
lems by presenting FIRM, a multilevel machine learning (ML)
based resource management (RM) framework to manage
shared resources among microservices at finer granularity
to reduce resource contention and thus increase performance
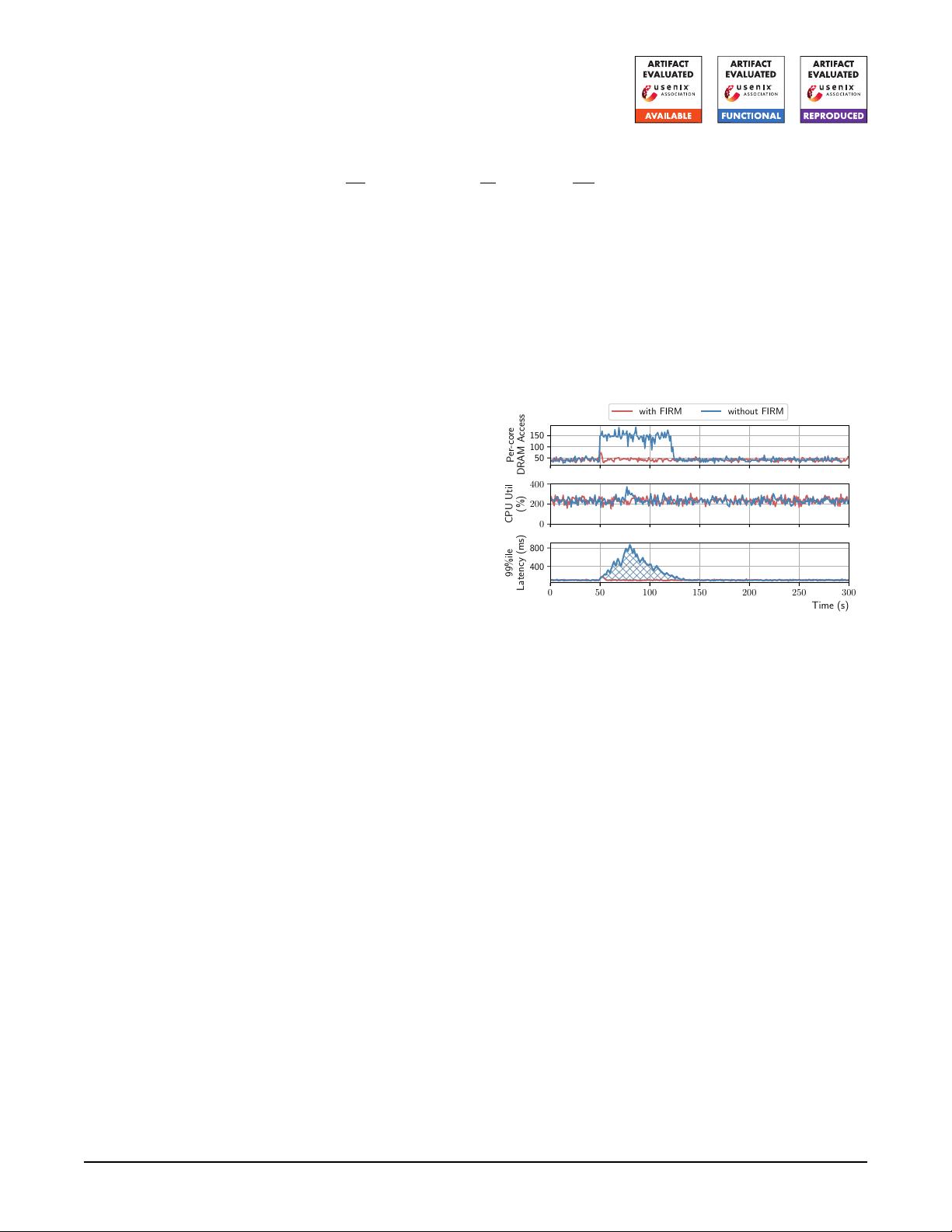
isolation and resource utilization. As shown in Fig. 1, FIRM
performs better than a default Kubernetes autoscaler because
FIRM adaptively scales up the microservice (by adding local
cores) to increase the aggregate memory bandwidth alloca-
tion, thereby effectively maintaining the per-core allocation.
FIRM leverages online telemetry data (such as request-tracing
data and hardware counters) to capture the system state, and
ML models for resource contention estimation and mitigation.
Online telemetry data and ML models enable FIRM to adapt
to workload changes and alleviate the need for brittle, hand-
crafted heuristics. In particular, FIRM uses the following ML
models:
•
Support vector machine (SVM) driven detection and lo-
calization of SLO violations to individual microservice
instances. FIRM first identifies the “critical paths,” and
then uses per-critical-path and per-microservice-instance
performance variability metrics (e.g., sojourn time [1]) to
output a binary decision on whether or not a microservice
instance is responsible for SLO violations.
•
Reinforcement learning (RL) driven mitigation of SLO vio-
lations that reduces contention on shared resources. FIRM
then uses resource utilization, workload characteristics, and
performance metrics to make dynamic reprovisioning deci-
sions, which include (a) increasing or reducing the partition
portion or limit for a resource type, (b) scaling up/down,
i.e., adding or reducing the amount of resources attached to
a container, and (c) scaling out/in, i.e., scaling the number
of replicas for services. By continuing to learn mitigation
policies through reinforcement, FIRM can optimize for
dynamic workload-specific characteristics.
Online Training for FIRM.
We developed a performance
anomaly injection framework that can artificially create re-
source scarcity situations in order to both train and assess the
proposed framework. The injector is capable of injecting re-
source contention problems at a fine granularity (such as last-
level cache and network devices) to trigger SLO violations.
To enable rapid (re)training of the proposed system as the un-
derlying systems [67] and workloads [40,42,96,98] change in
datacenter environments, FIRM uses transfer learning. That
is, FIRM leverages transfer learning to train microservice-
specific RL agents based on previous RL experience.
Contributions.
To the best of our knowledge, this is the
first work to provide an SLO violation mitigation framework
for microservices by using fine-grained resource management
in an application-architecture-agnostic way with multilevel
ML models. Our main contributions are:
1.
SVM-based SLO Violation Localization: We present (in
§3.2 and §3.3) an efficient way of localizing the microser-
vice instances responsible for SLO violations by extracting
critical paths and detecting anomaly instances in near-real
time using telemetry data.
2.
RL-based SLO Violation Mitigation: We present (in §3.4)
an RL-based resource contention mitigation mechanism
that (a) addresses the large state space problem and (b)
is capable of tuning tailored RL agents for individual mi-
croservice instances by using transfer learning.
3.
Online Training & Performance Anomaly Injection: We
propose (in §3.6) a comprehensive performance anomaly
injection framework to artificially create resource con-
tention situations, thereby generating the ground-truth data
required for training the aforementioned ML models.
4.
Implementation & Evaluation: We provide an open-source
implementation of FIRM for the Kubernetes container-
orchestration system [
20]. We demonstrate and vali-
date this implementation on four real-world microservice
benchmarks [34, 116] (in §4).
Results.
FIRM significantly outperforms state-of-the-art
RM frameworks like Kubernetes autoscaling [
20, 55] and
additive increase multiplicative decrease (AIMD) based meth-
ods [38, 101].
•
It reduces overall SLO violations by up to 16
×
compared
with Kubernetes autoscaling, and 9
×
compared with the
AIMD-based method, while reducing the overall requested
CPU by as much as 62%.
•
It outperforms the AIMD-based method by up to 9
×
and
Kubernetes autoscaling by up to 30
×
in terms of the time
to mitigate SLO violations.
•
It improves overall performance predictability by reducing
the average tail latencies up to 11×.
•
It successfully localizes SLO violation root-cause microser-
vice instances with 93% accuracy on average.
FIRM mitigates SLO violations without overprovisioning
because of two main features. First, it models the dependency
between low-level resources and application performance in
an RL-based feedback loop to deal with uncertainty and noisy
measurements. Second, it takes a two-level approach in which
the online critical path analysis and the SVM model filter
only those microservices that need to be considered to miti-
gate SLO violations, thus making the framework application-
architecture-agnostic as well as enabling the RL agent to be
trained faster.
2 Background & Characterization
The advent of microservices has led to the development and
deployment of many web services that are composed of “mi-
cro,” loosely coupled, intercommunicating services, instead
of large, monolithic designs. This increased popularity of
service-oriented architectures (SOA) of web services has been
made possible by the rise of containerization [21,70, 92, 108]
and container-orchestration frameworks [19,20,90, 119] that
enable modular, low-overhead, low-cost, elastic, and high-
efficiency development and production deployment of SOA
microservices [8,9,33,34,46,68,77,89,104]. A deployment of
806 14th USENIX Symposium on Operating Systems Design and Implementation USENIX Association

















评论0