联邦学习隐私保护机制综述(原版)1
需积分: 0 112 浏览量
2022-08-08
21:26:45
上传
评论 1
收藏 258KB DOCX 举报


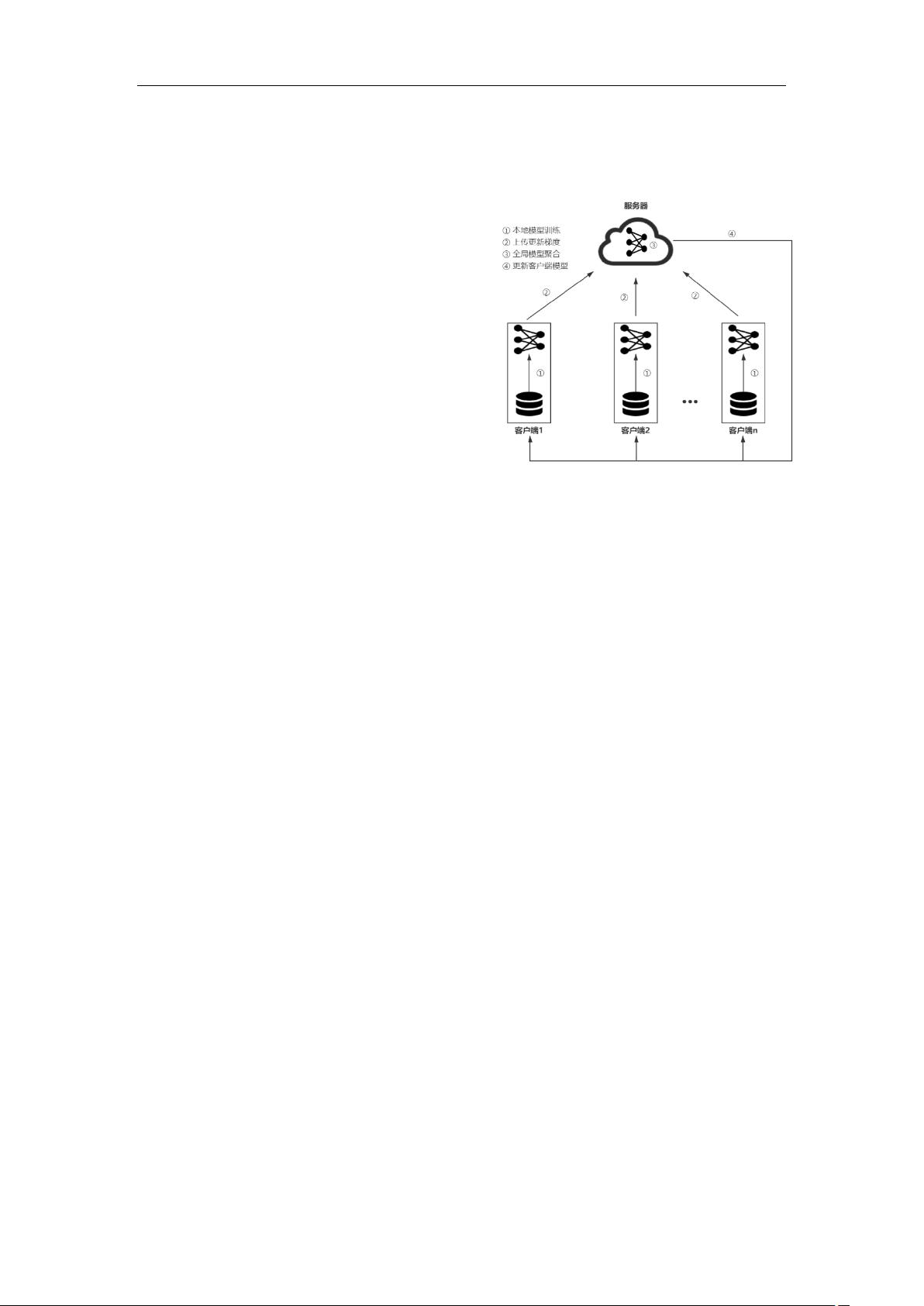
联邦学习隐私保护机制综述
摘要:随着数据孤岛的出现和隐私意识的增强,传统的中心化的机器学习模式遇到了
一系列挑战。联邦学习作为一种新兴的隐私保护的分布式机器学习模型迅速成为一个热门
的研究问题。有研究表明,机器学习模型的梯度会泄露用户数据集的隐私,能够被攻击者
利用以获取非法的利益,因此,需要采用一些隐私保护的机制来保护这种敏感信息。研究
了当前联邦学习系统中采用的隐私保护机制,并根据研究者们采用的隐私保护技术,将联
邦学习中的隐私保护机制主要分为了五类,总结了不同的隐私保护机制的研究思路和研究
进展。通过对当前联邦学习中使用的隐私保护机制的研究,联邦学习系统的设计人员提高
联邦学习系统的安全性,更好的保护数据隐私。
关键词:联邦学习;隐私保护;
Abstract:With the emergence of data islands and the enhancement of privacy awareness,
the traditional centralized machine learning model has encountered a series of challenges.
Federated learning, as a privacy-protected distributed machine learning model, has quickly
become a hot research topic. Studies have shown that the gradient of the machine learning model
will leak the privacy of user data sets and can be used by attackers to obtain illegal benefits.
Therefore, some privacy protection mechanisms are needed to protect this sensitive information.
We studies the privacy protection mechanisms used in the current federal learning system, and
according to the privacy protection technology adopted by the researchers, divides the privacy
protection mechanisms in the federal learning into five categories, and summarizes the ideas of
different privacy protection mechanisms. We want to introduce the current privacy protection
mechanisms used in federated learning to enable designers of federated systems to improve the
security of federated learning systems and protect data privacy.
Keywords:Federated Learning;privacy protection



剩余24页未读,继续阅读

黄涵奕
- 粉丝: 72
- 资源: 328









最新资源
- 微信小程序 - 同乐居商城:购物车合算源码
- 1、根据输入的三条边值判断能组成何种三角形,并设计测试数据进行判定覆盖测试 三条边为变量a、b、c,范围为1≤边值≤10,不在范
- SQL server 练习题目8道(小白教学).zip
- Python 手写实现 iD3 决策树算法-根据信息增益公式.zip
- 411675952289057车联助手-小窗版(三星)3.5.1.apk
- 三种快速排序方法合并在一个文件中以便直接运行的Python代码示例
- 937712277954201实习5.word
- 2程序语言基础知识pdf1_1716337722703.jpeg
- 简单的Python示例,演示了如何使用TCP/IP协议进行基本的客户端和服务器通信
- 考试.sql
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0