
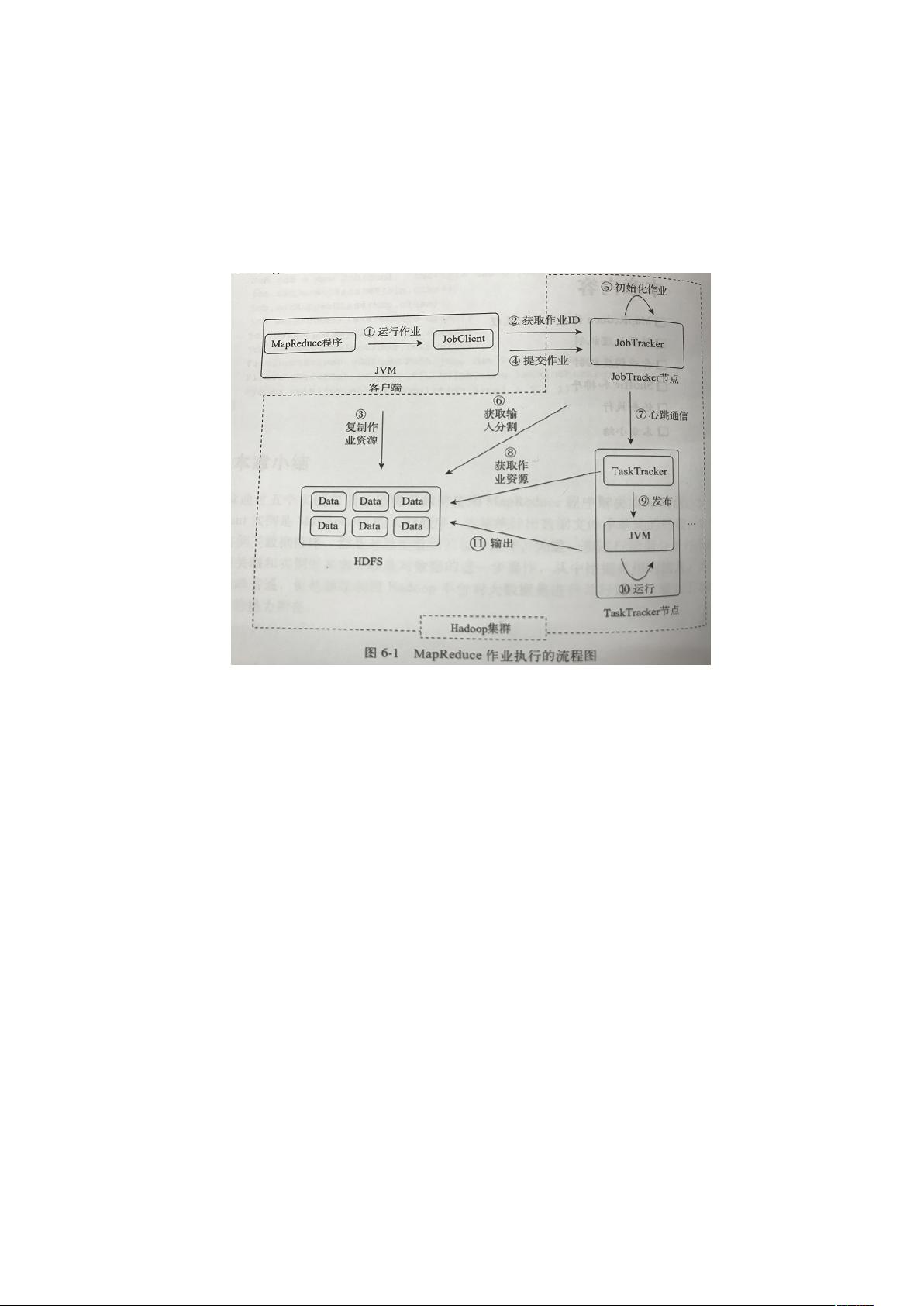
MapReduce 作业的执行流程
一个 MapReduce 作业的执行流程基本是:代码编写、作业配置、作业提交、
map 任务分配和执行、处理中间结果、reduce 任务分配和执行、作业完成。每个
任务执行过程中,包含输入准备、任务执行和输出结果。
client:编写 MapReduce 代码、配置作业、提交作业;
JobTracker:初始化作业、分配作业、与 TaskTracker 通信,协调整个作业的
执行;
TaskTracker:与 JobTracker 保持通信,在分配的数据片段上执行 Map 和
Reduce 任务。
HDFS:保存作业的数据、配置信息等,保存作业的结果。
客户端提交作业的过程大致如下:
1. 获取一个作业的 ID;
2. 检查相关路径,比如输入文件和输出文件是否存在;
3. 对作业的输入进行划分,划分信息写入 Job.split 文件;
4. 把运行需要的资源,比如作业的 jar 文件、配置文件、输入的划分等复制
到 HDFS 中;
5. 真正的提交作业。
JobTracker 上进行作业的初始化(步骤 5),主要是从 HDFS 中读取 Job.split
得到划分的信息(步骤 6)。然后在 JobTracker 上对 map 和 reduce 的任务进行
初始化,这里的初始化是 JobTracker 上初始化了相关的对象,并没有将任务分发
给 TaskTracker 上。JobTracker 和 TaskTracker 之间的通信和任务的分配是通过心
跳机制完成的(步骤 7)。JobTracker 会通过心跳告诉 JobTracker 是否存活、是
否准备执行新的任务。JobTracker 接收到信息后,如果有待分配的任务,它就会













评论0