mm姿势:使用mmWave雷达和CNN的实时人体骨骼姿势估计1
需积分: 0 139 浏览量
2022-08-04
12:02:48
上传
评论
收藏 3.41MB PDF 举报

1558-1748 (c) 2020 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/JSEN.2020.2991741, IEEE Sensors
Journal
IEEE SENSORS JOURNAL, VOL. XX, NO. XX, XXXX 2020 1
mm-Pose: Real-Time Human Skeletal Posture
Estimation using mmWave Radars and CNNs
Arindam Sengupta, Student Member, IEEE, Feng Jin, Student Member, IEEE,
Renyuan Zhang, Student Member, IEEE, and Siyang Cao, Member, IEEE
Abstract—In this paper, mm-Pose, a novel approach to detect
and track human skeletons in real-time using an mmWave radar,
is proposed. To the best of the authors’ knowledge, this is the
first method to detect >15 distinct skeletal joints using mmWave
radar reflection signals. The proposed method would find several
applications in traffic monitoring systems, autonomous vehicles,
patient monitoring systems and defense forces to detect and track
human skeleton for effective and preventive decision making
in real-time. The use of radar makes the system operationally
robust to scene lighting and adverse weather conditions. The
reflected radar point cloud in range, azimuth and elevation
are first resolved and projected in Range-Azimuth and Range-
Elevation planes. A novel low-size high-resolution radar-to-image
representation is also presented, that overcomes the sparsity
in traditional point cloud data and offers significant reduction
in the subsequent machine learning architecture. The RGB
channels were assigned with the normalized values of range,
elevation/azimuth and the power level of the reflection signals for
each of the points. A forked CNN architecture was used to predict
the real-world position of the skeletal joints in 3-D space, using
the radar-to-image representation. The proposed method was
tested for a single human scenario for four primary motions, (i)
Walking, (ii) Swinging left arm, (iii) Swinging right arm, and (iv)
Swinging both arms to validate accurate predictions for motion
in range, azimuth and elevation. The detailed methodology,
implementation, challenges, and validation results are presented.
Index Terms—Convolutional Neural Networks, mmWave
Radars, Posture Estimation, Skeletal Tracking
I. INTRODUCTION
W
ITH the advent in computing resources and advanced
machine learning (ML) techniques, computer vision
(CV) has emerged as an exciting field of research to pro-
vide Artifical Intelligence (AI) and autonomous machines
with information about the visual representation of the real
world [1], [2]. Primarily using vision based sensors, such as
monocular camera, Red-Green-Blue-Depth (RGBD) camera or
Infra-Red (IR) based sensors, and applied machine learning,
CV targets several applications, including (but not limited to)
object classification, target tracking, traffic monitoring and
autonomous vehicles [3]–[7]. In the recent years, another
interesting topic that the CV community has been exploring
is the ability to estimate human skeletal pose by identifying
and detecting specific joints and/or body parts from still/video
data. This specific area of research finds several applications,
one being primarily in the health-care industry by automating
patient monitoring systems, with the current situation of global
shortage in nursing staff [8]. Such tracking systems would
A. Sengupta, F. Jin, R. Zhang and S. Cao are with the Department of
Electrical and Computer Engineering, University of Arizona, Tucson, AZ,
85721 USA. e-mail: (sengupta,fengjin,ryzhang,caos)@email.arizona.edu
Radar
mm−Wave
Radar
mm−Wave
mm−Pose
Autonomous Vehicles
carrying mmWave Radar
Pedestrian detected by Autonomous Vehicles
Pedestrian detected by Traffic Monitoring System
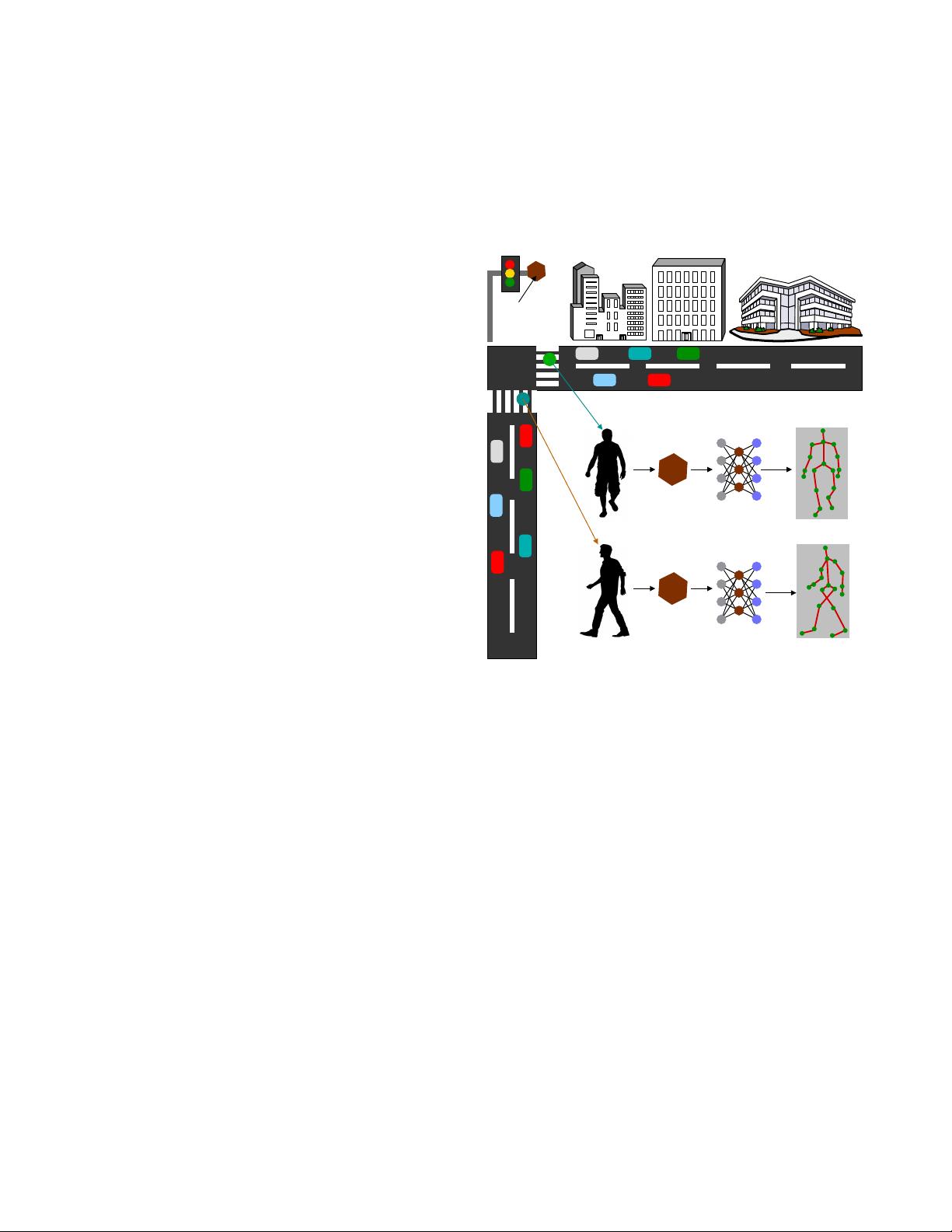
Fig. 1. mm-Pose can be used in autonomous/ semi-autonomous vehicles and
traffic monitoring systems for robust skeletal posture estimation of pedestrians,
represented in green and blue dot on the crosswalk, respectively.
also allow for effective pedestrian monitoring for autonomous
and semi-autonomous vehicles, and aid defense forces with
behavioral information of the adversary, to trigger appropriate
preventive decision making.
While vision based sensors provide a high-resolution repre-
sentation of the scene, there are a few challenges associated
with their operation. They heavily rely on (or influenced by)
external sources for illuminating the scene and are there-
fore rendered ineffective in poor lighting conditions, adverse
weather conditions or when the scene/target is occluded [9].
These could result in irrevocable catastrophic events similar
to the ones encountered at (i) Tesla’s autopilot testing, where
the vision sensors failed to detect the white side of a tractor
trailer in brightly lit sky (very high reflectivity) [10] , and (ii)
Uber self-driving vehicle crash incident in Arizona due to the
vision/LiDAR sensors’ inability to detect the pedestrian in time
to avoid the accident during a night test (low/no reflectivity)
[11]. There is therefore an imminent need for alternate sensors
to achieve the task, while overcoming the aforementioned
challenges.
Radio Frequency (RF) based sensors, such as radars, use its
own signals to illuminate the target (active sensing), therefore
making it operationally robust to scene lighting and weather
conditions. However, unlike vision based sensors, radars rep-
Authorized licensed use limited to: University of Newcastle. Downloaded on June 02,2020 at 19:56:26 UTC from IEEE Xplore. Restrictions apply.


剩余11页未读,继续阅读






评论0
最新资源