

计算机研究与发展
DOI
:
10.7544
?
issn1000
-
1239 . 2019 .20190117
Journal
of
Com
p
uter
Research
and
Develo
p
ment
56
(
6
):
1192
-
1204
,
2019
收稿日期
:
2019
-
03
-
01
;
修回日期
:
2019
-
04
-
10
基金项目
:
国家重点研发计划项目
(
2018 Y F B1003501
);
国家自然科学基金项目
(
61732018
,
61872335
,
61802367
);
中国科学院国际伙伴计划
(
171111 K Y SB20170032
);
计算机体系结构国家重点实验室创新项目
(
CARCH3303
,
CARCH3407
,
CARCH3502
,
CARCH3505
)
This
work
was
su
pp
orted
b
y
the
National
Ke
y
Research
and
Develo
p
ment
Plan
of
China
(
2018 Y F B1003501
),
the
National
Natural
Science
Foundation
of
China
(
61732018
,
61872335
,
61802367
),
the
International
Partnershi
p
Pro
g
ram
of
Chinese
Academ
y
of
Sciences
(
171111 K Y SB20170032
),
and
the
Innovation
Pro
j
ect
of
the
State
Ke
y
Laborator
y
of
Com
p
uter
Architecture
(
CARCH3303
,
CARCH3407
,
CARCH3502
,
CARCH3505
)
.
通信作者
:
叶笑春
(
y
exiaochun
@
ict.ac.cn
)
基于细粒度数据流架构的稀疏神经网络全连接层加速
向陶然
1
,
2
叶笑春
1
李文明
1
冯煜晶
1
,
2
谭
旭
1
,
2
张
浩
1
范东睿
1
,
2
1
(
计算机体系结构国家重点实验室
(
中国科学院计算技术研究所
)
北京
100190
)
2
(
中国科学院大学
北京
100049
)
(
xian
g
taoran
@
ict.ac.cn
)
Acceleratin
g
Full
y
Connected
La
y
ers
of
S
p
arse
Neural
Networks
with
Fine
-
Grained
Dataflow
Architectures
Xian
g
Taoran
1
,
2
,
Ye
Xiaochun
1
,
Li
Wenmin
g
1
,
Fen
g
Yu
j
in
g
1
,
2
,
Tan
Xu
1
,
2
,
Zhan
g
Hao
1
,
and
Fan
Don
g
rui
1
,
2
1
(
State
Ke
y
Laborator
y
o
f
Com
p
uter
Architecture
(
Institute
o
f
Com
p
utin
g
Technolo
gy
,
Chinese
Academ
y
o
f
Sciences
),
Bei
j
in
g
100190
)
2
(
Universit
y
o
f
Chinese
Academ
y
o
f
Sciences
,
Bei
j
in
g
100049
)
Abstract
Dee
p
neural
network
(
DNN
)
is
a
hot
and
state
-
of
-
the
-
art
al
g
orithm
which
is
widel
y
used
in
a
pp
lications
such
as
face
reco
g
nition
,
intelli
g
ent
monitorin
g
,
ima
g
e
reco
g
nition
and
text
reco
g
nition.
Because
of
its
hi
g
h
com
p
utational
com
p
lexit
y
,
man
y
efficient
hardware
accelerators
have
been
p
ro
p
osed
to
ex
p
loit
hi
g
h
de
g
ree
of
p
arallel
p
rocessin
g
for
DNN.However
,
the
full
y
connected
la
y
ers
in
DNN
have
a
lar
g
e
number
of
wei
g
ht
p
arameters
,
which
im
p
oses
hi
g
h
re
q
uirements
on
the
bandwidth
of
the
accelerator.In
order
to
reduce
the
bandwidth
p
ressure
of
the
accelerator
,
some
DNN
com
p
ression
al
g
orithms
are
p
ro
p
osed.But
accelerators
which
are
im
p
lemented
on
FPGAs
and
ASICs
usuall
y
sacrifice
g
eneralit
y
for
hi
g
her
p
erformance
and
lower
p
ower
consum
p
tion
,
makin
g
it
difficult
to
accelerate
s
p
arse
neural
networks.Other
accelerators
,
such
as
GPUs
,
are
g
eneral
enou
g
h
,
but
the
y
lead
to
hi
g
her
p
ower
consum
p
tion.Fine
-
g
rained
dataflow
architectures
,
which
break
conventional
Von
Neumann
architectures
,
show
natural
advanta
g
es
in
p
rocessin
g
DNN
-
like
al
g
orithms
with
hi
g
h
com
p
utational
efficienc
y
and
low
p
ower
consum
p
tion.At
the
same
time
,
it
remains
broadl
y
a
pp
licable
and
ada
p
table.In
this
p
a
p
er
,
we
p
ro
p
ose
a
scheme
to
accelerate
the
s
p
arse
DNN
full
y
connected
la
y
ers
on
a
hardware
accelerator
based
on
fine
-
g
rained
dataflow
architecture.Com
p
ared
with
the
ori
g
inal
dense
full
y
connected
la
y
ers
,
the
scheme
reduces
the
p
eak
bandwidth
re
q
uirement
of
2.44×
~
6.17×.
In
addition
,
the
utilization
of
the
com
p
utational
resource
of
the
fine
-
g
rained
dataflow
accelerator
runnin
g
the
s
p
arse
full
y
-
connected
la
y
ers
far
exceeds
the
im
p
lementation
b
y
other
hardware
p
latforms
,
which
is
43.15%
,
34.57%
,
and
44.24% hi
g
her
than
the
CPU
,
GPU
,
and
mGPU
,
res
p
ectivel
y
.
Ke
y
words
fine
-
g
rained
dataflow
;
s
p
arse
neural
network
;
g
eneral
accelerator
;
data
reuse
;
hi
g
h
p
arallel

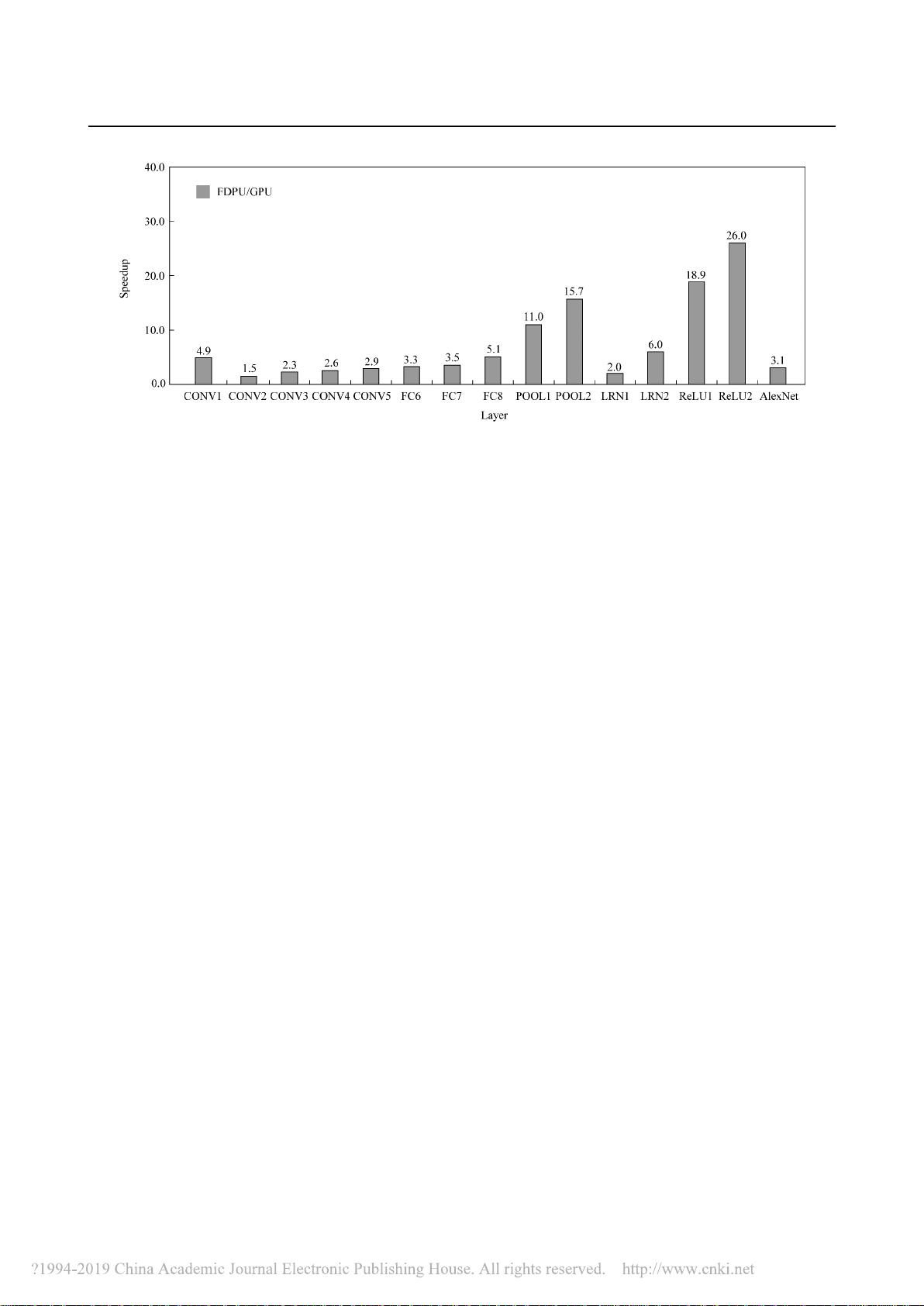
剩余12页未读,继续阅读













评论0