

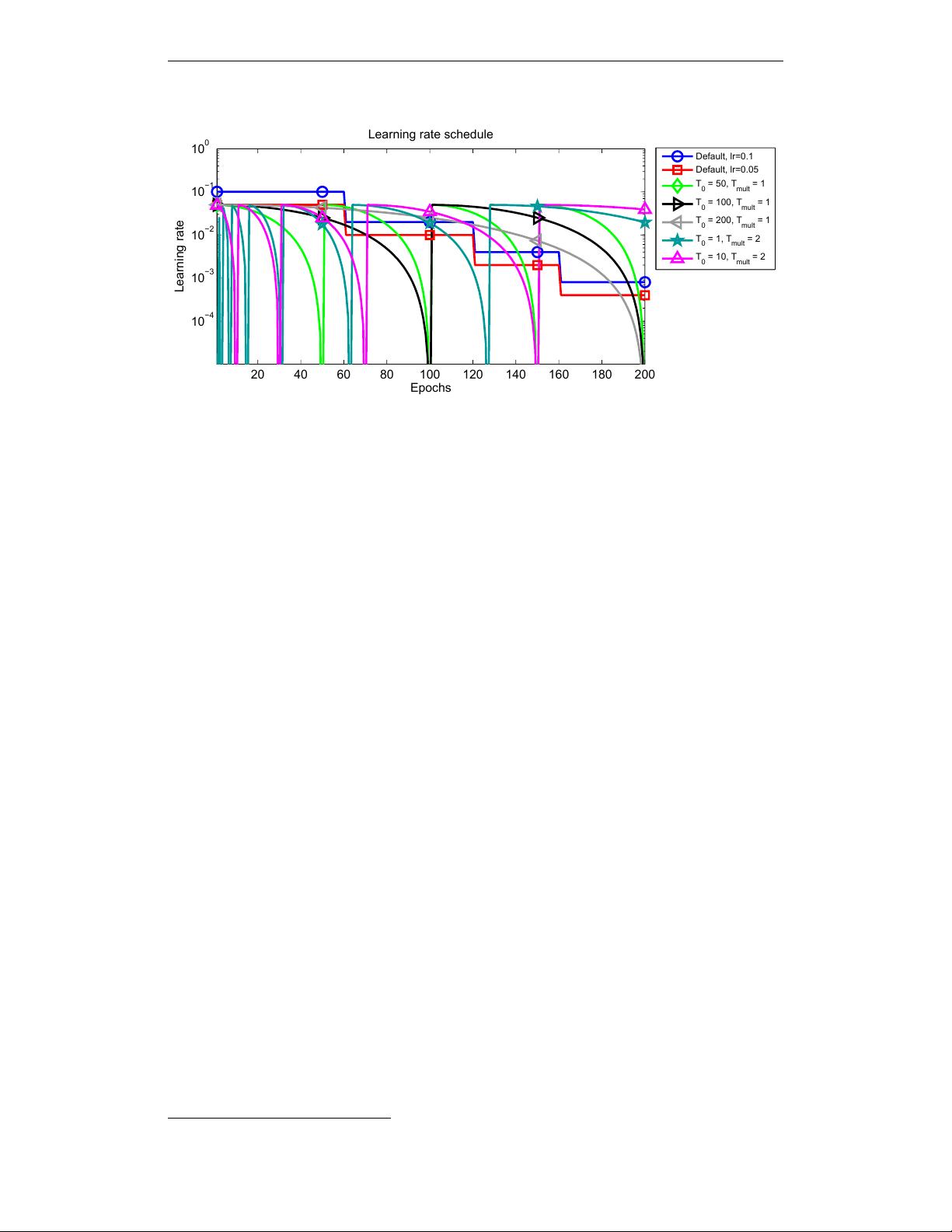
Published as a conference paper at ICLR 2017
SGDR: STOCHASTIC GRADIENT DESCENT WITH
WARM RESTARTS
Ilya Loshchilov & Frank Hutter
University of Freiburg
Freiburg, Germany,
{ilya,fh}@cs.uni-freiburg.de
ABSTRACT
Restart techniques are common in gradient-free optimization to deal with multi-
modal functions. Partial warm restarts are also gaining popularity in gradient-
based optimization to improve the rate of convergence in accelerated gradient
schemes to deal with ill-conditioned functions. In this paper, we propose a sim-
ple warm restart technique for stochastic gradient descent to improve its anytime
performance when training deep neural networks. We empirically study its per-
formance on the CIFAR-10 and CIFAR-100 datasets, where we demonstrate new
state-of-the-art results at 3.14% and 16.21%, respectively. We also demonstrate
its advantages on a dataset of EEG recordings and on a downsampled version of
the ImageNet dataset. Our source code is available at
https://github.com/loshchil/SGDR
1 INTRODUCTION
Deep neural networks (DNNs) are currently the best-performing method for many classification
problems, such as object recognition from images (Krizhevsky et al., 2012a; Donahue et al., 2014)
or speech recognition from audio data (Deng et al., 2013). Their training on large datasets (where
DNNs perform particularly well) is the main computational bottleneck: it often requires several
days, even on high-performance GPUs, and any speedups would be of substantial value.
The training of a DNN with n free parameters can be formulated as the problem of minimizing a
function f : IR
n
→ IR. The commonly used procedure to optimize f is to iteratively adjust x
t
∈ IR
n
(the parameter vector at time step t) using gradient information ∇f
t
(x
t
) obtained on a relatively
small t-th batch of b datapoints. The Stochastic Gradient Descent (SGD) procedure then becomes
an extension of the Gradient Descent (GD) to stochastic optimization of f as follows:
x
t+1
= x
t
− η
t
∇f
t
(x
t
), (1)
where η
t
is a learning rate. One would like to consider second-order information
x
t+1
= x
t
− η
t
H
−1
t
∇f
t
(x
t
), (2)
but this is often infeasible since the computation and storage of the inverse Hessian H
−1
t
is in-
tractable for large n. The usual way to deal with this problem by using limited-memory quasi-
Newton methods such as L-BFGS (Liu & Nocedal, 1989) is not currently in favor in deep learning,
not the least due to (i) the stochasticity of ∇f
t
(x
t
), (ii) ill-conditioning of f and (iii) the presence
of saddle points as a result of the hierarchical geometric structure of the parameter space (Fukumizu
& Amari, 2000). Despite some recent progress in understanding and addressing the latter problems
(Bordes et al., 2009; Dauphin et al., 2014; Choromanska et al., 2014; Dauphin et al., 2015), state-of-
the-art optimization techniques attempt to approximate the inverse Hessian in a reduced way, e.g.,
by considering only its diagonal to achieve adaptive learning rates. AdaDelta (Zeiler, 2012) and
Adam (Kingma & Ba, 2014) are notable examples of such methods.
1
arXiv:1608.03983v5 [cs.LG] 3 May 2017

剩余15页未读,继续阅读

赶路的稻草人
- 粉丝: 32
- 资源: 330









最新资源
- CC2530无线zigbee裸机代码实现按键控制LED开关.zip
- CC2530无线zigbee裸机代码实现按键控制PWM灯光强度.zip
- CC2530无线zigbee裸机代码实现按键控制流水灯.zip
- 无感FOC电机三相控制高速吹风筒方案 FU6812L+FD2504S 电压AC220V 功率80W 最高转速20万RPM 方案优势:响应快、效率高、噪声低、成本低 控制方式:三相电机无感FOC 闭环方
- CC2530无线zigbee裸机代码实现查询方式使用定时器.zip
- CC2530无线zigbee裸机代码实现串口UART0发送字符串.zip
- CC2530无线zigbee裸机代码实现串口UART0收发字符串.zip
- CC2530无线zigbee裸机代码实现串口发送指令控制LED灯.zip
- CC2530无线zigbee裸机代码实现定时器T1的使用.zip
- CC2530无线zigbee裸机代码实现定时器T3的使用.zip
- 基于51单片机的PWM波形发生器设计(Protues仿真)-毕业设计
- 模块化多电平变流器 MMC 的VSG控制 同步发电机控制 MATLAB–Simulink仿真模型 5电平三相MMC,采用VSG控制 受端接可编辑三相交流源,直流侧接无穷大电源提供调频能量 设置频率
- 锁相环学习电路,有教程 对新手非常友好,一看就懂 1,输出频率800MHz或者1GHz, 采用Ring-VCO的结构 2,输入参考频率20MHz 3,分频器是40-50分频 4,电荷泵电流
- MF000588-ASP.NET信息中心标准化管理系统源码.zip
- 基于51单片机的烟雾采集报警系统(protues仿真)-毕业设计
- 模拟器银河麒麟是基于Linux发行版Ubuntu开发的自主可控操作系统,为我国信息基础建设提供了重要支撑 截至目前,银河麒麟V10的软件仓库已经提供了大量国产软件,但在特定情况下,我们可能还是希望使用
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0