MySQL数据库1

需积分: 0 94 浏览量
更新于2022-08-08
收藏 2.59MB DOCX 举报
MySQL数据库是广泛应用于IT行业的关系型数据库管理系统,其在数据存储和检索方面有着高效和可靠的表现。本篇文章将深入探讨数据库设计的三大范式、InnoDB存储引擎的数据页结构以及索引的重要性和创建原则。
数据库设计的三大范式是确保数据结构合理化和减少数据冗余的关键。第一范式强调字段的原子性,即每个字段的值应该是不可再分的最小单位。第二范式要求表中的每一列都与主键相关,避免部分依赖,以防止数据不一致。第三范式规定所有非主键列必须直接依赖于主键,而非其他非主键列,减少间接依赖,进一步减少冗余。这三种范式的应用有助于构建清晰、高效、易于维护的数据库结构。
接着,我们来了解InnoDB存储引擎的数据读写机制。InnoDB的数据是以数据页为单位进行读写的,每个数据页默认大小为16KB。这意味着,无论是读取还是写入,数据库都会以页为单位进行操作。数据页不仅存储记录,还包含页目录,用于加速记录的检索。页目录通过将记录分成多个组,每个组的最后一条记录作为分组的最大记录,并存储组内记录数。通过页目录的槽,可以使用二分法快速定位目标记录,减少全页扫描的时间。
创建索引是提高数据库性能的关键。唯一性索引确保表中每一行数据的唯一性,避免重复数据。同时,索引能够极大地提升数据检索速度,尤其是在处理大量数据时。索引可以帮助数据库避免对数据进行排序和创建临时表,从而优化查询性能。创建索引时,应遵循一些原则:选择唯一性索引,因为它们能提供更快的查询速度;避免在高变异性或更新频繁的列上创建索引,因为这会增加维护成本;考虑使用覆盖索引,即索引包含了查询所需的所有列,这样可以减少磁盘I/O。
MySQL数据库通过遵循数据库设计的三大范式,确保了数据的规范性;InnoDB存储引擎的数据页结构优化了数据读写效率;而索引的创建则显著提升了查询性能。理解并熟练运用这些概念,对于设计和管理高性能的MySQL数据库至关重要。在实际应用中,根据业务需求和数据特性,灵活运用这些知识,能够极大地提升数据库系统的效率和稳定性。
1
数据库设计三大范式
1.1. 第一范式(确保每列保持原子性)
如果数据库表中的所有字段值都是不可分解的原子值,该数据库表满足了第一范式。
1.2. 第二范式(确保表中的每列都和主键相关)
第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关
(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,
不可以把多种数据保存在同一张数据库表中。
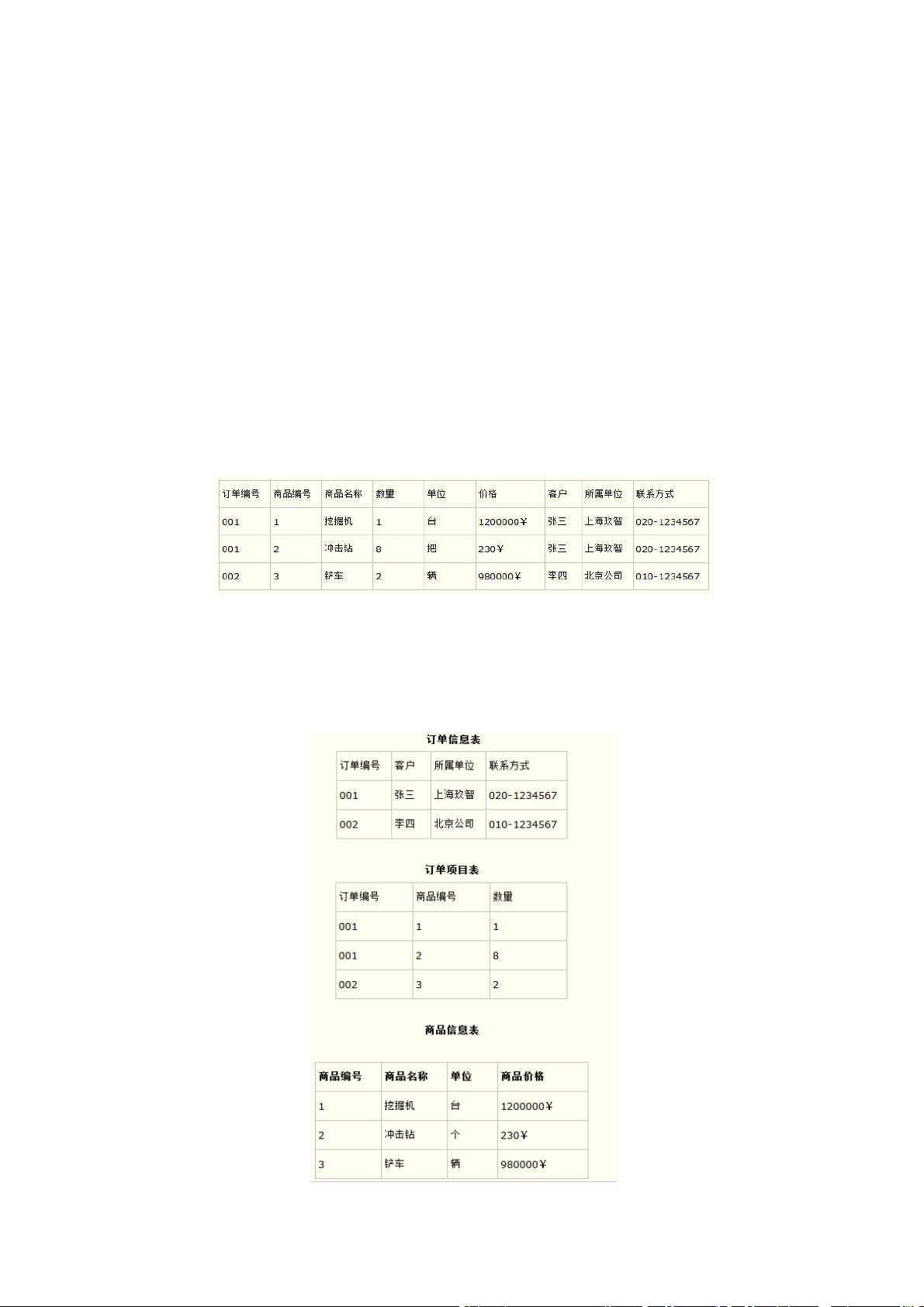
比如要设计一个订单信息表,将订单编号和商品编号作为数据库表的联合主键。
产生一个问题:这个表中是以订单编号和商品编号作为联合主键。这样在该表中商品名
称、单位、商品价格等信息不与该表的主键相关,而仅仅是与商品编号相关。所以在这里
违反了第二范式的设计原则。而如果把这个订单信息表进行拆分,把商品信息分离到另一
个表中,把订单项目表也分离到另一个表中,就非常完美了。如下所示。



剩余33页未读,继续阅读
119 浏览量
192 浏览量
2020-12-14 上传
196 浏览量
195 浏览量
183 浏览量
2013-04-07 上传
165 浏览量
2018-06-25 上传
133 浏览量
109 浏览量
156 浏览量
2020-12-14 上传
158 浏览量
201 浏览量
2019-07-30 上传
资源评论


ask_ai_app
- 粉丝: 24
- 资源: 326









最新资源
- AutoTrack的Matlab v10实现.zip
- BB_PD是用MATLAB和C语言开发的基于三维键合的周动力学代码.zip
- BeMoBIL Pipeline是一个用于分析和可视化移动脑体成像数据的MATLAB工具箱,它包括EEGLAB和MOB.zip
- BP神经网络预测实例matlab.zip
- CALFEM一个有限元工具箱的MATLAB.zip
- brainPlot是一个MATLAB函数,用于创建简单的线性脑图.zip
- CSTMATLABAPI.zip
- C和MATLAB实现的Polar编码和解码.zip
- CST微波工作室MATLAB接口.zip
- Dirichlet过程混合模型的Matlab采样和变分代码.zip
- Defocus画像利用深度推定.zip
- DCTFFT压缩与均值滤波中值滤波高斯滤波二维统计滤波自适应中值滤波维纳滤波kNN滤波NLMeans滤波的matlab.zip
- DistMesh简单的2D和3D网格生成器的MATLAB和Octave与GUI支持.zip
- G Bacci L Sanguinetti和M Luise中使用的图形和示例的Matlab代码,通过无线电源控制理解博.zip
- EigTool是开放的MATLAB软件,用于分析矩阵的特征值、伪谱和相关的谱特性.zip
- GISMO地震数据分析工具箱的MATLAB.zip
