关于2015阿里移动推荐算法大赛的总结1
需积分: 0 9 浏览量
2022-08-08
23:12:10
上传
评论
收藏 879KB DOCX 举报


关于 2015 阿里移动推荐算法大赛的总结(一)
写在最前面,第一场比赛的第一轮早已结束,lz 组的团队已被淘汰~跟 lz 组队的人跟 lz
一样也是新手菜鸟,参加比赛只是兴趣与好奇。现在第二场比赛开始了,lz 还会继续玩下
去(虽然 lz 校内科研、项目压力都很大)~
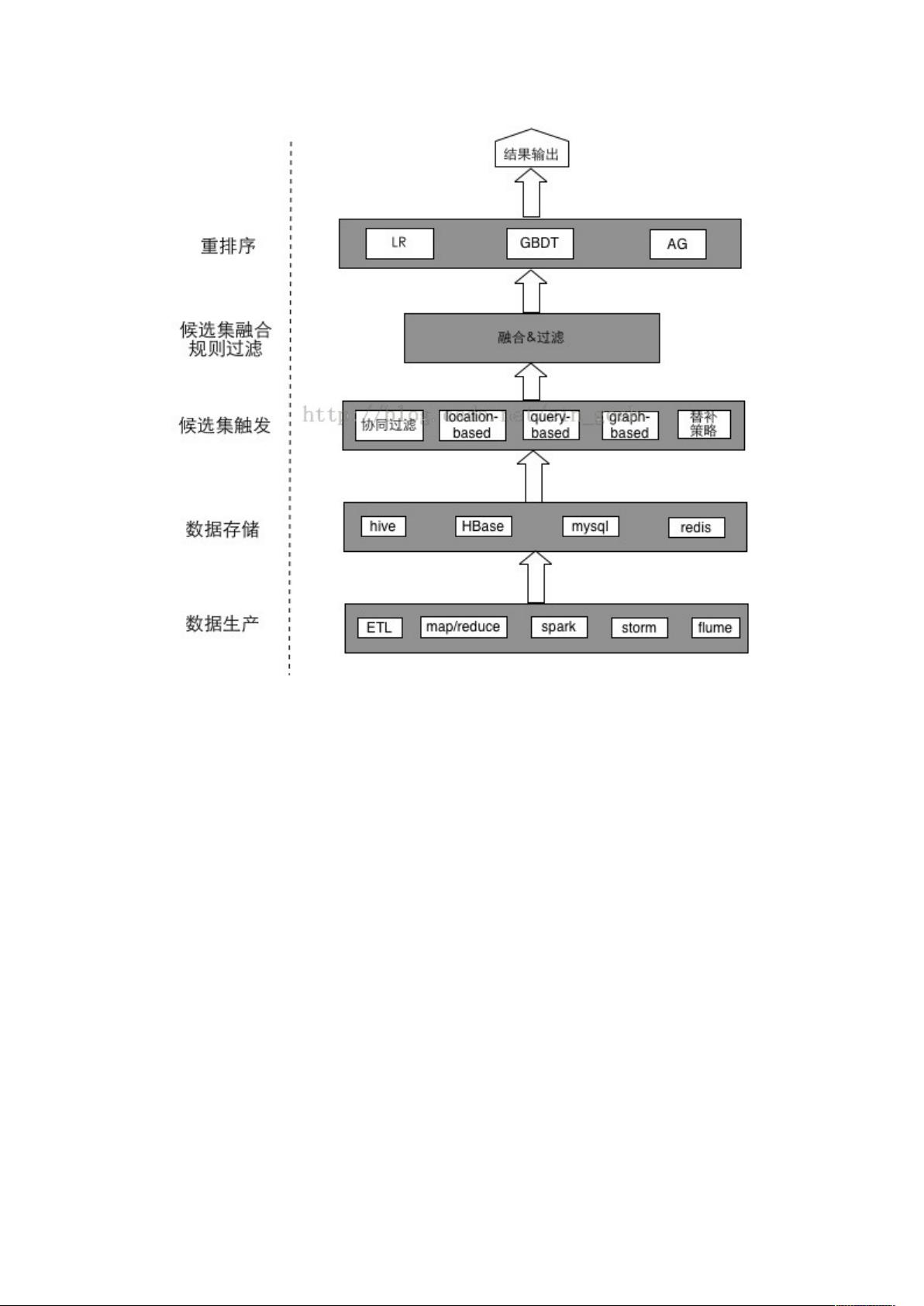
官方给了两个集合表——用户在商品全集上的移动端行为数据表和商品子集表。行为数据
里面分别有用户名、商品名、行为类型(浏览、收藏、加购物车、购买)、地理位置、商
品类别、行为时间。商品子集里面有商品名、商品类别、地理位置。
题目是根据官方给的一个月的用户行为数据,预测这个月过完的第一天在商品子集中用户
可能购买的商品。评分使用的是正确率与召回率的加权。
首先,我们想到的是根据行为的统计特征进行购买的预测,简单的说就是假如用户加入购
物车,那么购买的可能性就很大,收藏,浏览产生购买行为的可能性递减。
同时还有地理位置这组信息,从经验判断,地理位置相近购买可能性也越大,在武汉的童
鞋一般不会买杭州的电影票或者餐券吧。(这里要说明下,因为是移动端行为数据,很大
一部分是类似电影票、门票、代金券、外卖等等商品,当然也肯定会有我们熟知的淘宝物
品。)
还有一点,很显然商品子集里的商品是行为数据表中商品的子集(也就是说假如购买了
pad,会继续购买个 pad 套,而这个 pad 套在子集里,pad 只在行为数据表里,需要寻
找出这样一种规律)。
初期,我们把侧重点放在题目的“推荐”两个字上了,搜集并研究了大量的“推荐算
法”,然后也分析整理出了一套模型,但是在最后要得出结果那一步发现,根本不是题目
要的结果。题目要的就是在那一天用户会购买那些商品,而不是用户可能对那些商品感兴


剩余33页未读,继续阅读













评论0