Spark讲义(上) 1
需积分: 0 135 浏览量
2022-08-04
14:36:34
上传
评论
收藏 8.21MB PDF 举报

大数据高速计算引擎Spark(上)【讲师:回灯】
课程内容:
MapReduce、Spark、Flink(实时) => 3代计算引擎;昨天、今天、未来
MapReduce、Spark:类MR的处理引擎;底层原理非常相似;数据分区、map task、reduce task、shuffle
第一部分 Spark Core
第1节 Spark概述
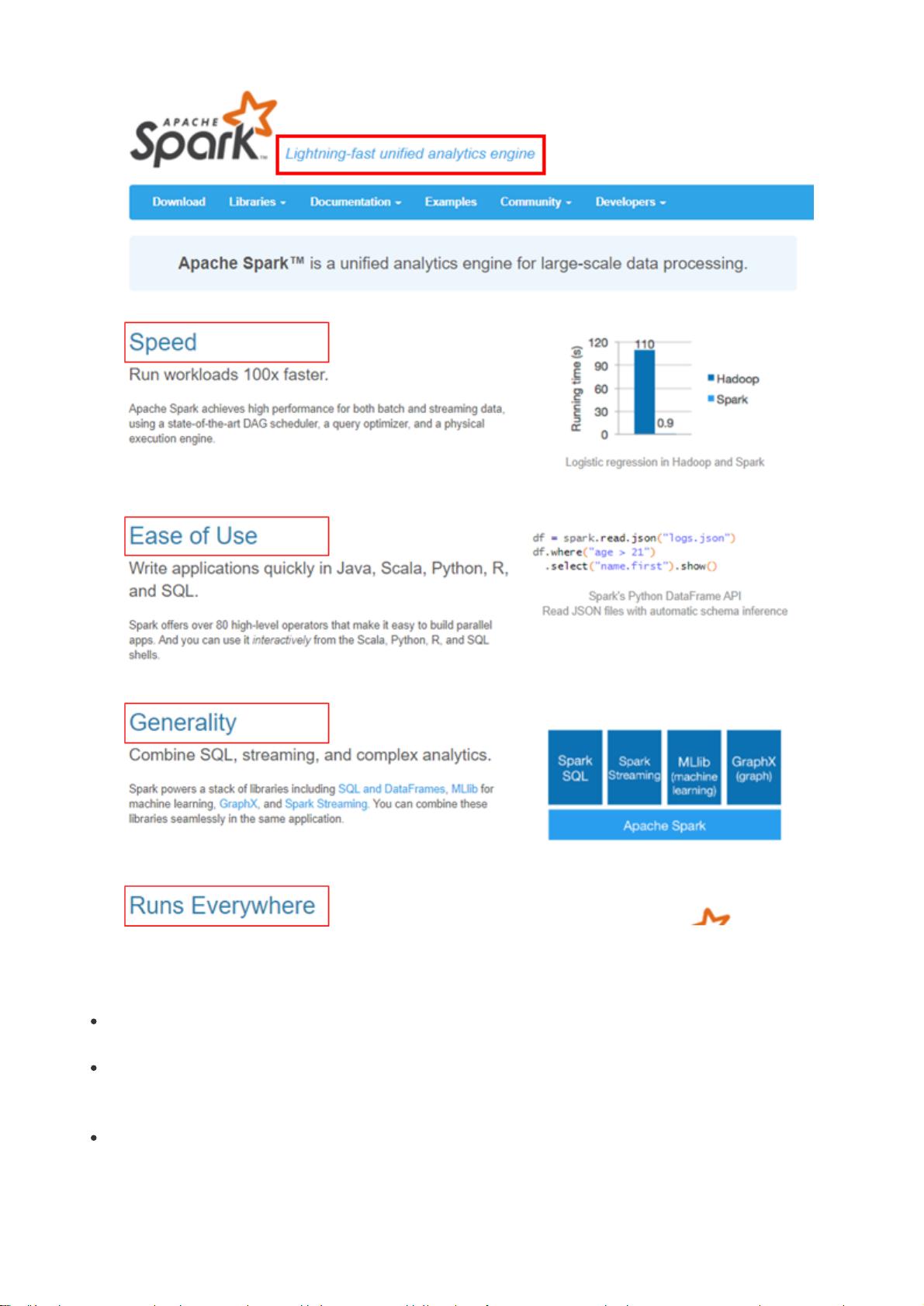
1.1 什么是Spark
Spark是当今大数据领域最活跃、最热门、最高效的大数据通用计算引擎
2009年诞生于美国加州大学伯克利分校AMP 实验室
2010年通过BSD许可协议开源发布
2013年捐赠给Apache软件基金会并切换开源协议到切换许可协议至 Apache2.0
2014年2月,Spark 成为 Apache 的顶级项目
2014年11月, Spark的母公司Databricks团队使用Spark刷新数据排序世界记录
Spark 成功构建起了一体化、多元化的大数据处理体系。在任何规模的数据计算中, Spark 在性能和扩展性上都更具
优势
Spark Core -- 离线
Spark SQL -- 离线、交互
Spark Streaming -- 实时
Spark GraphX -- 图处理
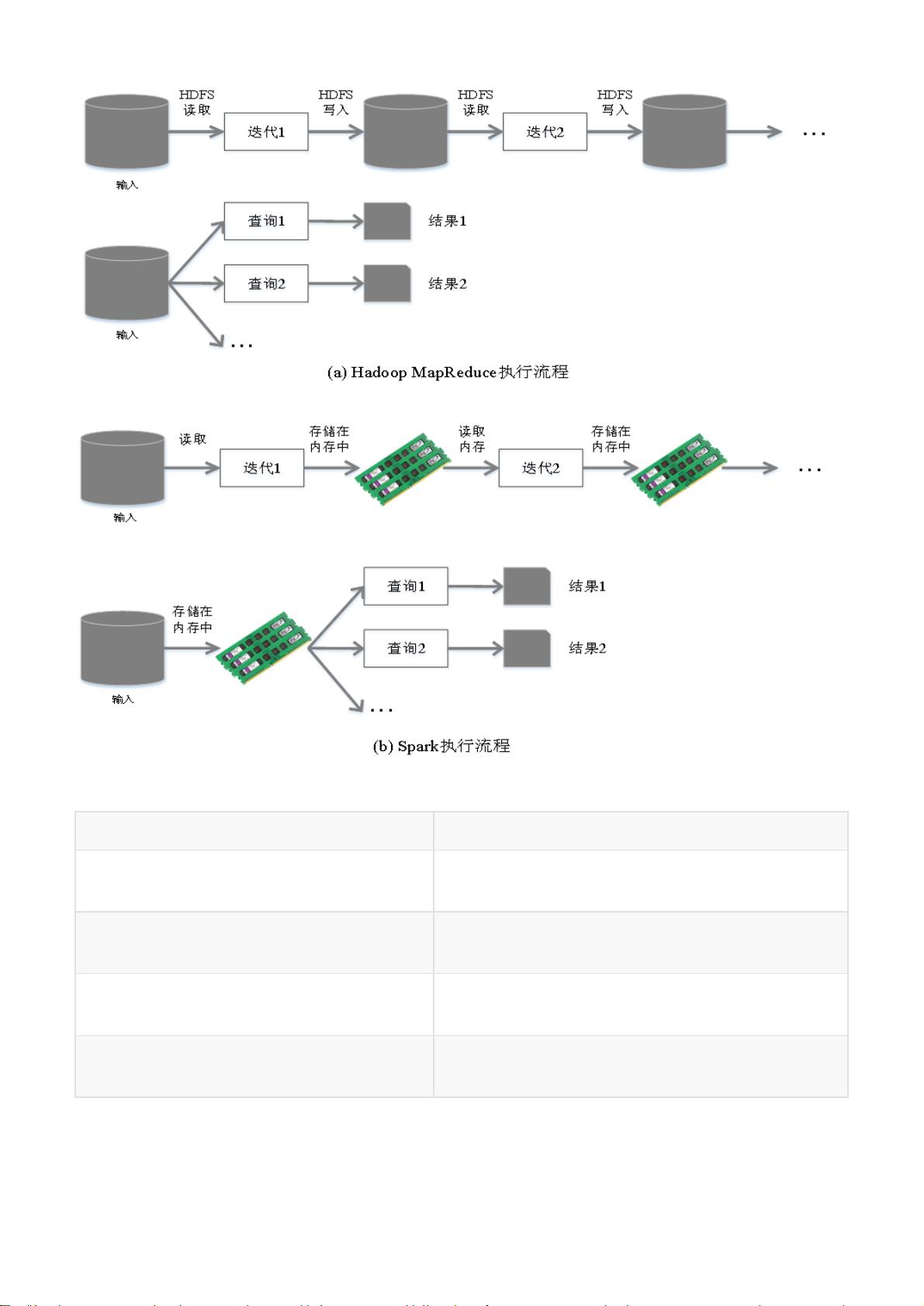
Spark原理


剩余133页未读,继续阅读













评论0