

Hadoop
源代码分析(一)
关键字分布式云计算
的核心竞争技术是它的计算平台。 的大牛们用了下面 篇文章,介绍了它们的计算设施。
:
:
:
:
:
很快,! 上就出现了一个类似的解决方案,目前它们都属于 ! 的 " 项目,对应的分别是:
##$%&
##$"'
##$"
##$"
目前,基于类似思想的 () 项目还很多,如 * 用于用户分析的 "。
"' 作为一个分布式文件系统,是所有这些项目的基础。分析好 "',有利于了解其他系统。由于 " 的 "' 和
是同一个项目,我们就把他们放在一块,进行分析。
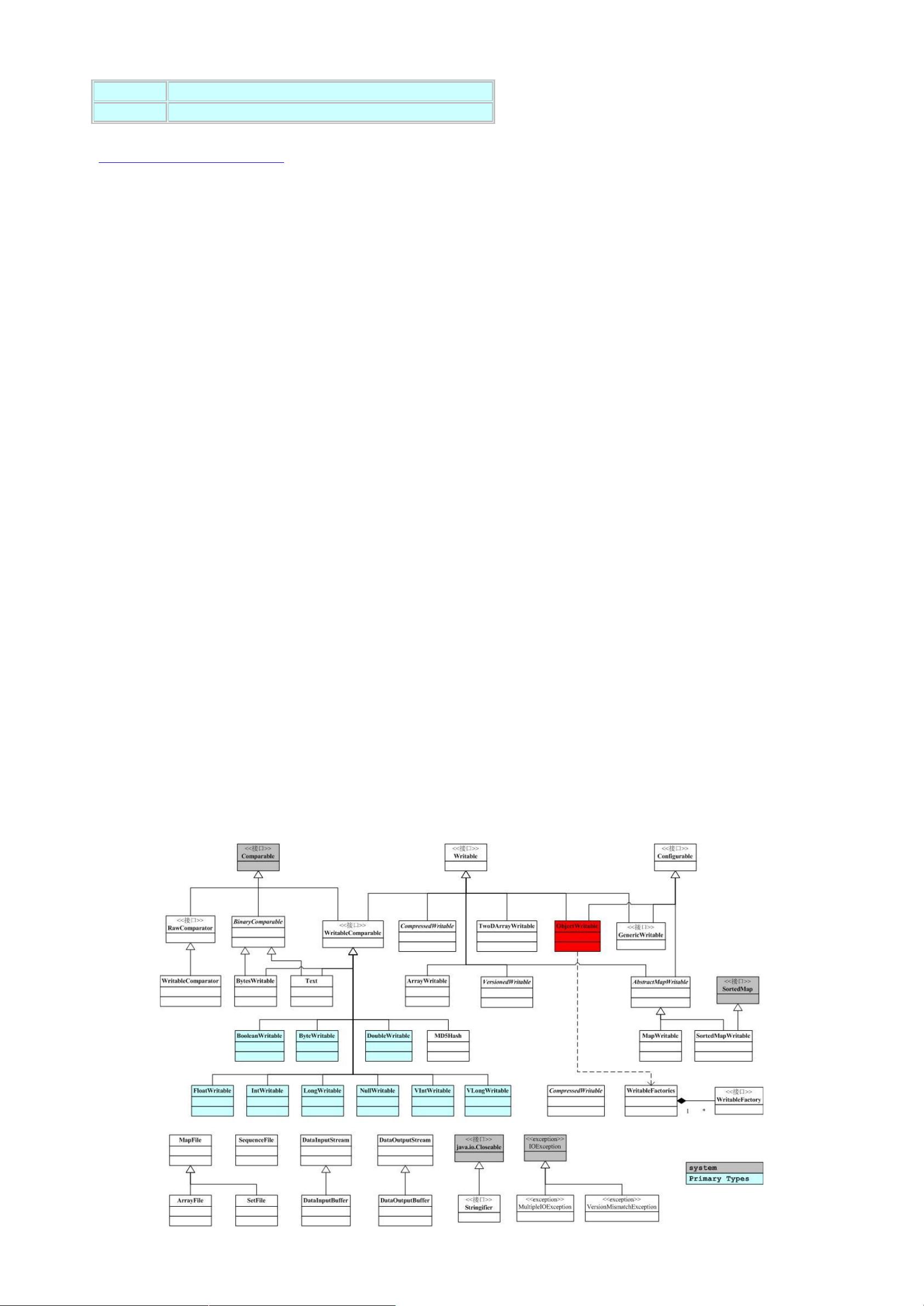
下图是 整个项目的顶层包图和他们的依赖关系。" 包之间的依赖关系比较复杂,原因是 "' 提供了一
个分布式文件系统,该系统提供 !+,,可以屏蔽本地文件系统和分布式文件系统,甚至象 !-). 这样的在线存储系统。
这就造成了分布式文件系统的实现,或者是分布式文件系统的底层的实现,依赖于某些貌似高层的功能。功能的相互引用,造
成了蜘蛛网型的依赖关系。一个典型的例子就是包 ),) 用于读取系统配置,它依赖于 ,主要是读取配置文件的时候,
需要使用文件系统,而部分的文件系统的功能,在包 中被抽象了。
" 的关键部分集中于图中蓝色部分,这也是我们考察的重点。



剩余63页未读,继续阅读
资源评论


wangliang87421
- 粉丝: 19
- 资源: 16









最新资源
- (18956428)STM32F103C8T6 小系统原理图 PCB
- (175828796)python全国疫情数据爬虫可视化分析系统(django)源码数据库演示.zip
- 记账本项目市场需求文档(MRD)
- (31687028)PID控制器matlab仿真.zip
- 基于SpringBoot的“在线答疑系统”的设计与实现(源码+数据库+文档+PPT).zip
- (11828838)进销存系统源码
- 记账本项目三大模块原型图
- fed54987-3a28-4a7a-9c89-52d3ac6bc048.vsidx
- (177367038)QT实现教务管理系统.zip
- (178041422)基于springboot网上书城系统.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


