

情报学报 2018 年 9 月 第 37 卷 第 9 期
Journal of the China Society for Scientific and Technical Information, Sep. 2018, 37(9): 939-955
收稿日期:2017-11-02;修回日期:2018-08-16
基金项目:国家自然科学基金“支持技术预见的多源异构大数据融合与时序文本预测方法研究”(91646102);国家自然科学基金“面向 2035
的中国工程科技发展路线图绘制理论与方法研究”(L1624045);国家自然科学基金“面向 2035 的中国工程科技发展路线图应
用案例及软件研究”(L1624041);国家自然科学基金“2035 发展战略文献计量与专利分析方法研究”(L1524015);教育部人文
社会科学项目(16JDGC011);清华大学绿色经济与可持续发展研究中心研究子项目(20153000181)。
作者简介:周源,男,1977 年生,博士,副教授,博士生导师;刘宇飞,男,1987 年生,博士后,E-mail: liuyufei0418@qq.com;薛澜,
男,1959 年生,博士,教授,博士生导师。
DOI: 10.3772/j.issn.1000-0135.2018.09.008
一种基于机器学习的新兴技术识别方法:
以机器人技术为例
周 源
1
,刘宇飞
2
,薛 澜
1
(1. 清华大学公共管理学院,北京 100084;2. 中国工程院战略咨询中心,北京 100036)
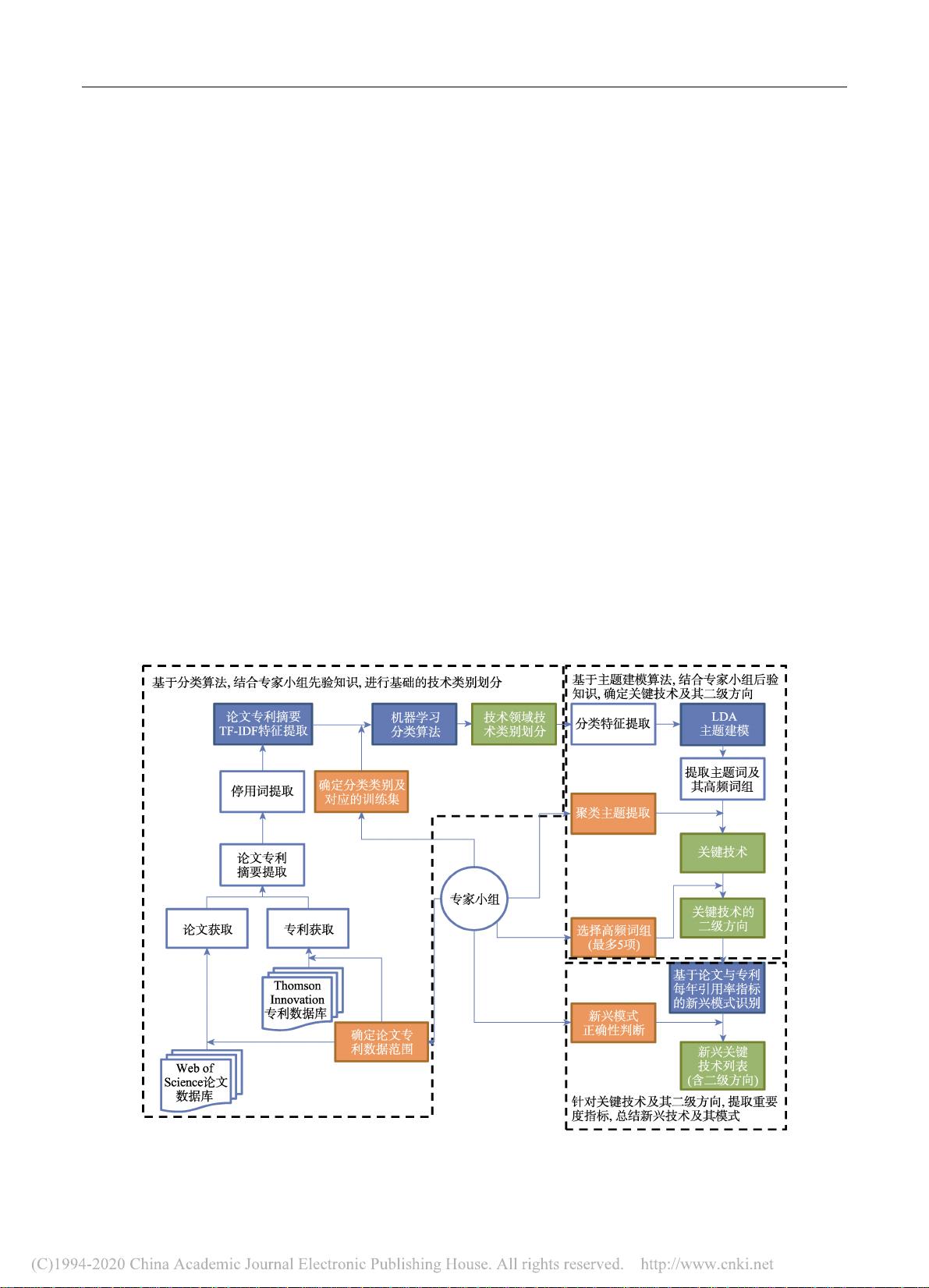
摘 要 基于文献数据帮助技术预见研究提高其信度和效度,逐渐受到国内外预见方法学的关注。但是,传统文
献计量学无法高通量的处理数据,分析时未能考虑文献的语义信息,同时,无法有效的嵌入技术专家领域知识与
判断,使得适用性和有效性受到限制。因此,本文提出一种基于机器学习主题模型的新兴技术识别预见方法,通
过对技术领域全样本的论文与专利数据的高通量融合处理,挖掘论文与专利的语义信息,从而提高技术识别的全
面性与颗粒度一致性;在此基础上,将预见专家组的领域知识与判断,融入机器学习过程中,从而提高机器学习
的准确度与识别新兴技术的能力,同时,使用论文与专利每年引用率作为指标,分析技术领域下细分技术的潜在
新兴模式。本研究以机器人技术为例,提取 Web of Science(WoS)论文数据库和 Thomson Innovation(TI)专利
数据库的十余万全领域海量数据,识别出机器人领域的新兴技术簇群,并进一步甄别全新技术颠覆和跨领域技术
融合驱动等两种新兴技术出现模式,为新兴技术发展轨迹预见工作提供有益的支持。
关键词 主题模型;机器学习;新兴技术;机器人技术
An Approach to Identify Emerging Technologies Using
Machine Learning: A Case Study of Robotics
Zhou Yuan
1
, Liu Yufei
2
and Xue Lan
1
(1. School of Public Policy and Management, Tsinghua University, Beijing 100084;
2. The Center for Strategic Studies, Chinese Academy of Engineering, Beijing 100036)
Abstract: The traditional bibliometric method uses published articles and patents to improve the reliability and valid-
ity of technology foresight. It is a challenging task to extract information from massive datasets owing to limitations
posed by manual feature extraction and encoding of knowledge. In addition, the lack of professional expertise leads to
inefficient data analysis. In this work, we propose a disruptive technology foresight method based on topic model,
which can improve the comprehensiveness and ensure consistent granularity of technology foresight via high
throughput processing of massive text datasets. Further, the judgments of the expert group for the five key nodes of
the machine learning algorithm improve the recognition abilities of this disruptive technology. In this study, the ab-
stract, published time, and reference data in the Web of Science (WoS) and Thomson Innovation (TI) platforms are

剩余16页未读,继续阅读













评论0