
leveldb 简介
Leveldb是一个google实现的非常高效的kv数据库,能够支持billion级别的数据量了。
特点
key、value支持任意的byte类型数组,不单单支持字符串。
LevelDb是一个持久化存储的KV系统,将大部分数据存储到磁盘上。
按照记录key值顺序存储数据,并且LevleDb支持按照用户定义的比较函数进行排序。
操作接口简单,基本操作包括写记录,读记录以及删除记录,也支持针对多条操作的原子批量操
作。
支持数据快照(snapshot)功能,使得读取操作不受写操作影响,可以在读操作过程中始终看到一
致的数据。
支持数据压缩(snappy压缩)操作,有效减小存储空间、并增快IO效率。
总体来说,LevelDb的写操作要大大快于读操作,而顺序读写操作则大大快于随机读写操作。
限制
LevelDB 只是一个 C/C++ 编程语言的库, 使用者应该封装自己的网络服务器。 所以无法像一般意义
的存储服务器(如 MySQL)那样, 用客户端来连接它。
非关系型数据模型(NoSQL),不支持sql语句,也不支持索引。
一次只允许一个进程访问一个特定的数据库。
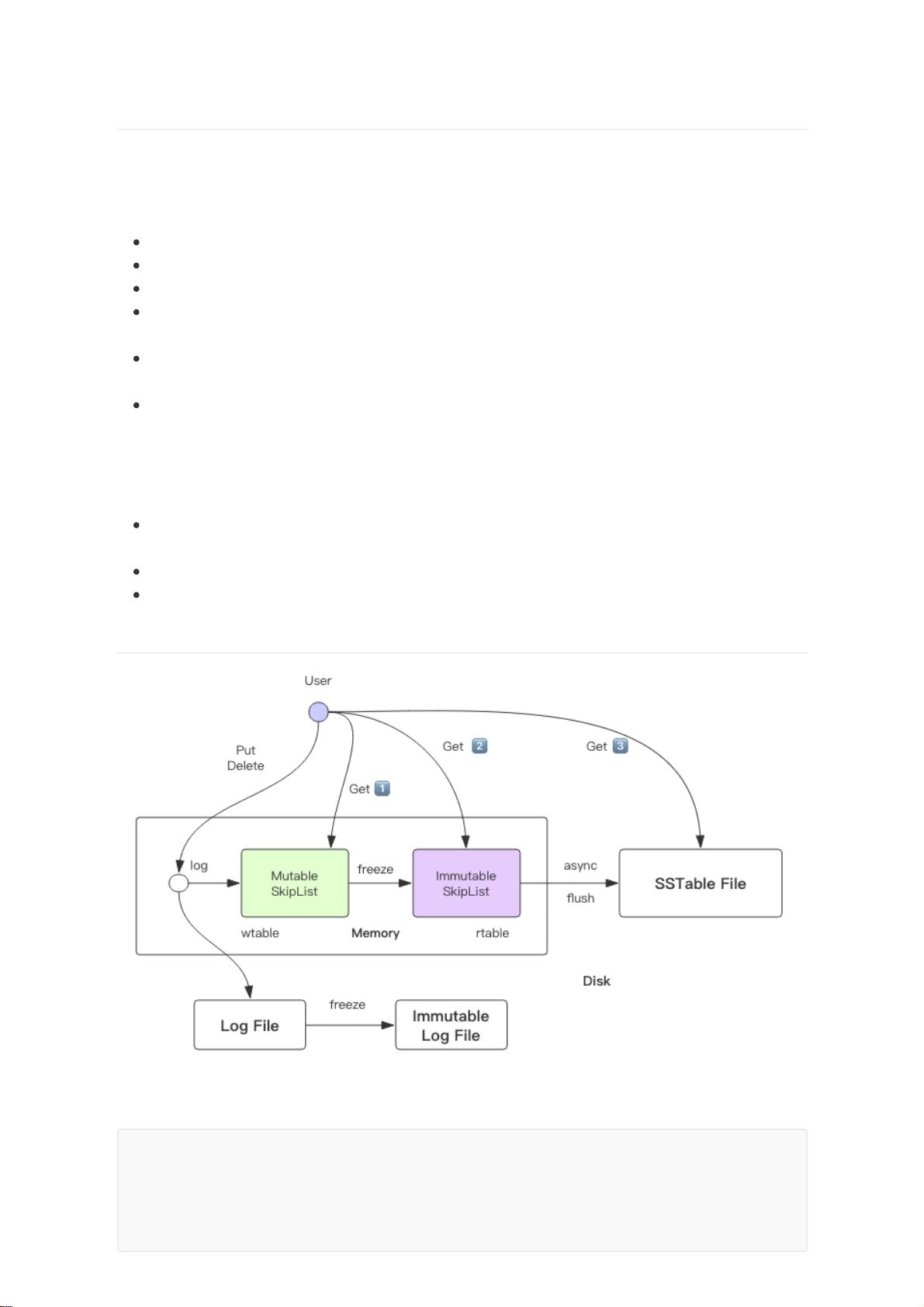
leveldb 的架构
User 代表客户端,提供增删改查功能
virtual Status Put(const WriteOptions&, const Slice& key, const Slice& value);
virtual Status Delete(const WriteOptions&, const Slice& key);
virtual Status Write(const WriteOptions& options, WriteBatch* updates);
virtual Status Get(const ReadOptions& options, const Slice& key, std::string*
value);

家的要素
- 粉丝: 29
- 资源: 298









最新资源
- (176413212)源代码 ,电动跷跷板-大学生电子设计大赛.rar
- 手语图像分类数据集【已标注,约2,500张数据】
- (68688640)python获取股票信息
- (175881858)基于KNN算法的MATLAB人脸识别-课程设计.zip
- (178021462)基于Javaweb+ssm的医院在线挂号系统的设计与实现.zip
- (179941434)基于MATLAB车牌识别系统【含界面GUI】.zip
- (179941432)基于MATLAB车牌识别系统【GUI含界面】.zip
- (179010422)基于ensp搭建的校园网
- (177588850)基于java+mysql+swing的学生选课成绩信息系统
- (175549404)基于微信小程序的十二神鹿点餐(外卖小程序)(毕业设计,包括数据库,源码,教程).zip
- (42233200)Proteus单片机仿真实例大全(29个案例).zip
- (175053052)计算机网络课程设计,实验报告和源码,校园网
- (178977624)Python数据分析与挖掘源码.zip
- (179979052)基于MATLAB车牌识别系统【带界面GUI】.zip
- (481250)Proteus 与单片机 仿真
- NVR-K51-CN-V3.4.112-200604
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0