与 Hadoop 对比,如何看待 Spark 技术? - 知乎1
需积分: 0 177 浏览量
2022-08-03
23:50:20
上传
评论
收藏 870KB PDF 举报


12/23/2019 (3 封私信 / 4 条消息) 与 Hadoop 对比,如何看待 Spark 技术? - 知乎
https://www.zhihu.com/question/26568496 1/12
84 个回答
默认排序
软件工程师
3,752 人赞同了该回答
Hadoop
首先看一下Hadoop解决了什么问题,Hadoop就是解决了大数据(大到一台计算机无法进行存储,一
台计算机无法在要求的时间内进行处理)的可靠存储和处理。
HDFS,在由普通PC组成的集群上提供高可靠的文件存储,通过将块保存多个副本的办法解决服务器或
硬盘坏掉的问题。
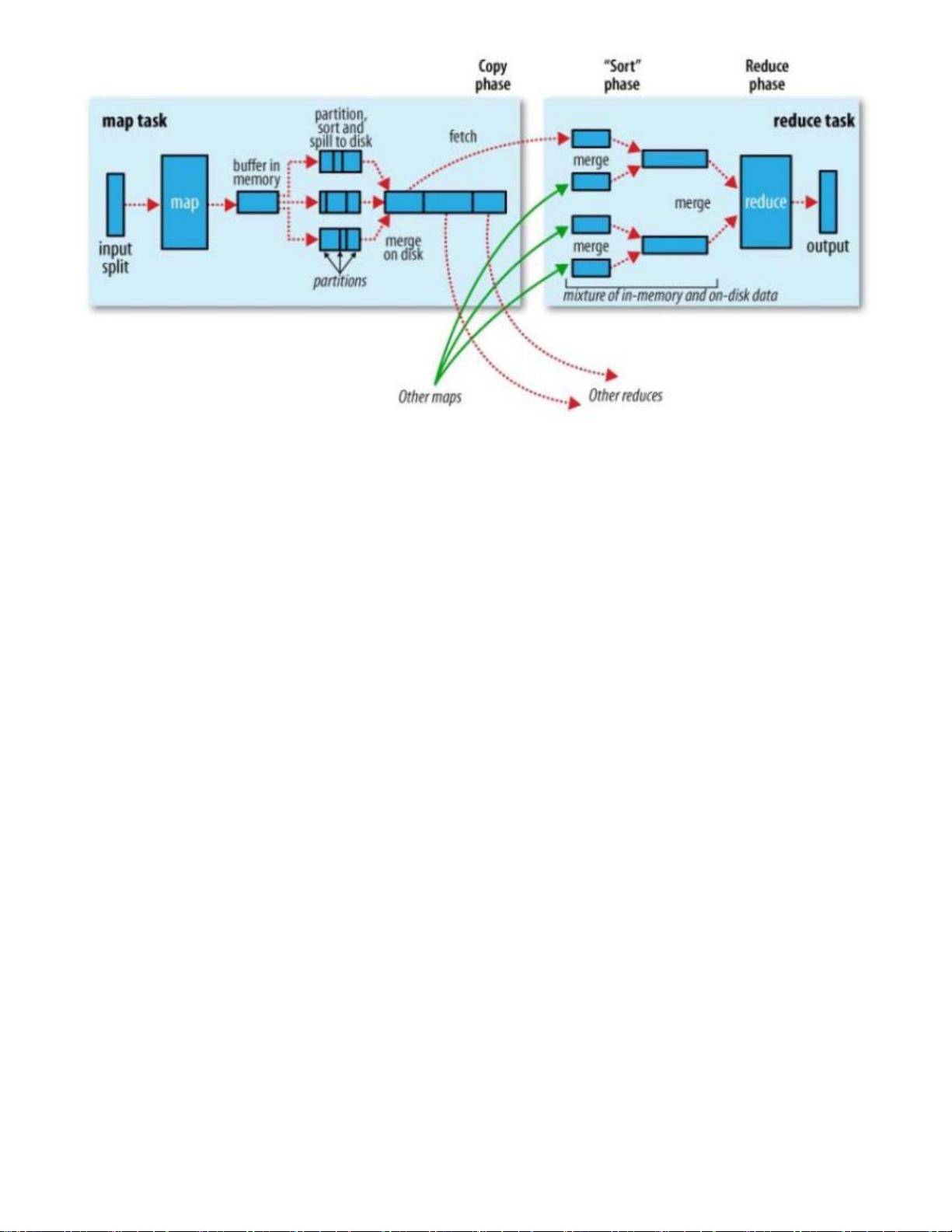
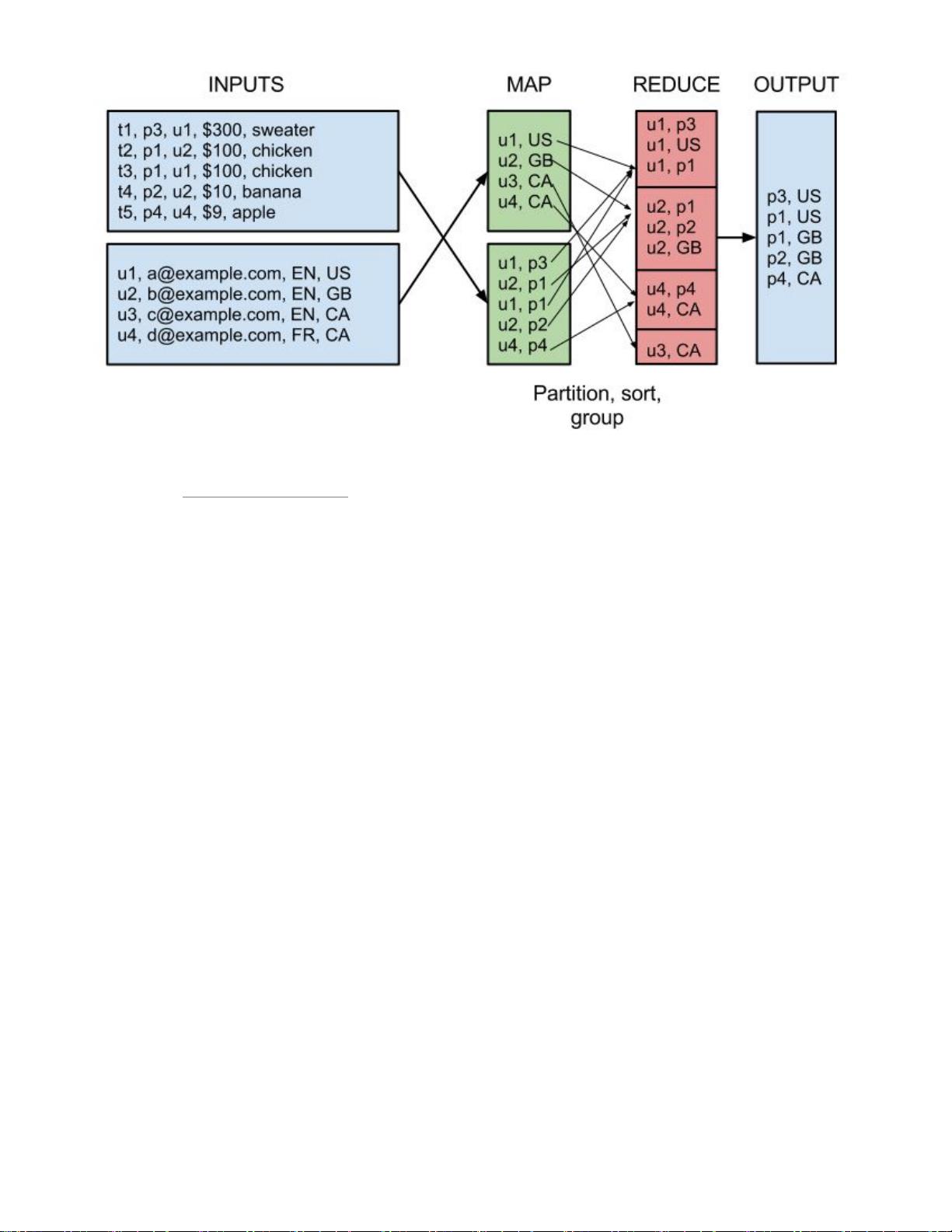
MapReduce,通过简单的Mapper和Reducer的抽象提供一个编程模型,可以在一个由几十台上百台的
PC组成的不可靠集群上并发地,分布式地处理大量的数据集,而把并发、分布式(如机器间通信)和故
障恢复等计算细节隐藏起来。而Mapper和Reducer的抽象,又是各种各样的复杂数据处理都可以分解
为的基本元素。这样,复杂的数据处理可以分解为由多个Job(包含一个Mapper和一个Reducer)组成
的有向无环图(DAG),然后每个Mapper和Reducer放到Hadoop集群上执行,就可以得出结果。
(图片来源:slideshare.net/davideng)
用MapReduce统计一个文本文件中单词出现的频率的示例WordCount请参见:WordCount -
Hadoop Wiki,如果对MapReduce不恨熟悉,通过该示例对MapReduce进行一些了解对理解下文有
帮助。
在MapReduce中,Shuffle是一个非常重要的过程,正是有了看不见的Shuffle过程,才可以使在
MapReduce之上写数据处理的开发者完全感知不到分布式和并发的存在。
用心阁
剩余11页未读,继续阅读













评论0