
一、爬取内容选择:
预爬取网站:
新浪微博、豆瓣、贴吧、知乎、CSDN、科学网、领英、小木虫、人人、QQ 空间
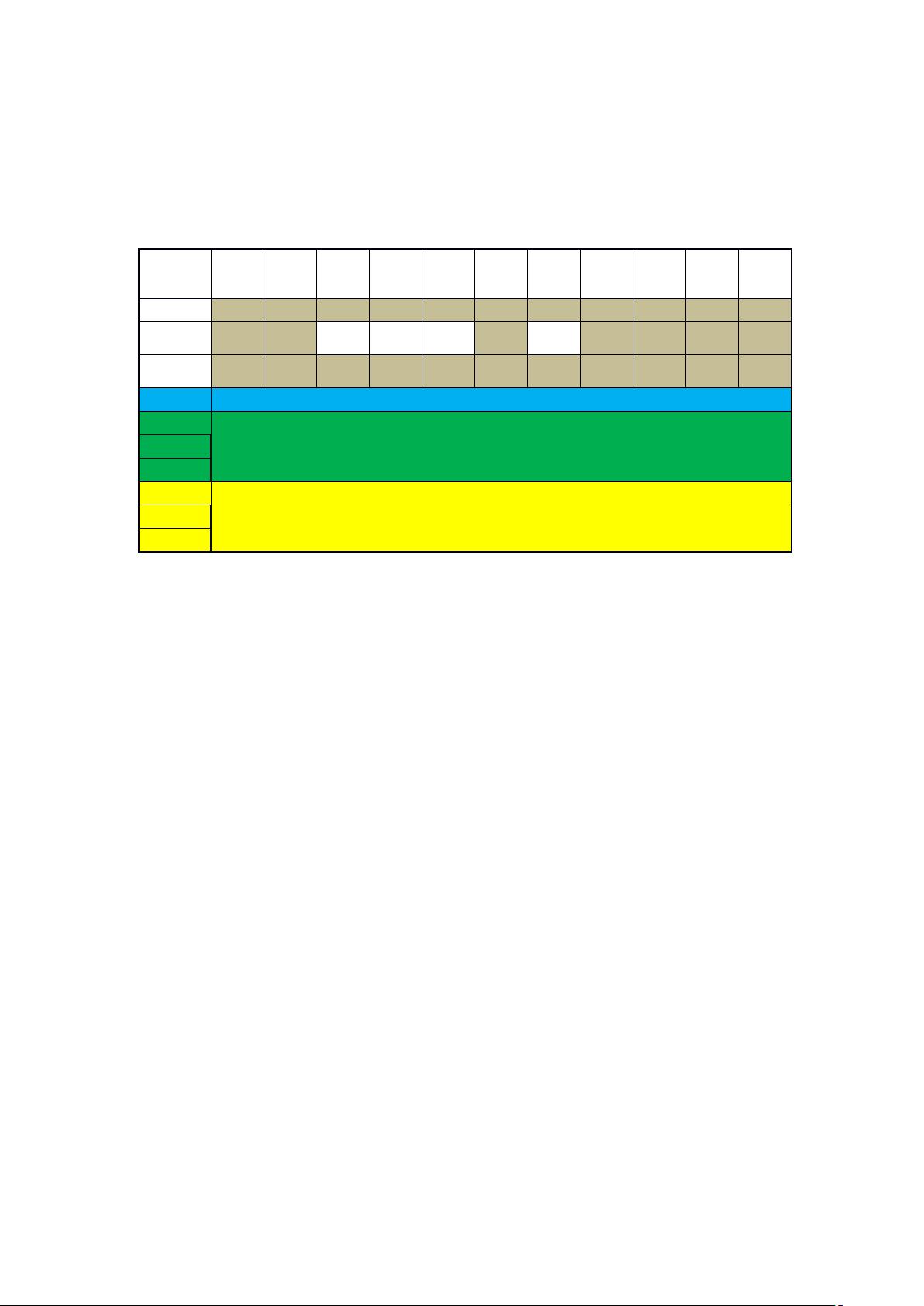
【1】唯一标识码【2】昵称【3】性别年龄/生日【4】地点【5】教育/工作【6】头像【7】
简介【8】关注列表【9】被关注列表【10】发布内容【11】标签【12】其他
唯一
标识
昵称
性别
年龄
生日
教育
工作
头像
简介
关注
列表
粉丝
列表
发布
内容
标签
新浪微博
ID 号
豆瓣
字符
串
知乎
字符
串
贴吧
访问需要登陆账号,只能查看非隐藏动态,而大部分人都选择隐藏。
领英
人人
QQ 空间
访问需要权限,必须加好友之后才能访问网页内容,不能大规模爬取。
科学网
小木虫
CSDN
访问需要登陆账号,发布内容多数都是长篇博客,标签化的信息不多。
1. 人人网,QQ 空间,领英
访问需要权限,必须加好友之后才能访问网页内容,不能大规模爬取。
2. 百度用户(贴吧)
访问需要登陆账号,只能查看非隐藏动态,而大部分人都选择隐藏,可爬取内容不多。
3. 博客类(如 CSDN)
访问需要登陆账号,【10】发布内容多数都是长篇博客,标签化的信息不多。
4. 豆瓣
【1】ID 号或者字符串
【2】【6】
【8】【9】能从这两个列表获得所有好友的 ID 号
【10】广播,一个豆瓣活动的日志,也有一些类似微博的短消息
【11】豆瓣小组,类似标签
【12】有大量的“喜欢”内容,如书、电影、音乐
5. 微博
【1】ID 号
【2】【3】【4】【5】【6】【7】
【8】【9】能从这两个列表获得所有好友的 ID 号
【10】微博,可判别哪些是热门微博
【11】从微博给出的选择
6. 知乎
【1】知乎指定唯一 ID 字符串
【2】【3】【4】【5】【6】【7】
【8】【9】能从这两个列表获得所有好友的 ID 号
【10】提问、回答,可以提取回答的内容
【11】关注了话题作为标签,以及设置自己擅长
【12】有部分人已经和微博进行关联,可作为测试集

剩余8页未读,继续阅读













评论0