pdf项目框架说明文档1

需积分: 0 105 浏览量
更新于2022-08-08
收藏 241KB DOCX 举报
PDF 传输检测项目是一个针对学生在浏览或下载PDF时截取数据流进行匹配的系统。该系统基于Windows和Linux平台,采用了一系列跨平台的库和组件。以下是项目的详细知识点:
1. **PDF格式解析**:项目使用了xpdf库进行PDF格式的解析,能够读取并理解PDF文档的内容,包括文本、图像、元数据等。
2. **PDF特征提取与存储**:通过xpdf解析出的PDF信息被提取为关键特征,如标题、页数、ID、作者等,并利用MySQL数据库进行存储。这些特征经过哈希计算,便于后续的数据匹配。
3. **网络数据包的抓取**:利用libnids库捕获网络上的数据包,这在多线程下载场景下尤为重要,因为某些浏览器可能支持多线程下载PDF,需要处理多个并发的数据流。
4. **网络数据包的分析**:对捕获到的数据包进行TCP和HTTP协议的分析。TCP协议的重组用于恢复原始的数据流,而HTTP协议分析则用于识别PDF下载请求和响应。
5. **数据流中的PDF匹配**:在TCP数据流分析的基础上,使用xpdf对数据流进行PDF匹配,确保即使PDF被分割成多个数据包也能正确识别。
6. **多线程模型**:考虑到服务器可能面临大量数据流,项目采用了boost库来实现多线程处理,提高系统效率。
7. **TCP重组与IP分片包重组**:这是网络数据包分析的关键部分,确保即使PDF文件在传输过程中被分成多个IP分片,也能正确重组为完整的PDF。
8. **HTTP协议分析**:除了TCP数据流分析,还需要理解HTTP协议,以便识别PDF下载请求,这可能涉及处理HTTP头信息,如Content-Type和Content-Length。
9. **FTP协议分析**:虽然主要关注HTTP协议,但FTP也可能被用于PDF传输,因此项目可能也考虑了FTP协议的分析。
10. **PDF特征匹配**:使用计算的PDF特征(哈希值)进行匹配,当新的PDF数据流进入时,系统会比较这些特征,以确定是否与已知的PDF匹配。
11. **数据库表设计**:项目中涉及的数据库表包括pdf_description、pdf_hash、pdf_pre_hash等,用于存储PDF的描述信息、哈希值以及预哈希值,以支持高效的数据查询和匹配。
12. **编译与环境配置**:在Windows环境下,使用VS2005进行编译,Linux环境下需要安装MySQL、相关开发包并执行make命令。项目还修复了一些第三方库的bug,并依赖于boost(仅编译了date_time、thread、locale、filesystem库)和xpdf(需要freetype库支持并编译为静态库)。
13. **运行与配置**:安装winpcap(Windows),导入数据库sql文件,配置程序目录下的配置文件,如pdf_hit_detector.cfg和xpdfrc。程序有两种运行模式,无参数为监控模式,有参数为特征提取模式。
这个项目综合运用了网络协议分析、PDF解析、数据库管理、多线程编程和跨平台技术,构建了一个高效且适应性强的PDF数据流监测系统。
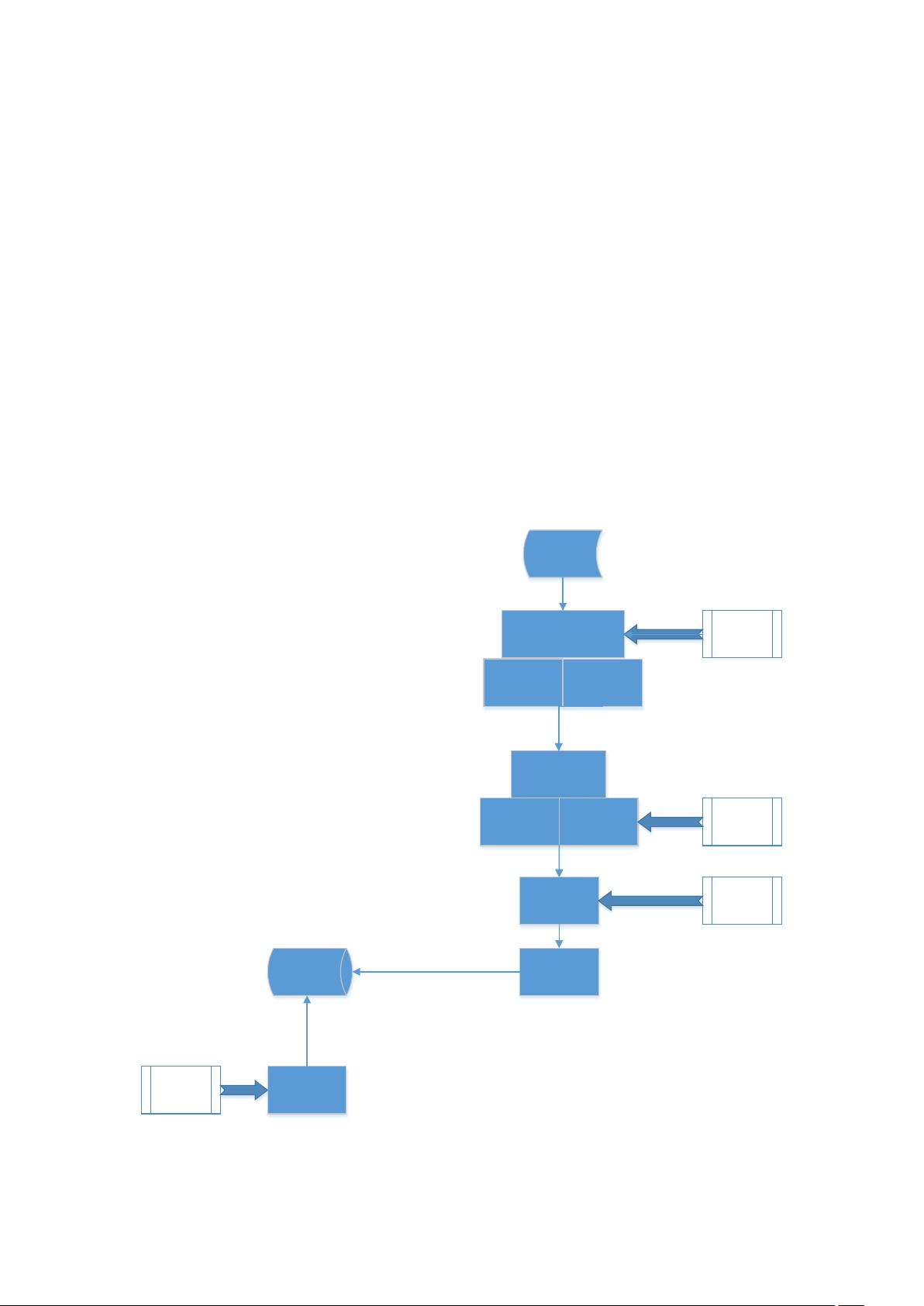
PDF 传输检测项目说明
主要模块已及相关解决方案
因为项目需适用于 Windows 和 Linux 2 个平台,所以选用了跨平台的库和组件
1. PDF 格式解析 ---------- xpdf
2. PDF 特征提取与存储 ---------- mysql
3. 网络数据包的抓取 ---------- libnids
4. 网络数据包的分析 ---------- TCP 协议的重组,Http 协议分析
5. 数据流中的 pdf 匹配 ---------- xpdf
6. 整体框架,多线程模型 ---------- boost
项目大体框架
Mysql
pdf信息提取
数据包抓取和重组
网络数据
TCP数据流分析
Http协议分析 FTP协议分析
Pdf格式匹配
Pdf特征匹配
IP分片包重组
TCP重组
Libnids
http_parser
Xpdf
Xpdf
下载后可阅读完整内容,剩余4页未读,立即下载
149 浏览量
2011-01-19 上传
197 浏览量
2017-11-09 上传
2023-06-06 上传
147 浏览量
155 浏览量
142 浏览量
118 浏览量
130 浏览量
2022-04-07 上传
181 浏览量
170 浏览量
2022-07-19 上传
2021-01-19 上传
138 浏览量
2019-06-25 上传
162 浏览量
146 浏览量
2019-09-23 上传
155 浏览量
2018-12-05 上传
176 浏览量
2022-06-13 上传
2019-03-25 上传
资源评论











