

Vol.:(0123456789)
1 3
International Journal of Machine Learning and Cybernetics
https://doi.org/10.1007/s13042-020-01069-8
ORIGINAL ARTICLE
From static todynamic word representations: asurvey
YuxuanWang
1
· YutaiHou
1
· WanxiangChe
1
· TingLiu
1
Received: 15 September 2019 / Accepted: 16 January 2020
© Springer-Verlag GmbH Germany, part of Springer Nature 2020
Abstract
In the history of natural language processing (NLP) development, the representation of words has always been a significant
research topic. In this survey, we provide a comprehensive typology of word representation models from a novel perspective
that the development from static to dynamic embeddings can effectively address the polysemy problem, which has been a
great challenge in this field. Then the survey covers the main evaluation metrics and applications of these word embeddings.
And, we further discuss the development of word embeddings from static to dynamic in cross-lingual scenario. Finally, we
point out some open issues and future works.
Keywords Word representation· Static embedding· Dynamic embedding· Cross-lingual embedding
1 Introduction
In the history of NLP, how to represent words which are often
regarded as the smallest semantic elements in the natural lan-
guage has always been a research hotspot. In recent years,
low-dimensional word representation vectors trained with
massive amounts of unannotated textual data, so-called word
embeddings [74, 86] have been demonstrated to be effec-
tive in a wide range of NLP tasks including POS tagging
[119], syntactic parsing [13], named entity recognition [59]
and semantic role labeling [129], machine translation [130].
This kind of embeddings is static in the sense that they do
not change with the context once been learned. Despite their
efficiency, the static nature of these embeddings makes it dif-
ficult to cope with the polysemy problem, since the meaning
of a polysemous word depends on its context.
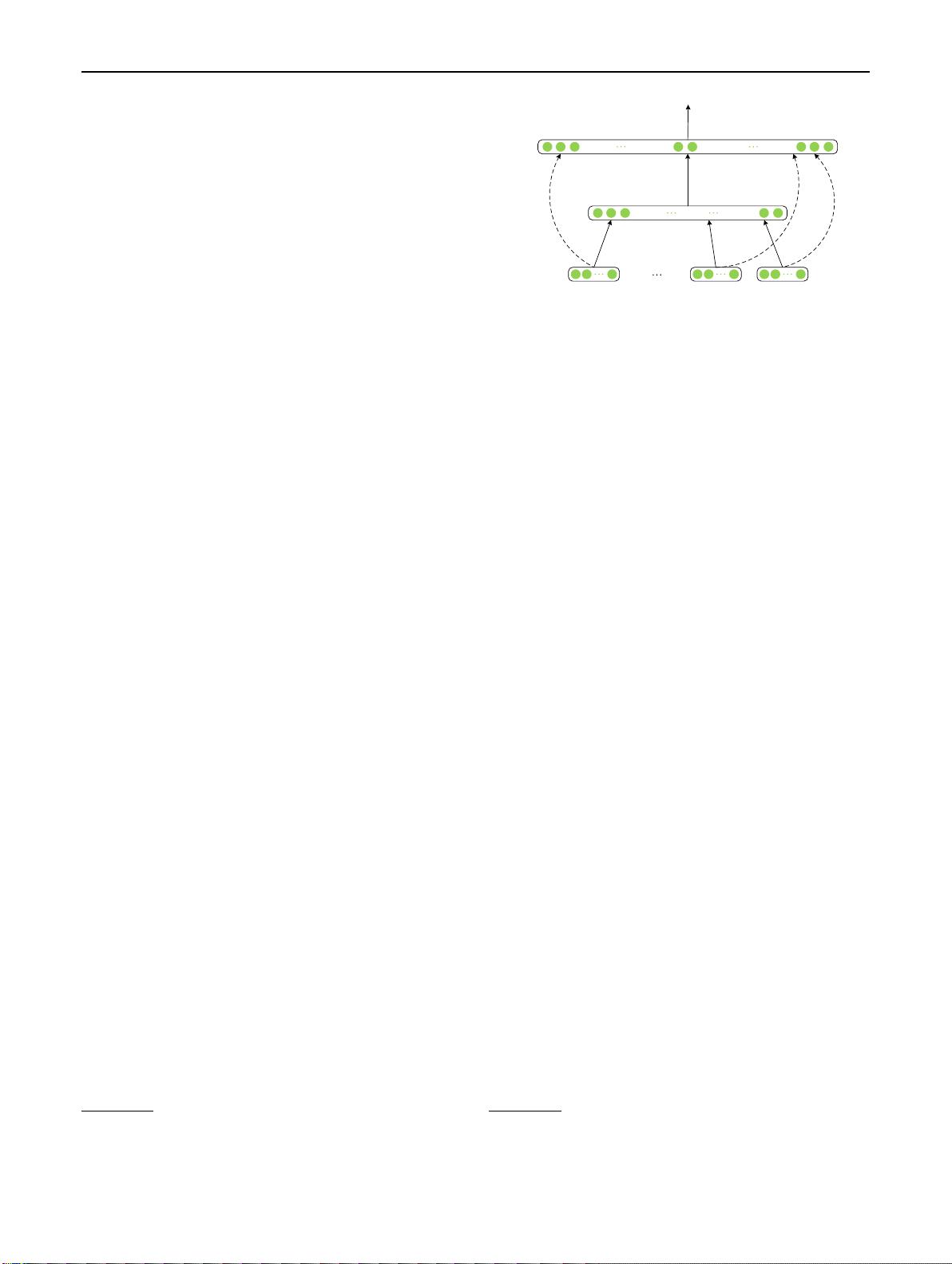
To deal with this problem, a number of approaches
have been recently proposed to learn the representation
of words among their contexts.
1
For example, in two sen-
tences: “Apple sells phones” and “I eat an apple”, dynamic
embeddings will represent “apple” differently according to
the contexts, while static embedding can not distinguish the
semantic difference between two “apples”. These dynamic
embeddings extracted from pre-trained language models
[26, 71, 87, 90] have demonstrated dramatic superiority over
their static predecessors in various NLP tasks. In this survey,
we will provide an inclusive overview of the existing static
and dynamic embedding models. One of the main goals
of this survey is to display the developing trend of word
embedding models from static to dynamic, which demands
for coping with the polysemy problem. To facilitate this, we
first introduce existing static embedding models and some
attempts to deal with the polysemy problem with them in
Sect.2. Then, we introduce and compare the recently pro-
posed dynamic embedding models, and show how they are
able to alleviate the polysemy problem in Sect.3.
With the embedding models described, how to evalu-
ate and apply them to downstream tasks are also notable.
Therefore, we discuss two major categories of evaluation
metrics, namely intrinsic and extrinsic ones in Sect.4. Then
we briefly introduce the line of works trying to transform the
monolingual static and dynamic embeddings to cross-lingual
scenarios in Sect.5. Finally, we discuss some open issues
of word representation in Sect.6. Notions used in the paper
are listed in (Table1).
* Wanxiang Che
car@ir.hit.edu.cn
Yuxuan Wang
yxwang@ir.hit.edu.cn
Yutai Hou
ythou@ir.hit.edu.cn
Ting Liu
tliu@ir.hit.edu.cn
1
Research Center forSocial Computing andInformation
Retrieval, Harbin Institute ofTechnology, Harbin, China
1
These embeddings are contextualized or dynamic as opposed to the
traditional ones.

剩余19页未读,继续阅读

李多田
- 粉丝: 838
- 资源: 333









最新资源
- 机械手自动排列控制PLC与触摸屏程序设计
- uDDS源程序publisher
- 中国风格, 节日 主题, PPT模板
- 生菜生长记录数据集.zip
- 微环谐振腔的光学频率梳matlab仿真 微腔光频梳仿真 包括求解LLE方程(Lugiato-Lefever equation)实现微环中的光频梳,同时考虑了色散,克尔非线性,外部泵浦等因素,具有可延展
- 企业宣传PPT模板, 企业宣传PPT模板
- jetbra插件工具,方便开发者快速开发
- agv 1223.fbx
- 全国职业院校技能大赛网络建设与运维规程
- 混合动力汽车动态规划算法理论油耗计算与视频教学,使用matlab编写快速计算程序,整个工程结构模块化,可以快速改为串联,并联,混联等 控制量可以快速扩展为档位,转矩,转速等 状态量一般为SOC,目
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0