VotingClassifier 用于不合适估算器的软投票/多数规则分类器
集成算法中,有一半以上都是树的集成模型,可以想见决策树在集成中必定是有很好的效果。在这堂课中,我们会
以随机森林为例,慢慢为大家揭开集成算法的神秘面纱。
复习:sklearn中的决策树
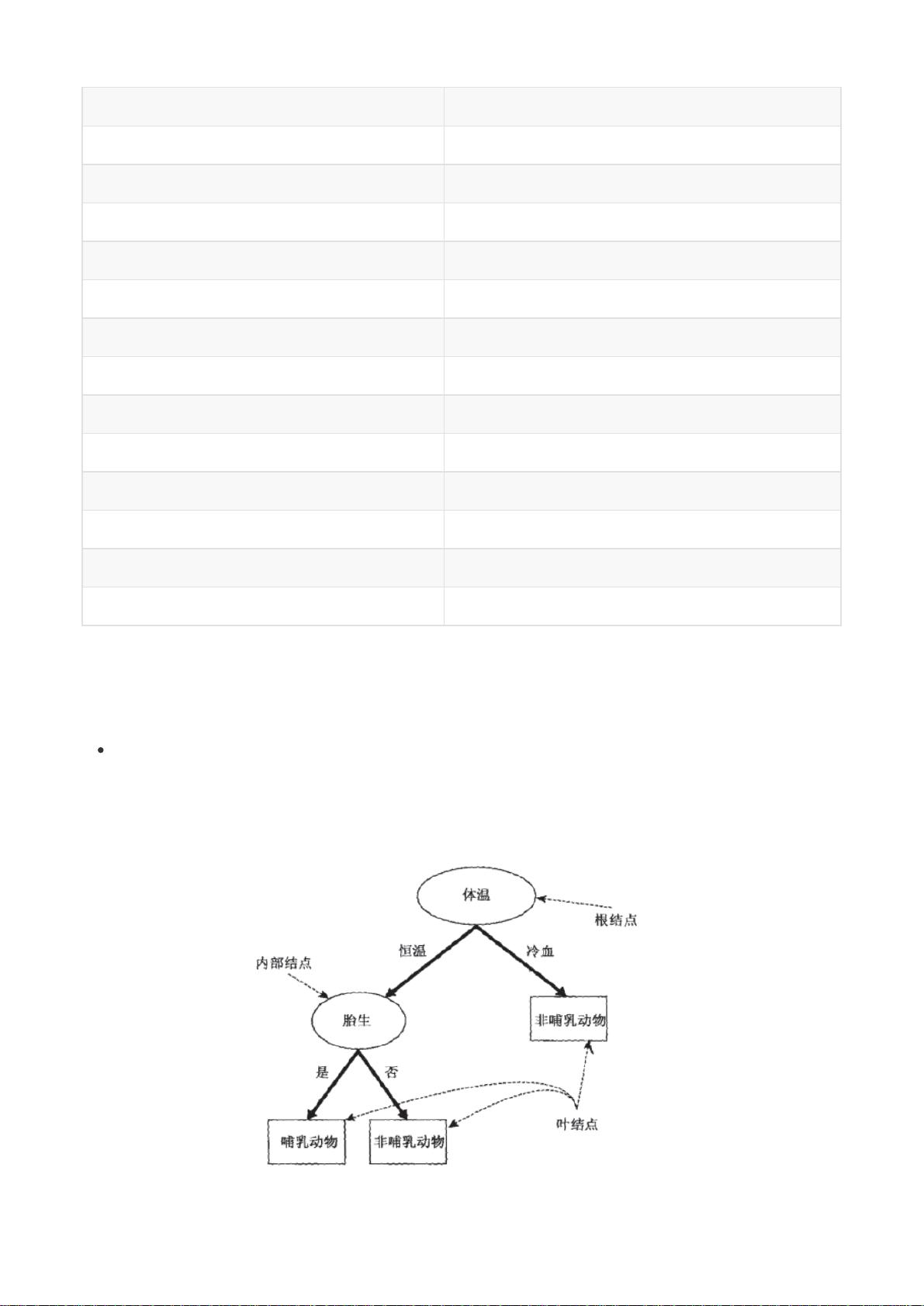
在开始随机森林之前,我们先复习一下决策树。决策树是一种原理简单,应用广泛的模型,它可以同时被用于分类
和回归问题。决策树的主要功能是从一张有特征和标签的表格中,通过对特定特征进行提问,为我们总结出一系列
决策规则,并用树状图来呈现这些决策规则。
菜菜的sklearn课堂直播间: https://live.bilibili.com/12582510


















评论0