
人工智能实验:文本数据的分类与分析
目录
一、实验目的.............................................................................................................................................. 2
二、实验类型.............................................................................................................................................. 2
三、实验要求.............................................................................................................................................. 2
四、实验内容.............................................................................................................................................. 3
4.1 实验分工 ..................................................................................................................................... 3
五、实验步骤.............................................................................................................................................. 4
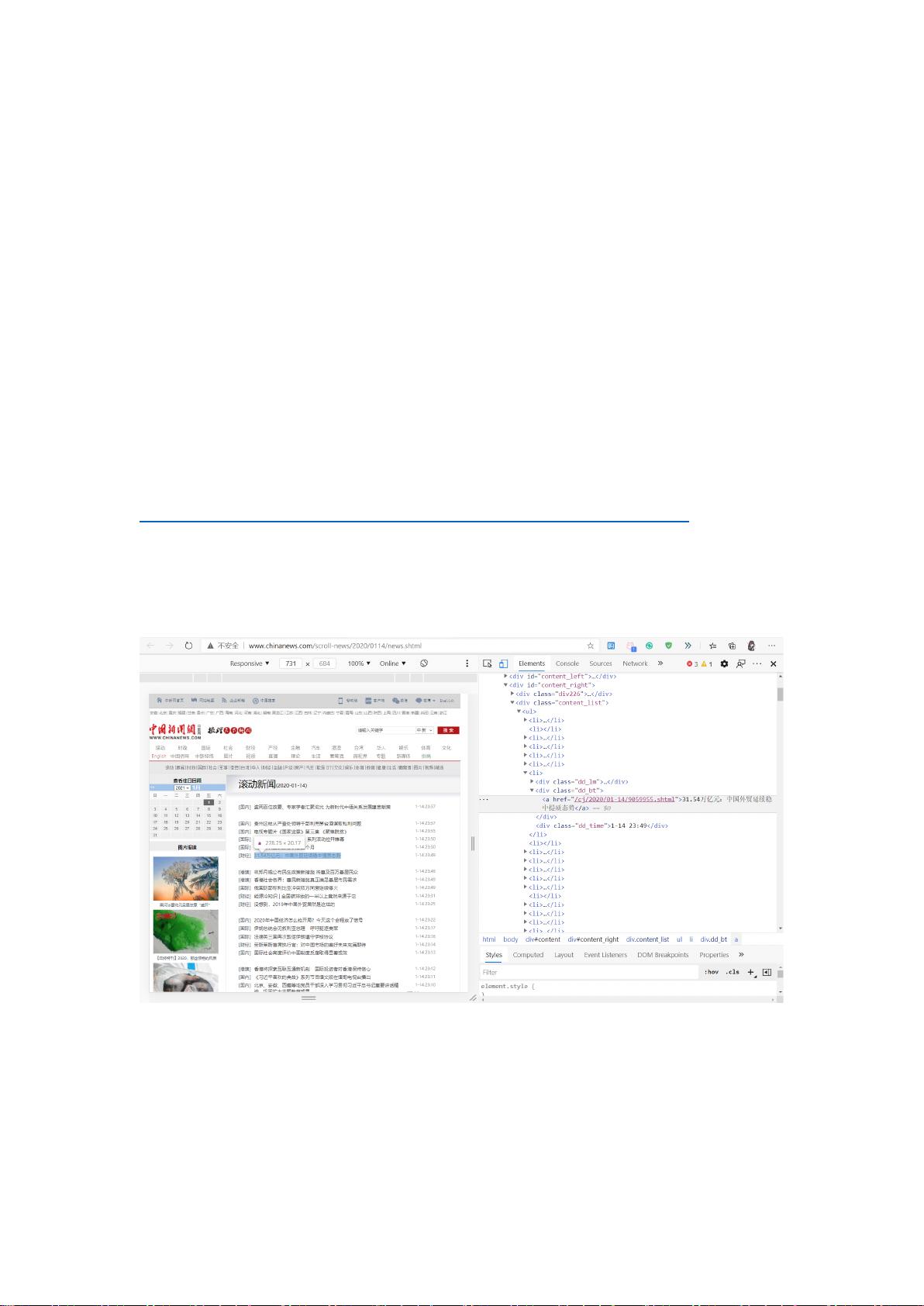
5.1 数据收集 ..................................................................................................................................... 4
5.2 数据预处理 ................................................................................................................................ 7
5.3 朴素贝叶斯分类器 ................................................................................................................ 14
5.4 SVM 分类器 .............................................................................................................................. 18
六、思考与体会 ....................................................................................................................................... 22
附录 实验代码 ......................................................................................................................................... 23
GetData_1.py ................................................................................................................................... 23
GetData_2.py ................................................................................................................................... 24
SelectNews.py ................................................................................................................................. 26
DataPro_1.py ................................................................................................................................... 27
DataPro_2.py ................................................................................................................................... 29
DataPro_Test.py ............................................................................................................................. 29
朴素贝叶斯.py ................................................................................................................................ 30
SVC.py ............................................................................................................................................... 34

















评论0