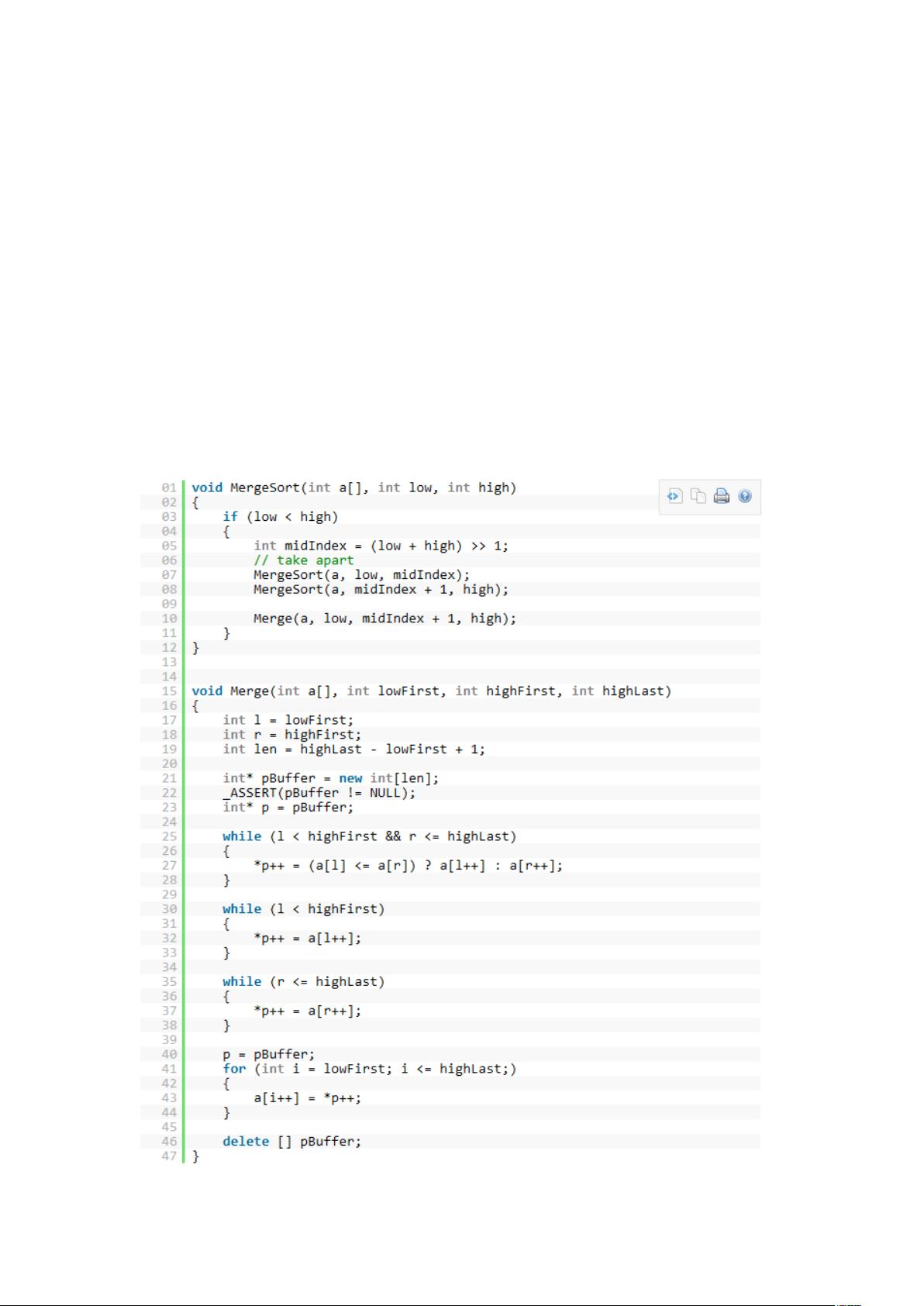
归并排序是一种高效的排序算法,基于分治策略,它的核心在于将大问题分解为小问题,然后逐个解决。在理论分析中,归并排序的平均时间复杂度和最坏情况时间复杂度都是 Θ(nlogn),这使得它在处理大数据集时表现稳定,特别是在可能出现快速排序退化的情况下。 然而,在实际应用中,归并排序的性能往往不如预期,其中一个主要原因在于它的内存管理策略。传统的归并排序在每次合并过程中都需要动态分配和释放内存来存储临时结果。这种频繁的内存分配和回收操作会带来显著的开销,尤其是在处理大型数据时。 为了提高归并排序的效率,我们可以考虑改变内存分配策略。一种优化方法是在排序开始前一次性分配一个大小为 n 的连续内存块,用于存放整个排序过程中的临时数据。这样,原本在每次合并时都需要执行的内存分配和回收操作就可以被避免,从而减少了内存管理的开销。 实施这个优化策略,我们需要在原始的归并排序函数之外添加一个驱动函数。驱动函数负责预分配内存,并在排序完成后释放内存。这样,所有的合并操作都可以在预先分配好的内存区域内进行,提高了效率。 为了验证这个优化的效果,可以对不同规模的数据进行测试。例如,可以选取100、1000、10000、100000等不同大小的数组,每组数据重复排序100次,收集运行时间数据。测试应在Release模式下进行,以减少调试相关的影响。通过比较优化前后的运行时间,可以发现优化后的归并排序通常能比原始版本快30到50倍。对于1000大小的数据,可能因为缓存命中率的提升,性能提升更为显著,一般也能达到30到40倍的速度提升。 总结来说,对于那些需要频繁分配内存的算法,如归并排序,采取一次性分配或延迟删除策略以提高内存复用,可以显著提升算法的运行效率。这种优化策略尤其适用于大数据量的排序场景,减少了因内存分配和回收带来的额外计算成本,使得归并排序在实际应用中更加高效。
本内容试读结束,登录后可阅读更多
下载后可阅读完整内容,剩余3页未读,立即下载
评论星级较低,若资源使用遇到问题可联系上传者,3个工作日内问题未解决可申请退款~