2018211582-李志毅-实验四1

需积分: 0 175 浏览量
更新于2022-08-04
收藏 955KB PDF 举报
本实验主要涵盖了三个方面的内容:RDD编程、JDBC连接MySQL数据库以及Spark Streaming的应用。这些知识点都是Apache Spark生态系统中的核心组件,对于理解和掌握大数据处理至关重要。
1. RDD编程:
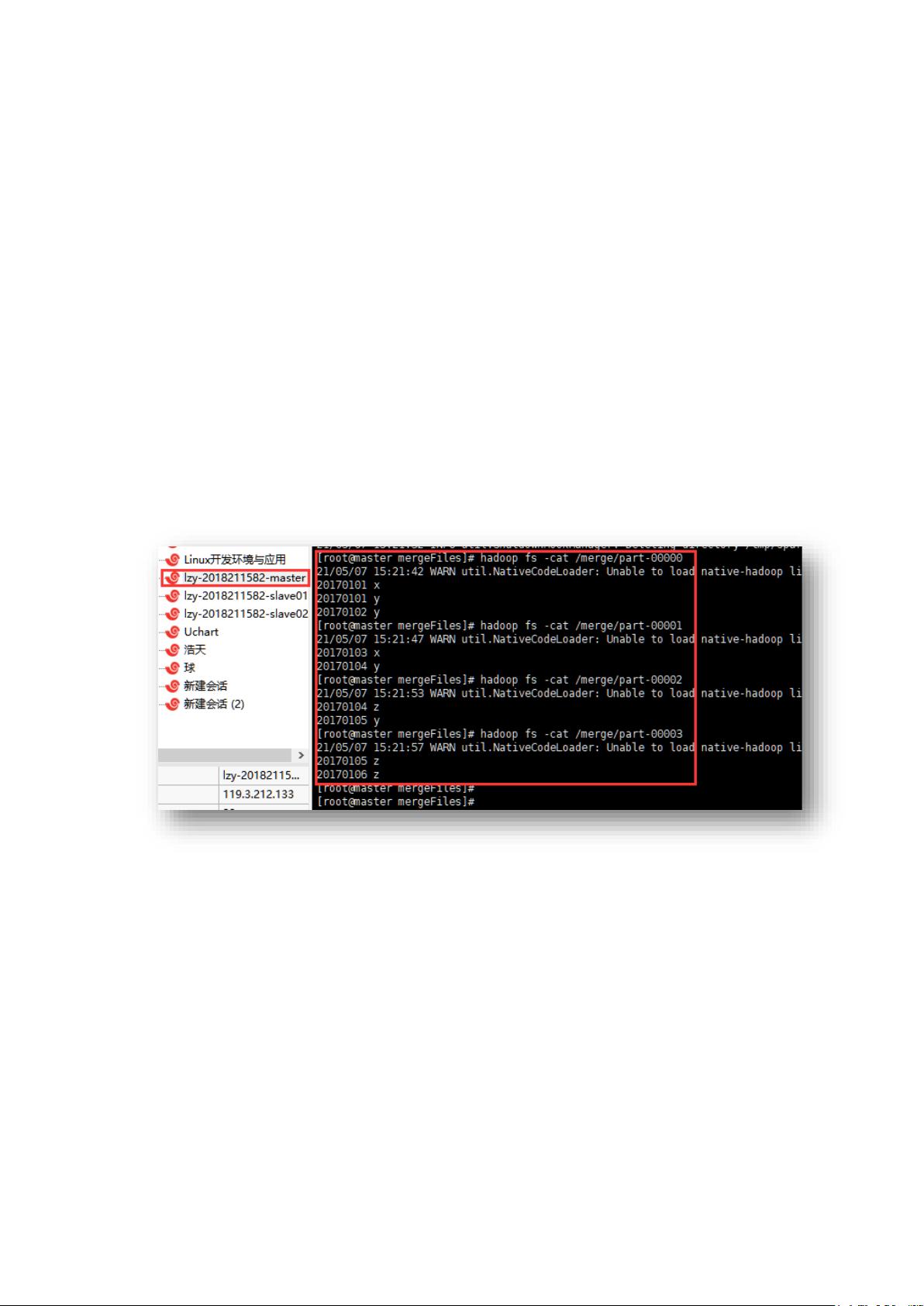
RDD(弹性分布式数据集)是Spark的基础数据结构,它是一种不可变、分区的数据集合。在实验中,学生使用Scala编写程序实现了两个文本文件的合并与去重。具体操作包括读取文件(`sc.textFile()`),使用`union`操作合并文件内容,然后通过`filter`和`map`函数对数据进行预处理,接着利用`groupByKey`进行分组,并使用`sortByKey`对结果进行排序。使用`saveAsTextFile`将结果保存到HDFS。需要注意的是,实验中提到的去重后排序问题,由于`distinct`操作并不保证顺序,所以需要额外的`sortByKey`来确保排序。
2. JDBC连接MySQL数据库:
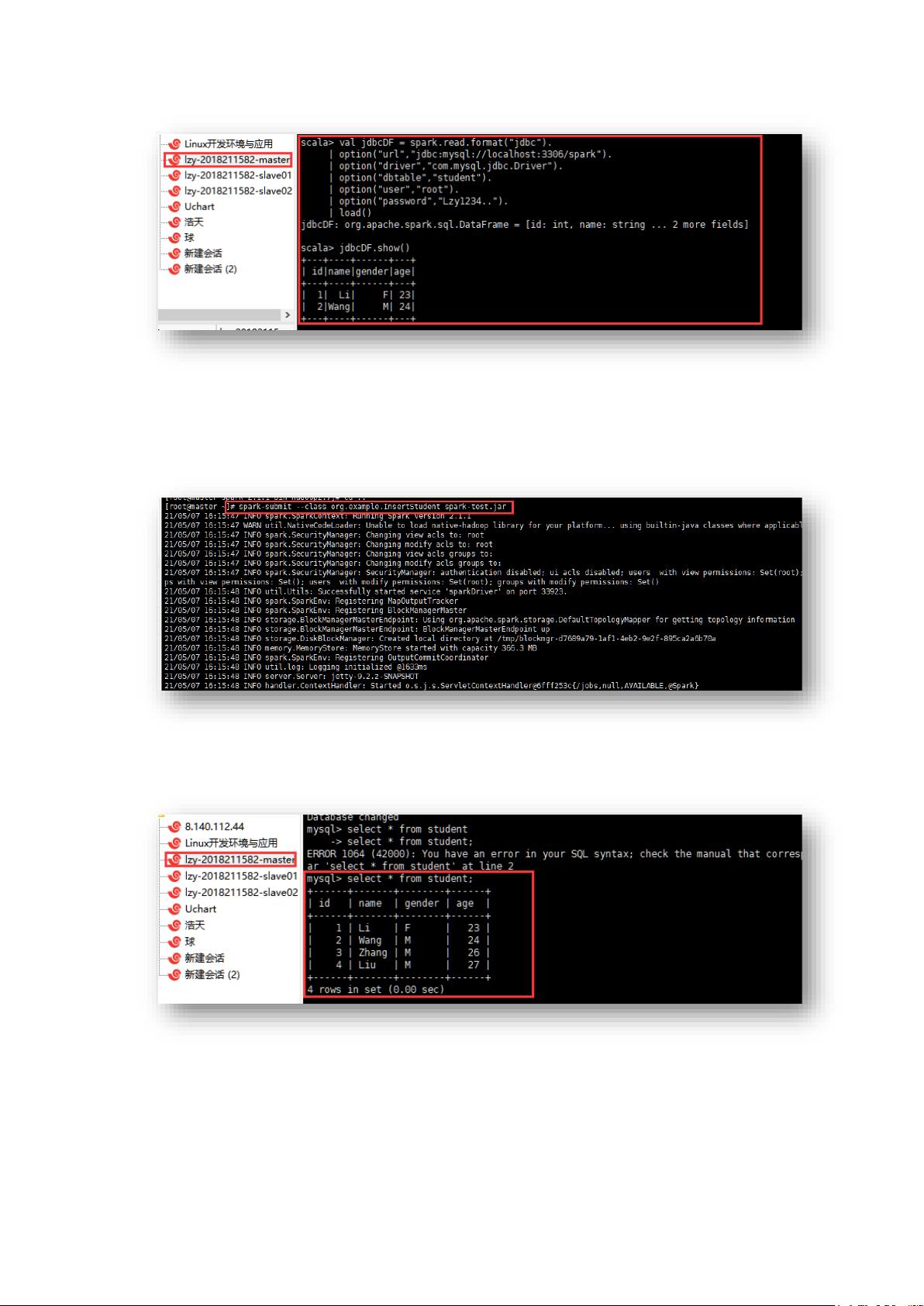
实验中涉及了在Spark中通过JDBC连接MySQL数据库,这涉及到Spark SQL的功能。需要配置Spark连接数据库的相关参数,如URL、用户名、密码等。然后,可以创建一个SQLContext对象,使用`sqlContext.read.format("jdbc")`加载数据,或者`sqlContext.jdbc()`方法直接写入数据。在实验中,学生遇到了因URL拼写错误导致的连接失败问题,这提示我们在编程时要仔细检查输入的字符串,避免类似的低级错误。
3. Spark Streaming:
Spark Streaming是Spark用于实时数据流处理的部分。实验中,学生安装并启动了Kafka,用作数据流的生产者和消费者。Scala程序作为消费者,实现了Spark Streaming的词频统计功能。Kafka作为消息中间件,接收生产者发送的词,而Spark Streaming消费者则从Kafka主题中读取数据,进行实时处理。实验展示了Spark Streaming的基本流程,包括数据接收、转换和输出。
通过这三个实验,学生不仅实践了Spark的核心功能,还学习到了如何在实际环境中配置和调试Spark应用,以及解决遇到的问题。实验中反映出的问题,如对Scala语法的不熟悉和实验步骤的疏忽,提醒我们在进行大数据处理时,应当注重代码质量,对每个步骤都进行细致的检查,同时加强基础知识的学习和积累,以提高实验效率和准确性。
课程实验四:Spark SQL、Spark
Streaming
实验时间:2021 年 05 月 07 日
学生姓名:李志毅
学生班号、学号:2018211314 班 2018211582
一、实验结果截图
RDD 编程实验结果:
图一:文件合并去重结果
JDBC 连接数据库实验结果:
剩余11页未读,继续阅读
2022-08-04 上传
156 浏览量
2022-08-03 上传
131 浏览量
137 浏览量
105 浏览量
2022-08-08 上传
2022-08-08 上传
115 浏览量
2022-08-08 上传
169 浏览量
125 浏览量
114 浏览量
资源评论


开眼旅行精选
- 粉丝: 19
- 资源: 327









最新资源
- 精益算法交易引擎由QuantConnect Python C.zip
- 可扩展的可移植和分布式梯度增强GBDT GBRT或GBM库,适用于Python R Java Scala C和更多在单.zip
- 具有静态类型的Python库存根的集合.zip
- 可移植Python数据框架库.zip
- 快速异步和优雅的Python web框架.zip
- 跨平台 Python 异步聊天机器人框架 Asynchronous multiplatform chatbot fr.zip
- 跨平台库,用于Python中的进程和系统监控.zip
- 来自一位 Pythonista 的编程经验分享内容涵盖编码技巧最佳实践与思维模式等方面.zip
- 快速正确的Python JSON库支持datetimes和numpy数据类.zip
- (C语言版)扩展卡尔曼滤波器EKF的锂电池SoC计算仿真模型 容积卡尔曼滤波CKF进行锂电池SOC估计的C语言版本实现,包含定参和FFRLS两种情况,已在VS2019和Ubuntu 20.04.4版本
- 来自Python的浏览器交互式数据可视化.zip
- 离线语音识别API Android iOS树莓派和服务器与Python Java C和Node.zip
- 利用Python进行数据分析 第二版 2017 中文翻译笔记.zip
- 领先的本地Python SSHv2协议库.zip
- 灵活而强大的Python数据分析操作库,提供类似于R数据框架对象的标记数据结构,统计函数等等.zip
- 流行的机器学习算法的Python示例与交互式Jupyter演示和数学解释.zip
