第十一章1

需积分: 0 119 浏览量
更新于2022-08-08
收藏 343KB DOCX 举报
在本章中,我们主要探讨了DNA_ETL与元基索引ETL的中文脚本编译机制,以及与其相关的PLETL语言、Tinshell、德塔编译机和OSGI插件的肽化方式。这些概念都是在构建高效、灵活的数据处理系统中的关键组成部分。
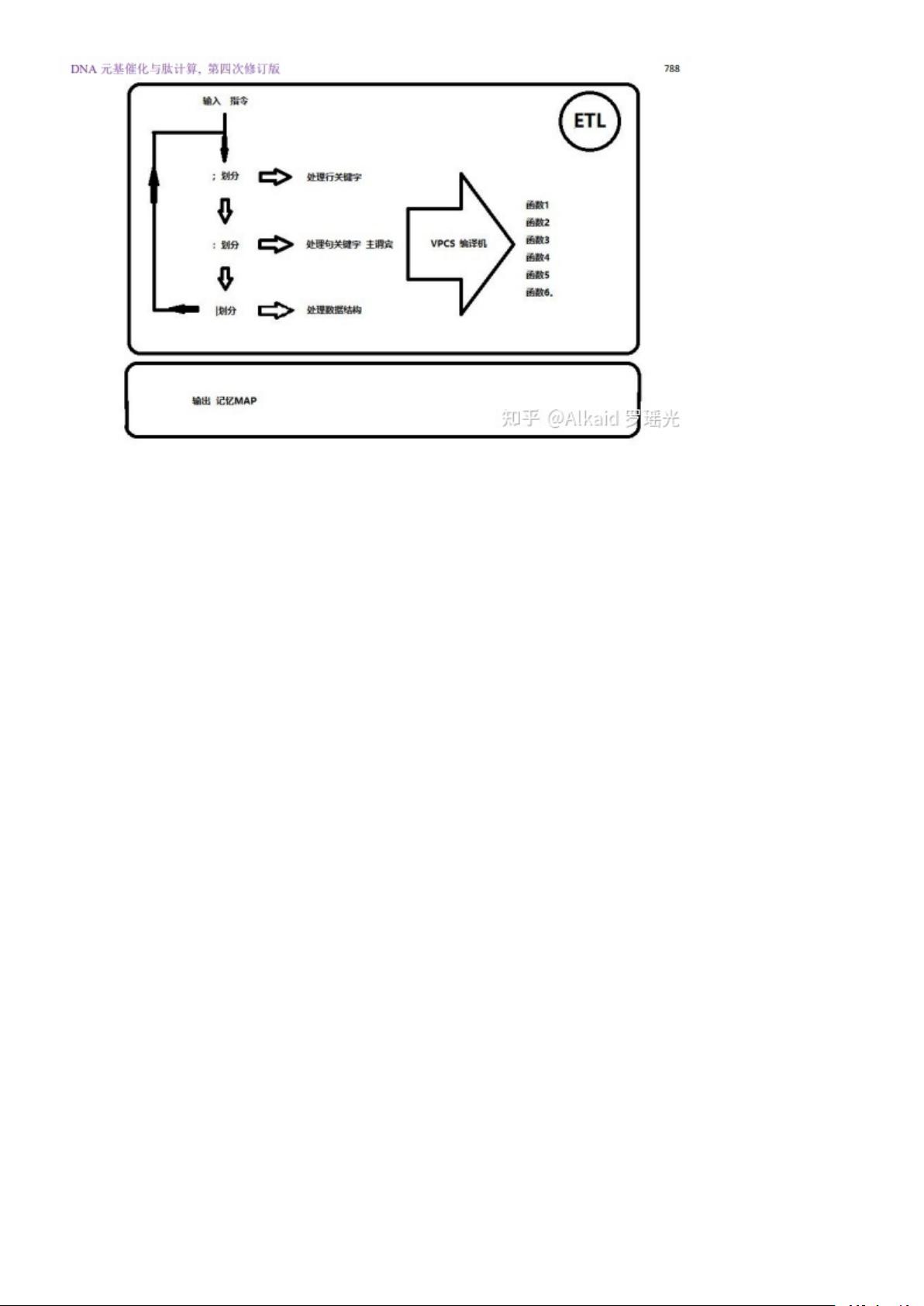
DNA_ETL是一种ETL(提取、转换、加载)工具,它的编码方式继承了德塔数据库的语言编译机。这使得DNA_ETL的编码字符串可以自定义为中文描述,增强了可读性和易用性。此外,DNA_ETL的编码行可以在单独的节点中执行,或者拆分成节点模式单行进行ETL流程执行,这提供了高度的灵活性和模块化。
PLETL语言作为DNA_ETL的基础,它不仅继承了德塔数据库的编译机语言,还进行了扩展,支持TCP、正则表达式等网络协议和操作。PLETL语言还具有多语种命令设计能力,能够满足复杂的数据处理需求。同时,PLETL语言的节点流编译机甚至可以模拟神经网络语言,用于满足特定的计算需求。
Tinshell是PLETL语言下的一套基础组件,专注于脚本的编译和执行。它基于德塔数据库的语言编译机进行了改造,主要用于处理脚本输入和计算输出的IO计算。Tinshell的引入使得脚本处理更加高效和便捷。
德塔编译机起源于德塔Socket流可编程数据库系统的PLSQL编译机,随着时间的推移,它逐渐演变为独立的脚本编码编译机,并在与ETL、TCP等技术的结合中不断扩展功能。在肽化索引之后,德塔编译机还被应用于神经元ETL节点网络计算中枢的模拟,进一步提升数据处理的智能程度。
OSGI插件的肽化方式最初是为了实现类似KNIME的节点导入功能,但最终并未完全实现。尽管如此,OSGI插件通过classloader技术实现了节点的插件化,最近开始采用肽化索引来帮助classloader识别和分类节点文件。
DNA_ETL中的神经元计算模拟是一种有向节点拓扑计算方法。在这个模型中,节点不再是计算的主体,而是承载计算任务的单元。计算的核心是单一或多个Tinshell命令,它们可以被加载到一个或多个节点中,形成复杂的计算流程。
以上内容涉及的技术和概念均出自罗瑶光及其合作作者的研究成果,他们对相关软件系统进行了版权登记,确保了知识产权的保护。这些技术的应用和发展,对于构建先进的数据处理和分析平台具有重要意义,尤其是在人工智能和大数据领域。
第十一章_DNA_ETL 与元基索引 ETL 中文脚本编译机.
ETL 元基编码方式,
1 DNA_ETL 的编码继承了德塔数据库的语言编译机。refer page 413,788
2 DNA_ETL 的编码字符串可以自由设计,如中文描述。refer page 834,835
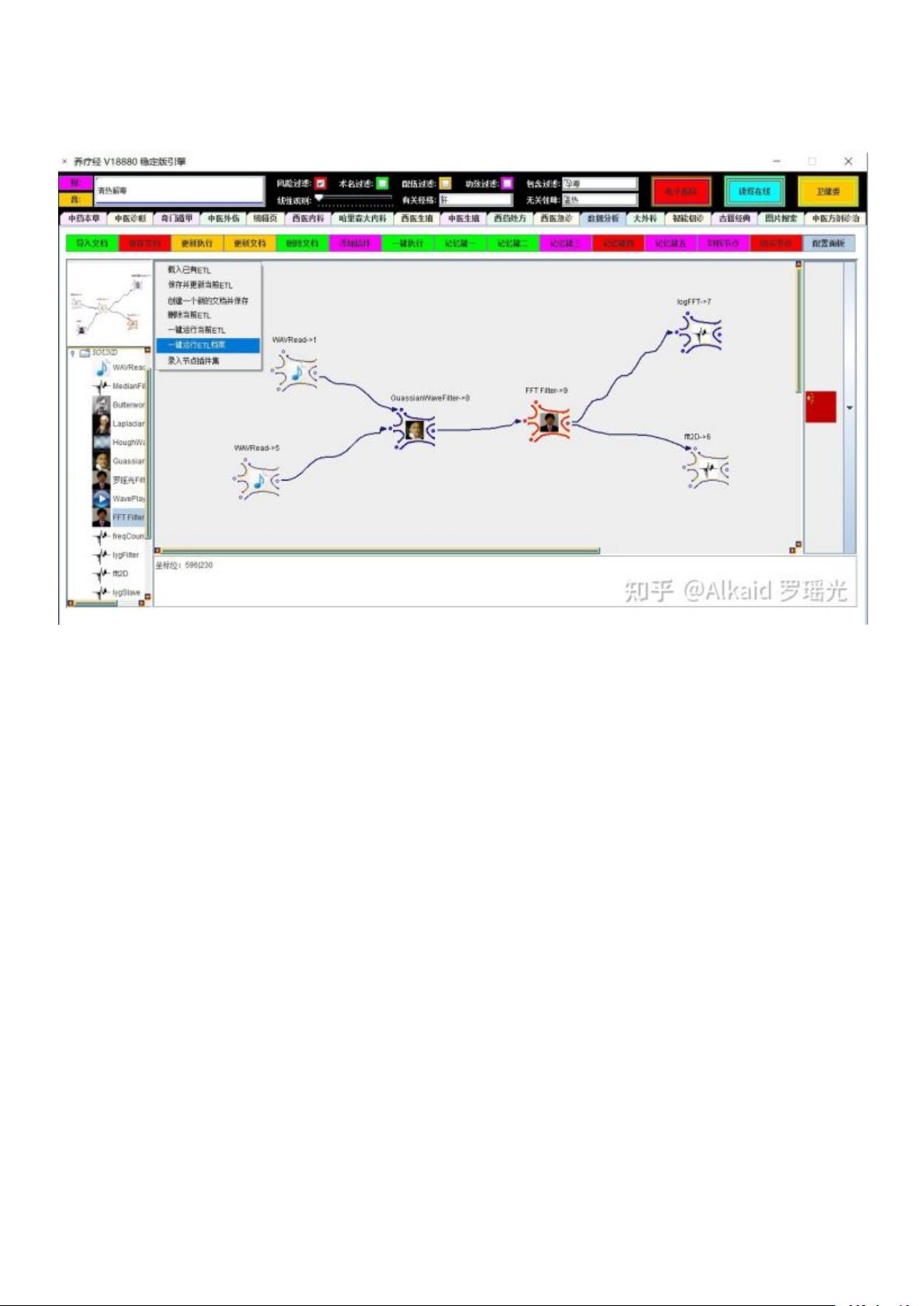
3 DNA_ETL 的编码行可以集成在节点中 etl 单个 执行。refer page 782
4 DNA_ETL 的编码可以拆卸成节点模式单行进行 etl 流 执行。refer page 784
PLETL 语言,
1 PLETL 语言 继承了德塔数据库的语言编译机语言。refer page 377,786
2 PLETL 语言 扩展了德塔数据库的语言编译机语言,如 TCP, REGEX 应用等。refer page 784
3 PLETL 语言 支持多语种 命令设计。refer page 789,790
剩余6页未读,继续阅读
资源评论


销号le
- 粉丝: 35
- 资源: 289









最新资源
- SIMULINK 基于反推控制速度控制器的永磁同步电机控制系统研究
- springboot037基于SpringBoot的墙绘产品展示交易平台的设计与实现.zip
- springboot239华府便利店信息管理系统_0303173844.zip
- springboot239华府便利店信息管理系统.zip
- springboot038基于SpringBoot的网上租赁系统设计与实现.zip
- 关于AUTOSAR组织结构的介绍ppt
- 三菱FX3U与台达变频器通讯 器件:三菱FX3U PLC+F X3U 485BD板,台达VFD变频器,昆仑通态触摸屏 功能:采用485方式,modbus RTU协议,对台达变频器频率设定,正反转,点动
- springboot040社区医院信息平台.zip
- springboot039基于Web足球青训俱乐部管理后台系统开发.zip
- springboot240基于Spring boot的名城小区物业管理系统.zip
- springboot041师生健康信息管理系统.zip
- springboot242基于SpringBoot的失物招领平台的设计与实现.zip
- 基于三菱PLC和组态王供暖控制系统热器控制 带解释的梯形图程序,接线图原理图图纸,io分配,组态画面
- springboot241基于SpringBoot+Vue的电商应用系统的设计与实现.zip
- C++、基于OpenCV和MFC框架的口罩缺陷检测.zip
- springboot042IT技术交流和分享平台的设计与实现.zip
