Hive on Spark实施笔记1
需积分: 0 20 浏览量
2022-08-08
20:11:33
上传
评论
收藏 270KB DOCX 举报

Hive on Spark 实施笔记
一、 编译适合 Hive 的 Spark
a) 说明
Spark 为了支持从 Hive 中读取数据,所以有很多 Hive 中用到的 jar 包,而 Hive
中 Hive on spark 时会将 Spark 的 jar 包引入到 Hive 的运行环境,因此及其他原因会
有 jar 冲突。所以需要重新编译没有包含 Hive 相关模块的 Spark。
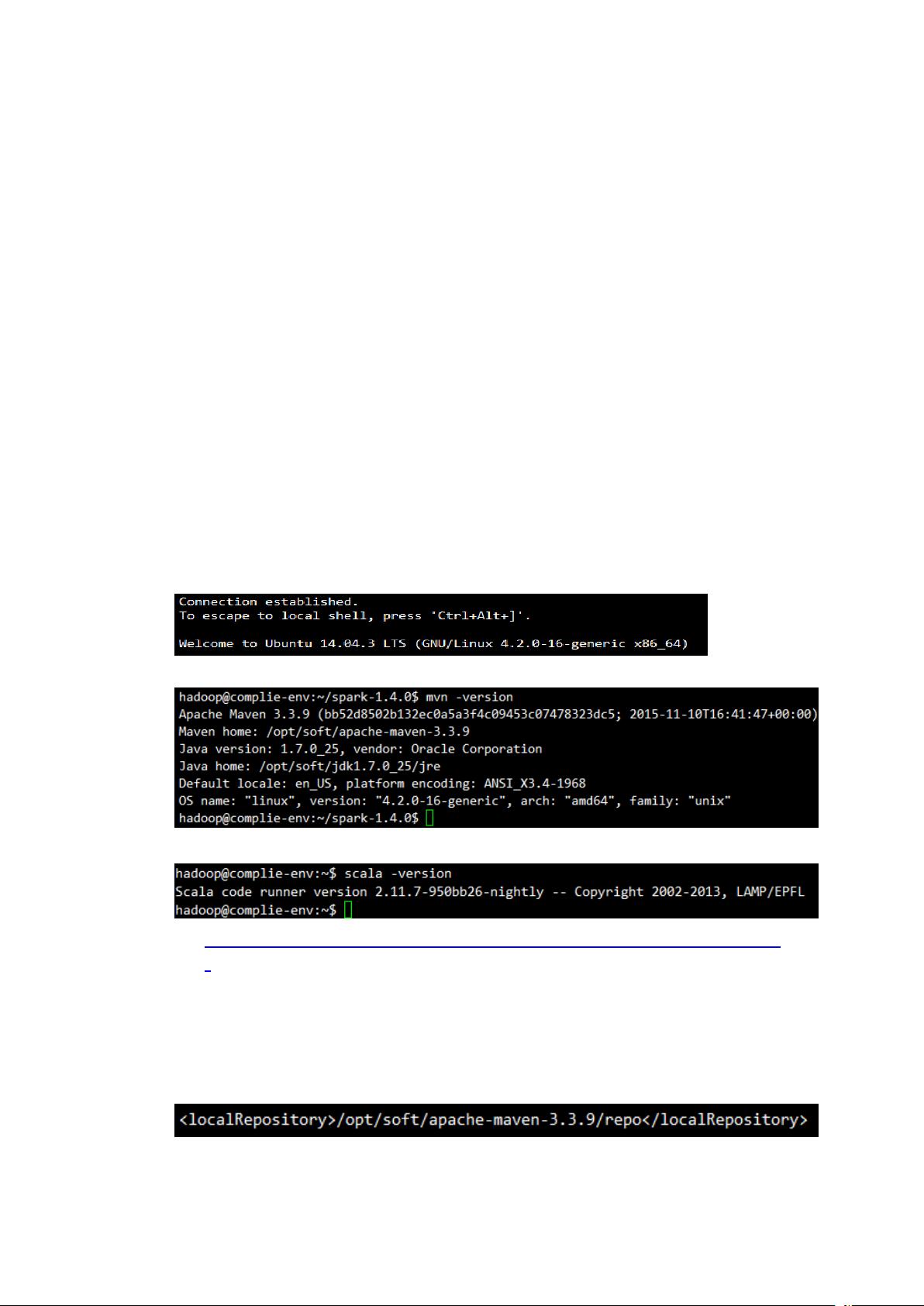
b) 编译环境
1. OS – Ubuntu 14.04
2. Maven
3. Scala (Spark 编译时有用到)
http://www.scala-lang.org/files/archive/nightly/2.11.x/scala-2.11.7-950bb26-nightly.tg
z
4. Hadoop2.6(已引入 HADOOP_HOME 环境变量)
5. 可访问外网(编译过程要联网下载)
6. 配置 maven 的国内镜像(编译过程会从国外下载较多文件,改国内 maven 库
镜像后编译过程大约需要 1 小时)
设置本地库路径:
镜像:

晕过前方
- 粉丝: 113
- 资源: 328









最新资源
- 基于matlab实现用有限元法计算电磁场的Matlab工具 .rar
- 基于matlab实现有限元算法 计算电磁场问题 边界条件包括第一类边界和第二类边界.rar
- 基于matlab实现用于计算不同车重下的电动汽车动力性和经济性.rar
- 基于matlab实现遗传算法求解多车场车辆路径问题 有多组算例可以用.rar
- 浏览器.apk
- 基于matlab实现是一个matlab中的power system 中搭建的一个模型
- 基于JSP毕业设计-教学管理系统(源代码+论文).zip
- 基于JSP毕业设计-家政管理系统-毕业设计.zip
- 基于Python实现淘宝商品评论采集(含逆向)源代码
- 基于matlab实现多目标进化算法NSGAⅡ&Matlab讲解.rar
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0