【Spark调优篇01】Spark之常规性能调优1
需积分: 0 66 浏览量
2022-08-04
16:22:51
上传
评论
收藏 607KB PDF 举报

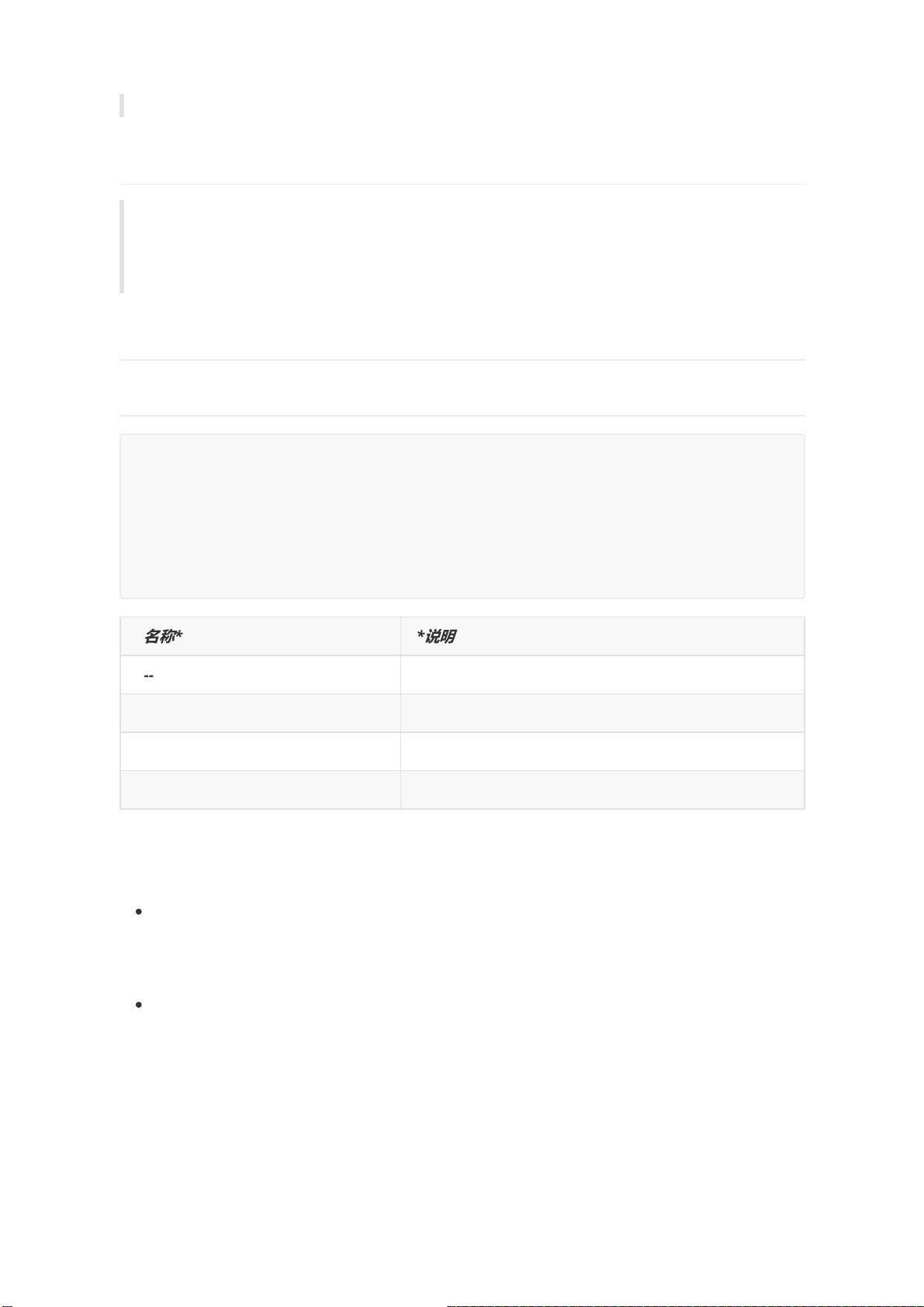
*
名
称
* *
说
明
*
*--num-executors* 配置Executor的数量
*--driver-memory* 配置Driver内存(影响不大)
*--executor-memory* 配置每个Executor的内存大小
*--executor-cores* 配置每个Executor的CPU core数量
思考何为抽象?
Spark之常规性能调优
Spark性能调优的第一步,就是为任务分配更多的资源【核心】,在一定范围内,增加资源的分
配与性能的提升是成正比的,实现了最优的资源配置后,在此基础上再考虑进行后面论述的性能
调优策略。资源的分配在使用脚本提交Spark任务时进行指定,标准的Spark任务提交脚本如代码
清单2-1所示:
调优1:最优资源配置
标准Spark提交脚本
调节原则:尽量将任务分配的资源调节到可以使用的资源的最大限度。
对于具体资源的分配,我们分别讨论Spark的两种Cluster运行模式:
第一种是Spark Standalone模式,你在提交任务前,一定知道或者可以从运维部门获取到你可以
使用的资源情况,在编写submit脚本的时候,就根据可用的资源情况进行资源的分配,比如说集
群有15台机器,每台机器为8G内存,2个CPU core,那么就指定15个Executor,每个Executor分
配8G内存,2个CPU core。
第二种是Spark Yarn模式,由于Yarn使用资源队列进行资源的分配和调度,在表写submit脚本的
时候,就根据Spark作业要提交到的资源队列,进行资源的分配,比如资源队列有400G内存,100
个CPU core,那么指定50个Executor,每个Executor分配8G内存,2个CPU core。
对表2-1中的各项资源进行了调节后,得到的性能提升如表2-2所示:
/usr/opt/modules/spark/bin/spark-submit \
--class com.atguigu.spark.Analysis \
--num-executors 80 \
--driver-memory 6g \
--executor-memory 6g \
--executor-cores 3 \
/usr/opt/modules/spark/jar/spark.jar \













评论0