Ji_Learning_Temporal_Action_Proposals_With_Fewer_Labels_ICCV_201
需积分: 0 149 浏览量
2022-08-08
17:49:52
上传
评论
收藏 1.56MB DOCX 举报


使用较少的标签学习临时行动建议(Temporal Action Proposals)
摘要
时间行动建议是当今行动检测管道中的一个常见模块。 大多数当前训练动作提议模块
的方法都依赖于完全监督的方法,这些方法需要在长视频序列中使用大量带注释的时间动
作间隔。 这需要大量的注释成本和努力促使我们研究在较少监督的情况下训练提案模块的
问题。 在这项工作中,我们提出了一种专门为训练时间动作提议网络而设计的半监督学习
算法。 当只有少量标签可用时,我们的半监督方法比完全监督的对应物和其他强大的半监
督基线生成的提议要好得多。 我们在两个具有挑战性的动作检测视频数据集 ActivityNet
v1.3 和 THUMOS14 上验证了我们的方法。 我们表明,我们的半监督方法始终匹配或优于
完全监督的最先进方法。
1 介绍
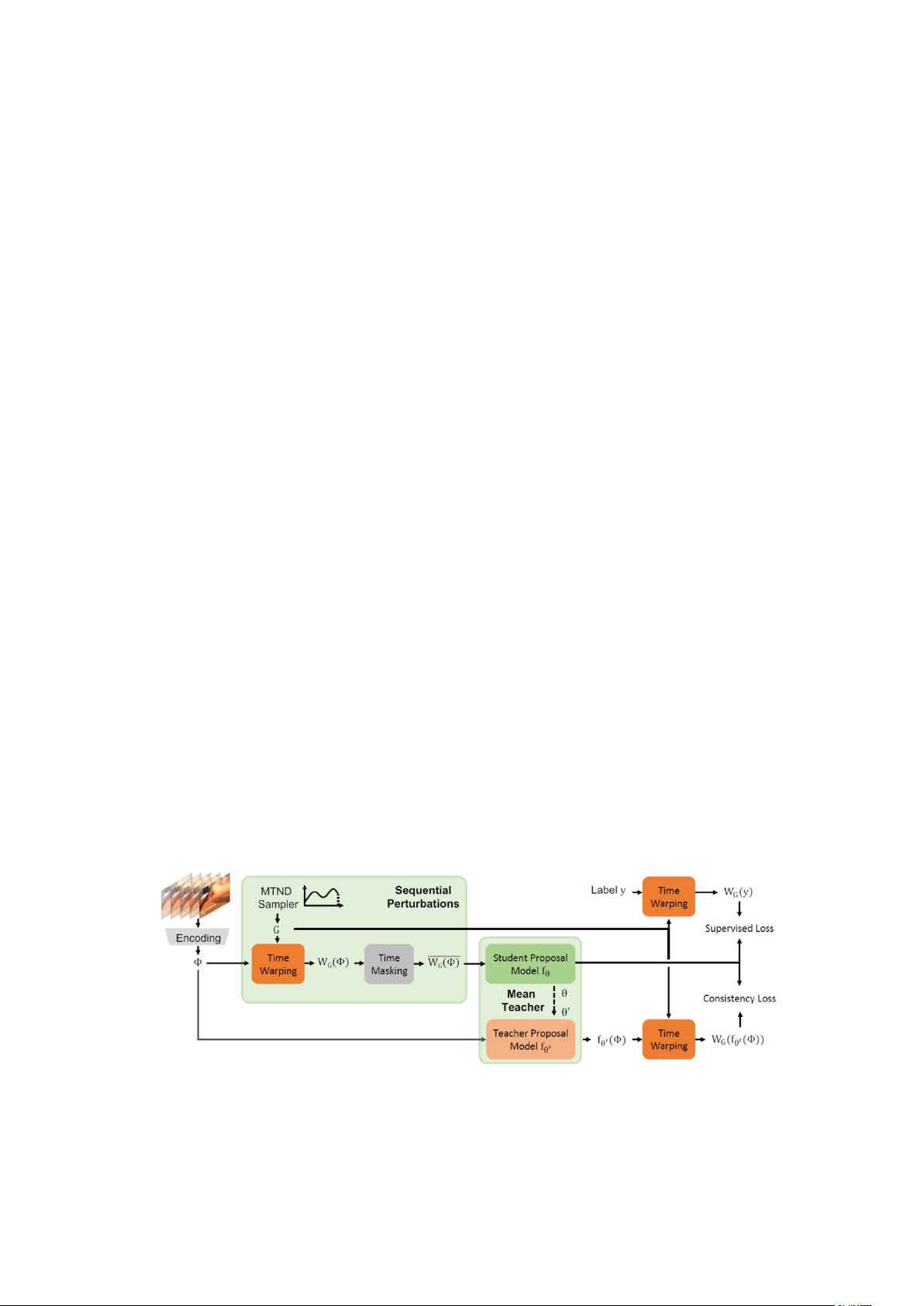
Figure1:我们的半监督框架只有部分训练视频标有基本事实建议,可以生成比最先进
的全监督方法质量更好的时间动作建议


剩余16页未读,继续阅读

优游的鱼
- 粉丝: 71
- 资源: 316












评论0