
自然语言理解 课程大作业一
分词与词性标注
07111805 1120181319 崔晨曦
一、项目概况
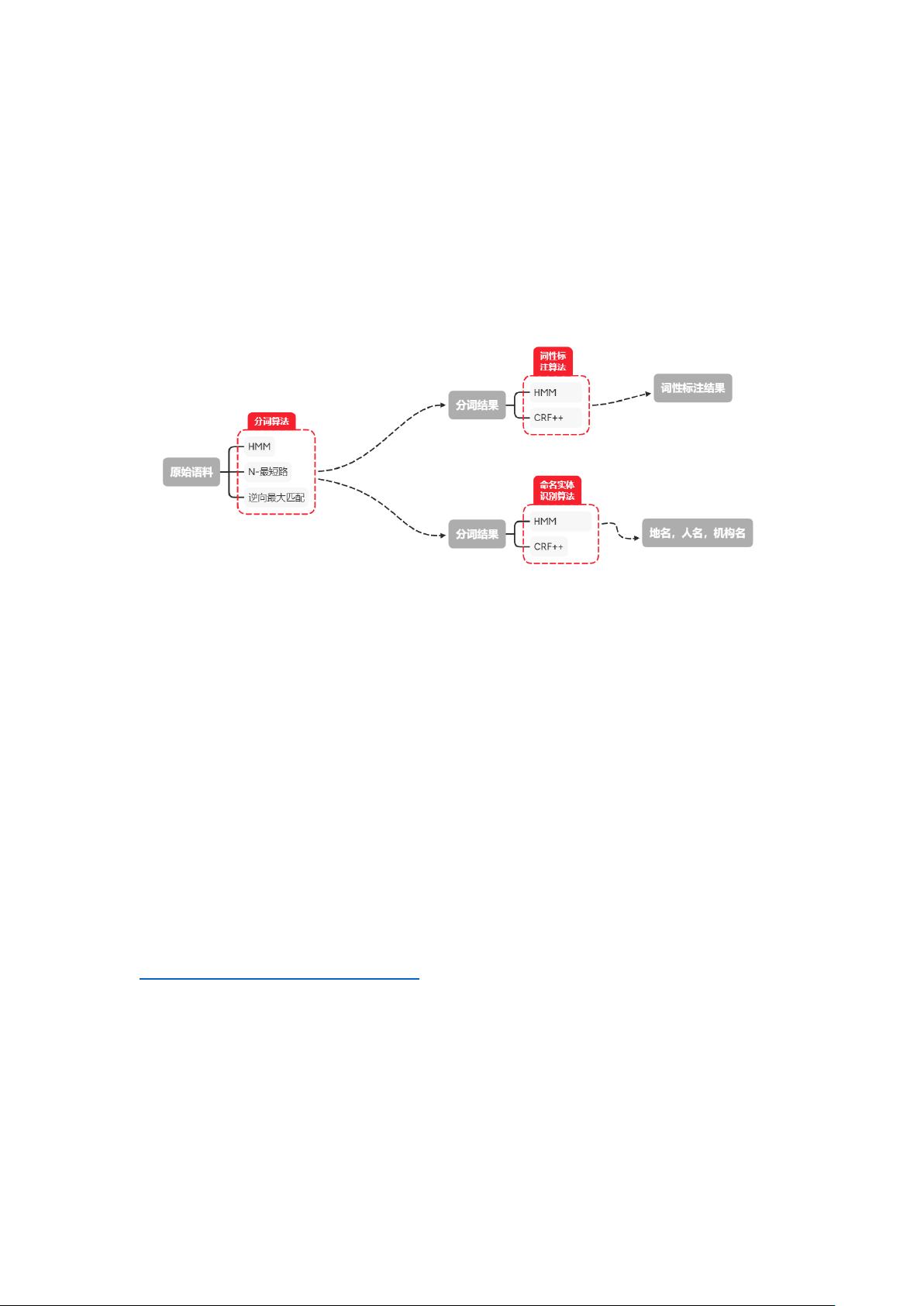
本项目是一个使用 python 实现的词法分析工具包,集成了分词,词性标注以及命名实
体识别等功能。项目处理流程如上图所示。
对于分词,本项目提供了三种不同的算法实现:隐马尔可夫(HMM),N-最短路和逆向最
大匹配。其中隐马尔可夫是基于统计的算法,而 N-最短路及逆向最大匹配均是基于词典的
算法。
对于词性标注,本项目提供了两种算法实现,HMM 和条件随机场(CRF++)。其中 CRF++
使用 python 作为胶水语言,调用底层的开源 C++接口,拥有较高的效率。
对于命名实体识别(NER),本项目同样提供了 HMM 和 CRF++的两种实现。
二、项目实现
2.1 数据及预处理
2.1.1 数据集
本项目的数据集使用的是“北大语料库加工规范:切分·词性标注·注音”(2003 规范),
https://klcl.pku.edu.cn/gxzy/231686.htm。大小约 9MB,共 23268 行,内容来源于 1998 年的
人民日报。语料已经完成切分和词性标注,含 100 多种词性标签。
本项目使用的词典通过对训练语料处理计数后得到。此外还使用了 hanlp 中内置的
CoreNatureDictionary.txt 作为对照,其大小约 2MB,共收录 153091 个词。
将数据集的前 20869 行作为训练集,后 2398 行作为测试集,比例约为 8.7:1。
2.1.2 数据预处理
由于原始数据集中一行内含有多个句子,故预处理的第一步便是按句进行分行,保证前
后词之间具有语义上的关联性,这对于 HMM 和 CRF++这种统计模型较为重要,按句分行


剩余13页未读,继续阅读













评论0