用Python开始机器学习1

需积分: 0 67 浏览量
更新于2022-08-08
收藏 1.5MB DOCX 举报
标题“用Python开始机器学习1”和描述主要介绍了如何配置Python环境来开始机器学习,特别是针对Windows平台。以下是详细的知识点:
1. **Python作为机器学习平台**:
Python是一种广泛用于机器学习的编程语言,因其丰富的库和易读性而受到欢迎。文中提到了几个关键的Python库,包括Numpy、Scipy、Scikit-learn和Matplotlib。
2. **Numpy库**:
Numpy是Python中的一个科学计算库,特别适合处理大规模的多维数据。它提供了高效的数组操作和矩阵运算,是数据预处理和构建模型的基础。
3. **Scipy库**:
Scipy是另一个重要的科学计算库,包含了数学、优化、插值、线性代数和统计等功能,对机器学习中的数值计算非常有用。
4. **Scikit-learn库**:
Scikit-learn是Python中最流行的机器学习库,提供了多种机器学习算法,包括分类、回归、聚类和降维等。它还包含了数据预处理、模型选择和评估工具。
5. **Matplotlib库**:
Matplotlib是Python的数据可视化库,可以用于绘制2D和3D图形,对于理解和展示机器学习模型的预测结果至关重要。
6. **安装Python库**:
文中提到的网站`http://www.lfd.uci.edu/~gohlke/pythonlibs/`提供了一个方便的资源,可以在这里找到对应Python版本的扩展库的.exe安装文件。安装时,如果是.exe文件,可以直接运行;如果不是,需要手动将库文件复制到Python的site-packages目录下。
7. **测试库的安装**:
使用`import`语句可以检查Python库是否已成功安装。如果导入时出现错误,说明库没有正确安装,需要查找并安装缺失的库。
8. **依赖库的安装**:
安装主要库时,可能会遇到依赖库的问题,例如six、nose、pyparsing和dateutil。如果遇到版本不兼容或缺失的情况,需要单独安装这些依赖库。
9. **资源推荐**:
- Python教程:`http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000`
- Scikit-learn教程:`http://scikit-learn.org/stable/windows`
- Python IDE选择:`http://blog.csdn.net/cserchen/article/details/7036435`
- 机器学习入门书籍《机器学习系统设计》的源码和数据:`https://github.com/luispedro/BuildingMachineLearningSystemsWithPython/tree/master/ch02`
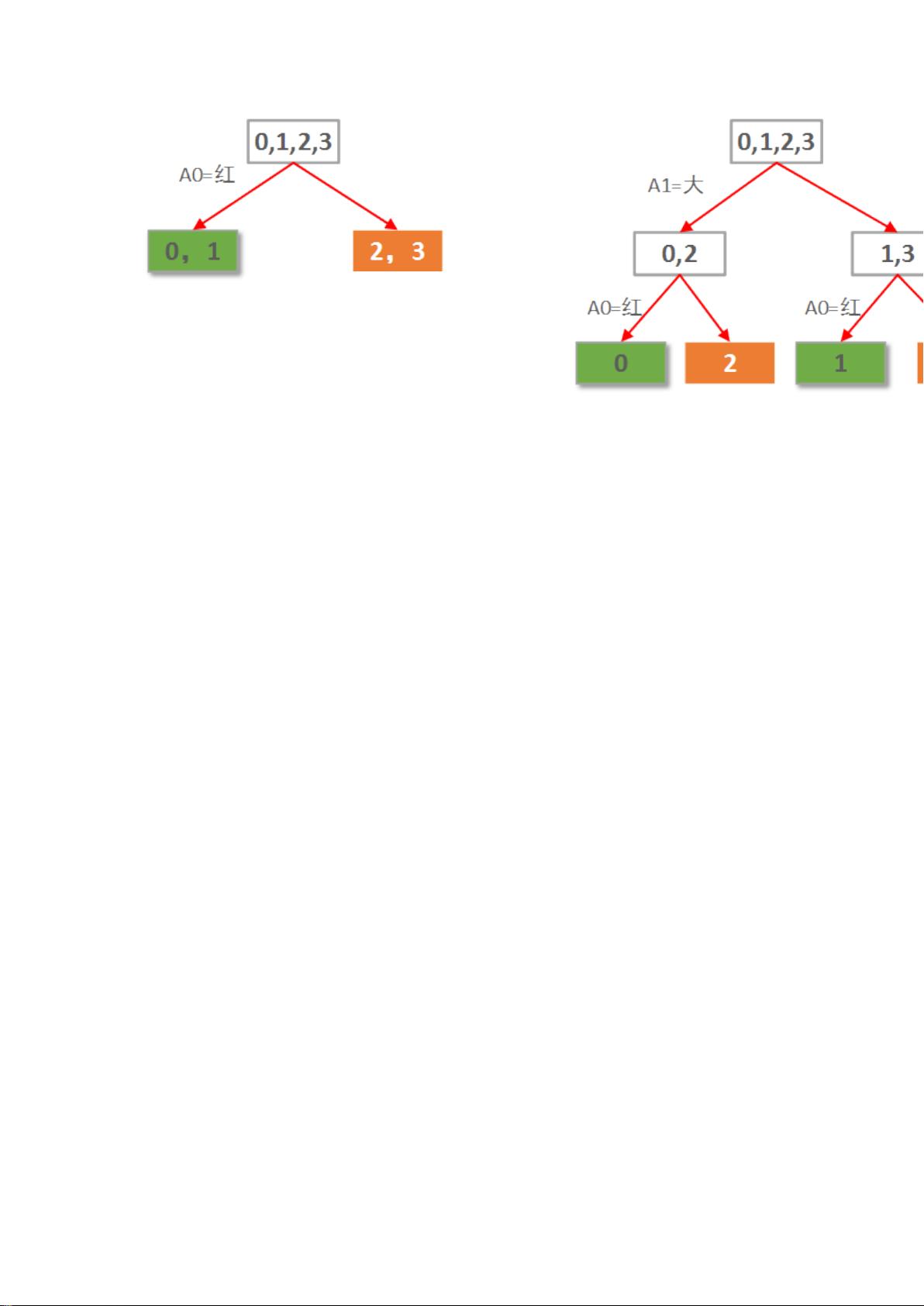
10. **决策树算法**:
在接下来的部分,文章提到了机器学习中的决策树算法,这是一种直观且易于理解的分类方法。ID3算法是基于信息熵和信息增益的决策树构建方法,后续的C4.5、C5.0和CART等算法是对ID3的改进。
11. **信息熵和信息增益**:
信息熵是衡量数据纯度或无序程度的指标。在构建决策树时,信息增益用于选择最佳属性进行划分,以减少数据集的不确定性。
通过以上步骤和知识,读者可以建立一个基本的Python机器学习环境,并开始学习和实践决策树算法。在后续章节中,文章将深入探讨决策树分类算法的具体应用。

用 Python 开始机器学习(1:配置 windows 平台)
分类: 机器学习 2014-11-13 19:07 1408 人阅读 评论(1) 收藏 举报
使用机器学习的开发工具很多,如 Matlab,R 语言,Python 等等。
本系列文章不会涉及深入的机器学习原理,旨在让你迅速上手,入门 Python 进行机器学
习。
本文提供一系列资源,教你打造一个 Python 机器学习的平台。
1、下载资源
Python
本文以 Python 3.4 为例。当然你可以使用老版本。
老版本的一个优势是扩展库比较多。
链接:https://www.python.org/
下面是 Python 的扩展库。扩展库必须与使用的 Python 版本相对应。
这里给出一个神地址,能快速下载到下面需要的,各种平台、各种 python 版本的扩展库。
http://www.lfd.uci.edu/~gohlke/pythonlibs/
numpy:用于处理大规模多维数据。
scipy:数学库。
scikit-learn:机器学习库。
matplotlib:可视化数据神器。文档和示例地址:http://matplotlib.org/gallery.html



剩余58页未读,继续阅读
162 浏览量
113 浏览量
2020-12-21 上传
2020-09-19 上传
191 浏览量
129 浏览量
138 浏览量
165 浏览量
133 浏览量
2021-08-21 上传
2018-03-06 上传
147 浏览量
186 浏览量
2021-05-26 上传
151 浏览量
资源评论


罗小熙
- 粉丝: 22
- 资源: 318









