机器学习-聚类算法1
需积分: 0 190 浏览量
2022-08-03
19:45:56
上传
评论
收藏 979KB PDF 举报


参考:
基础聚类 https://www.jianshu.com/p/8890ccdfaf6c
其他聚类 https://www.jianshu.com/p/8890ccdfaf6c
基础聚类
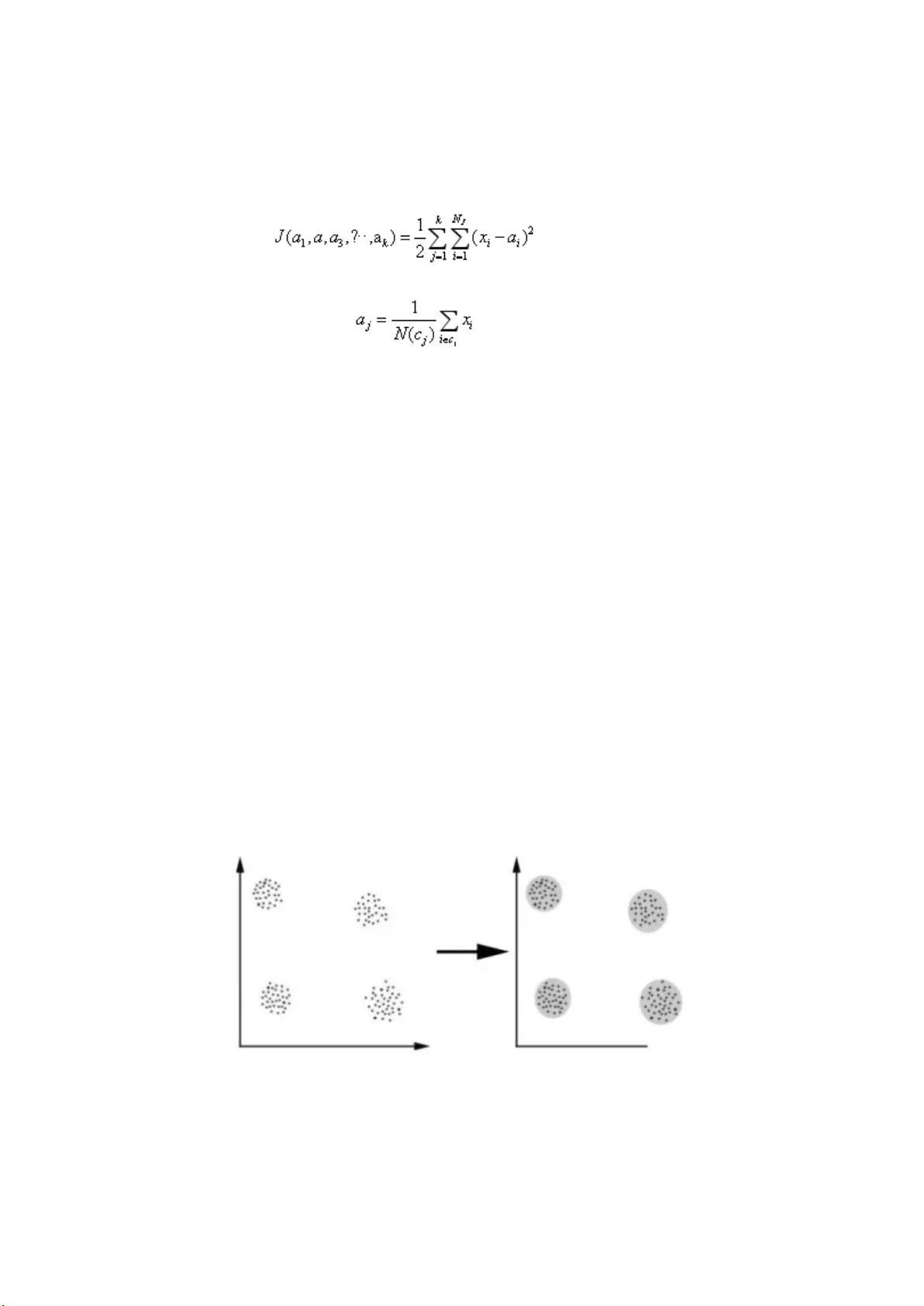
这里将介绍无监督学习算法,也就是聚类算法。在无监督学习中,目标属性是不存在的,也就是所说
的不存在“y”值,我们是根据内部存在的数据特征,划分不同的类别,使得类别内的数据比较相
似。
我们对数据进行聚类的思想不同可以设计不同的聚类算法,本章主要谈论三种聚类思想以及该聚类思
想下的三种聚类算法。
“距离”
•
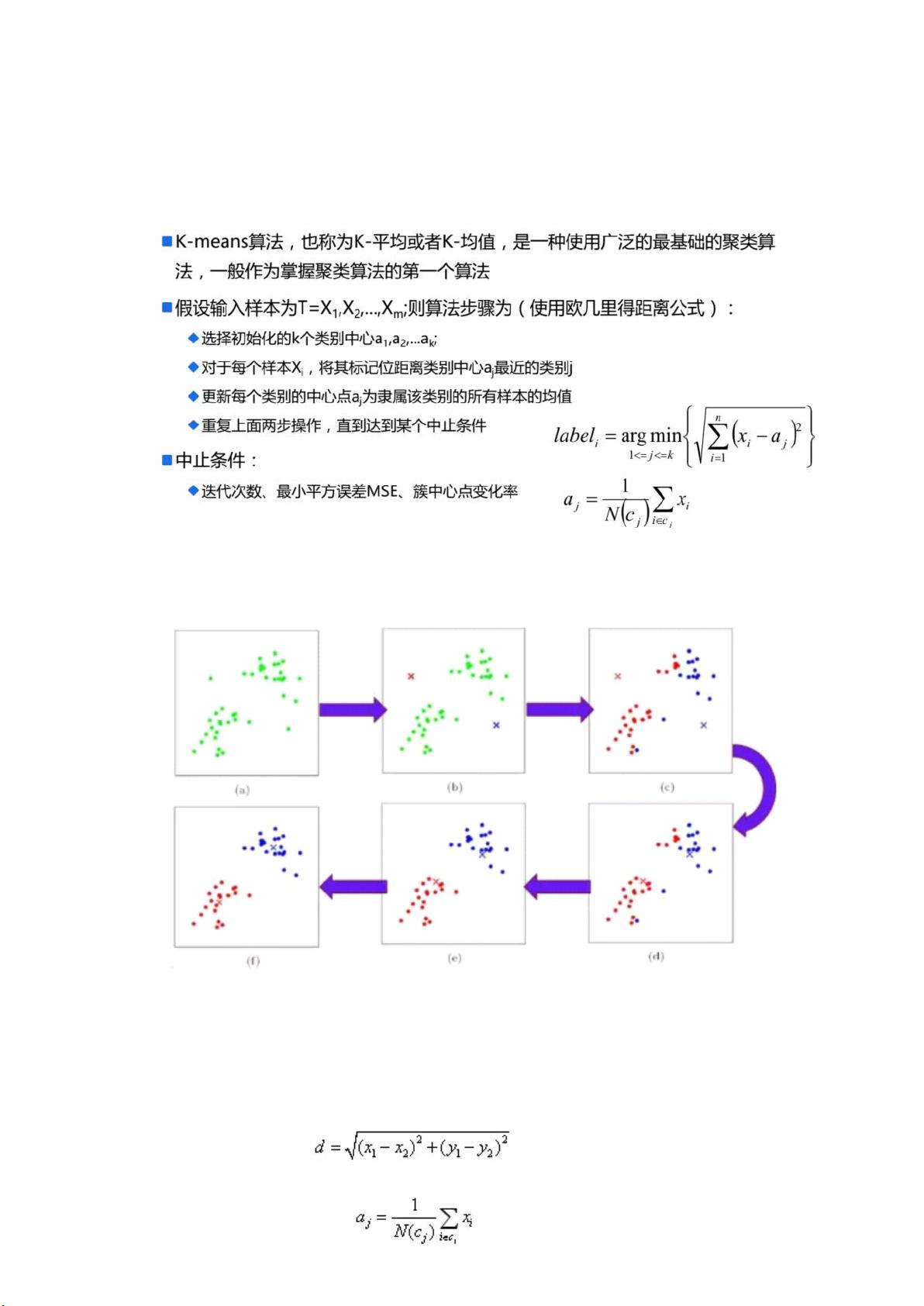
K-Means算法
•
几种优化K-Means算法
•
密度聚类
•
本章主要涉及到的知识点有:
算法思想:“物以类聚,人以群分”
本节首先通过聚类算法的基本思想,引出样本相似度这个概念,并且介绍几种基本的样本相识度方
法。
如何将数据划分不同类别
通过计算样本之间的相识度,将相识度大的划分为一个类别。衡量样本之间的相识度的大小的方式有
下面几种:
闵可夫斯基距离
(Minkowski距离)也就是前面提到的范式距离
当p=1时为曼哈顿距离,公式如下(以二维空间为例):
机器学习-聚类算法
2021
年
4
月
6
日
11:20
分区 计算机专业课 的第
1
页

剩余22页未读,继续阅读






评论0
最新资源