

Apache Spark研究报告
1. Spark简介
Apache Spark是个围绕速度、性和复杂分析构建的数据处框架。最初在2009
由加州学伯克分校的AMPLab开发,并于2010成为Apache的开源项之。!
Spark扩展泛使的MapReduce计算模型,且效地持多计算模式,包括交
互式查询和流处。在处规模数据集时,速度是常重要的。速度快就意味着可以进交
互式的数据操作,否则每次操作就需要等待数分钟甚数时。Spark的个主要特点就是能
够在内存中进计算,因MapReduce快。过即使是必须在磁盘上进的复杂计算,
Spark依然MapReduce加效。!
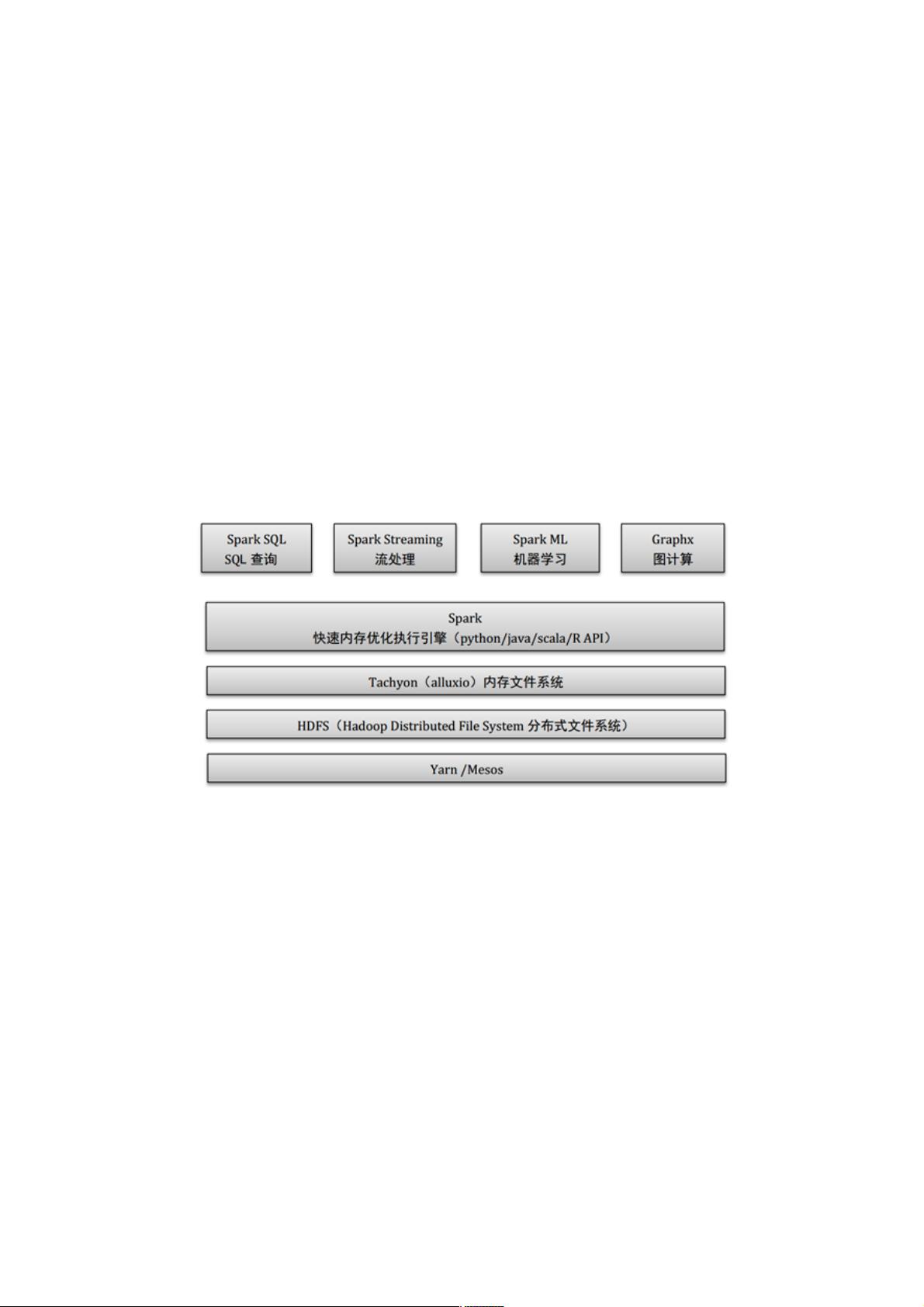
Spark适于各种各样原先需要多种同的分布式平台的场景,包括批处、迭代算法、
交互式查询、流处。通过在个统的框架下持这些同的计算,Spark使我们可以简单
且低耗地把各种处流程整合在起。这样的组合,在实际的数据分析过程中很有意义。仅
如此,Spark的这种特性还减轻原先需要对各种平台分别管的负担。!
Spark提供的接常丰富。除提供基于Scala、Java、Python和SQL的简单的API
以及內建丰富的程序库外,Spark还能和其他数据作密切配合使。如,Spark可以运
在Hadoop集群上,访问包括Cassandra在内的任意Hadoop数据源。!
2. Spark⽬前发展应⽤情况
对于个具有相当技术槛与复杂度的平台,Spark从诞到正式版本的成熟,经历的时
间如此之短,让感到惊诧。2009,Spark诞于加州伯克学AMPLab,最开初属于加
州伯克学的研究性项。它于2010正式开源,并于2013成为Aparch基项,并
于2014成为Aparch基的顶级项,整个过程到五时间。!
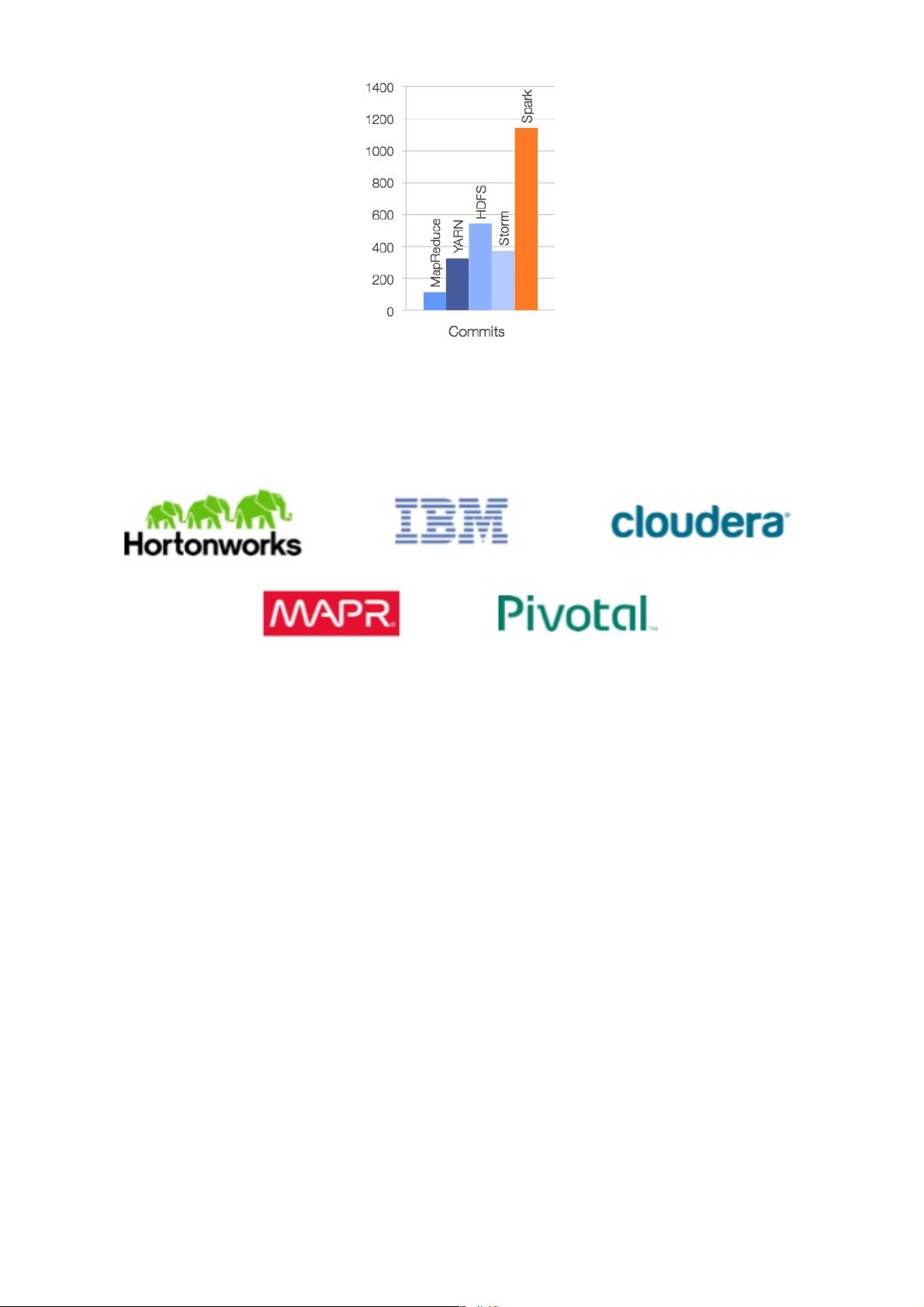
从Spark的版本演化看,以说明这个平台旺盛的命以及社区的活跃度。尤其在2013
来,Spark进个速发展期,代码库提交与社区活跃度都有显著增。以活跃度论,
Spark在所有Aparch基会开源项中,位前三。相较于其他数据平台或框架,
Spark的代码库最为活跃。!
APACHE SPARK研究报告
!1
剩余15页未读,继续阅读













评论0