


vikingred
- 粉丝: 1
- 资源: 12









最新资源
- 散装物料卸船机step全套技术开发资料100%好用.zip
- MSS市场专项考试题库
- (174756810)跨年烟花代码python
- (175424836)JSP企业电子投票系统(源代码+论文+开题报告+外文翻译+文献综述).rar
- (175470002)JSP企业电子投票系统(源代码+论文+开题报告+外文翻译+文献综述)
- (175759628)贪吃蛇.zip
- (175833246)JSP企业电子投票系统(源代码+论文+开题报告+外文翻译+文献综述).rar.tar.gz
- 自行车、汽车、猫、狗、人类、入侵者检测39-YOLO(v5至v11)、COCO数据集合集.rar
- (175860660)基于51单片机直流电压电流表设计LCD1602液晶实训仿真
- (175931624)基于jsp的投票管理系统源码数据库论文.doc
- 在ARM9核心板KNM1001上实现uIP FTP及TFTP客户端
- (176056440)zotero 插件分享 茉莉花压缩包
- Overview of the Scalable Video Coding Extension of the H.264/AVC Standard
- 汽车之家计量学分析.zip
- (176074624)EPLAN P8部件库:包含低压电气控制系统设计常用品Pai型号 导入单个文件很小几十M,简单易用
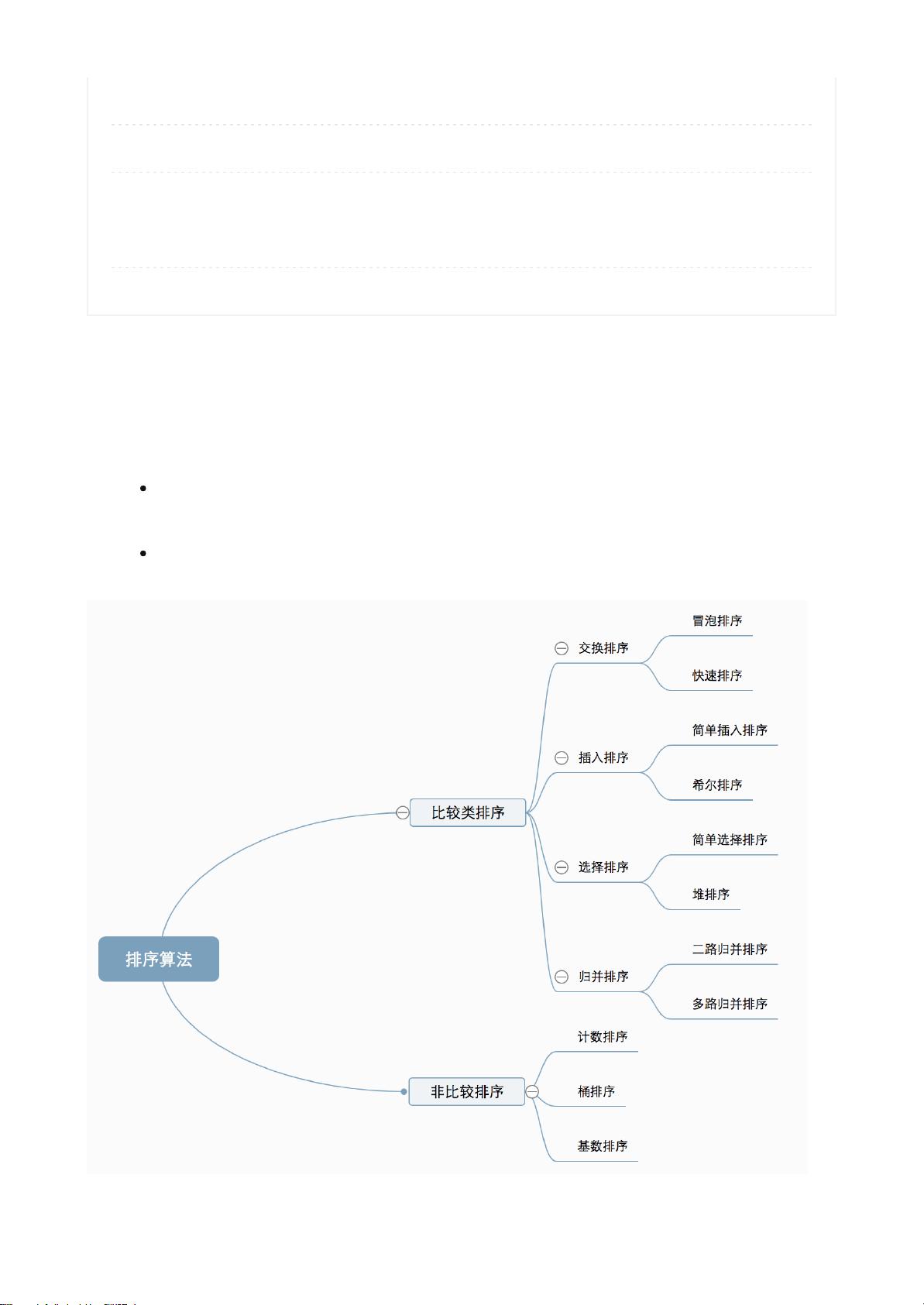
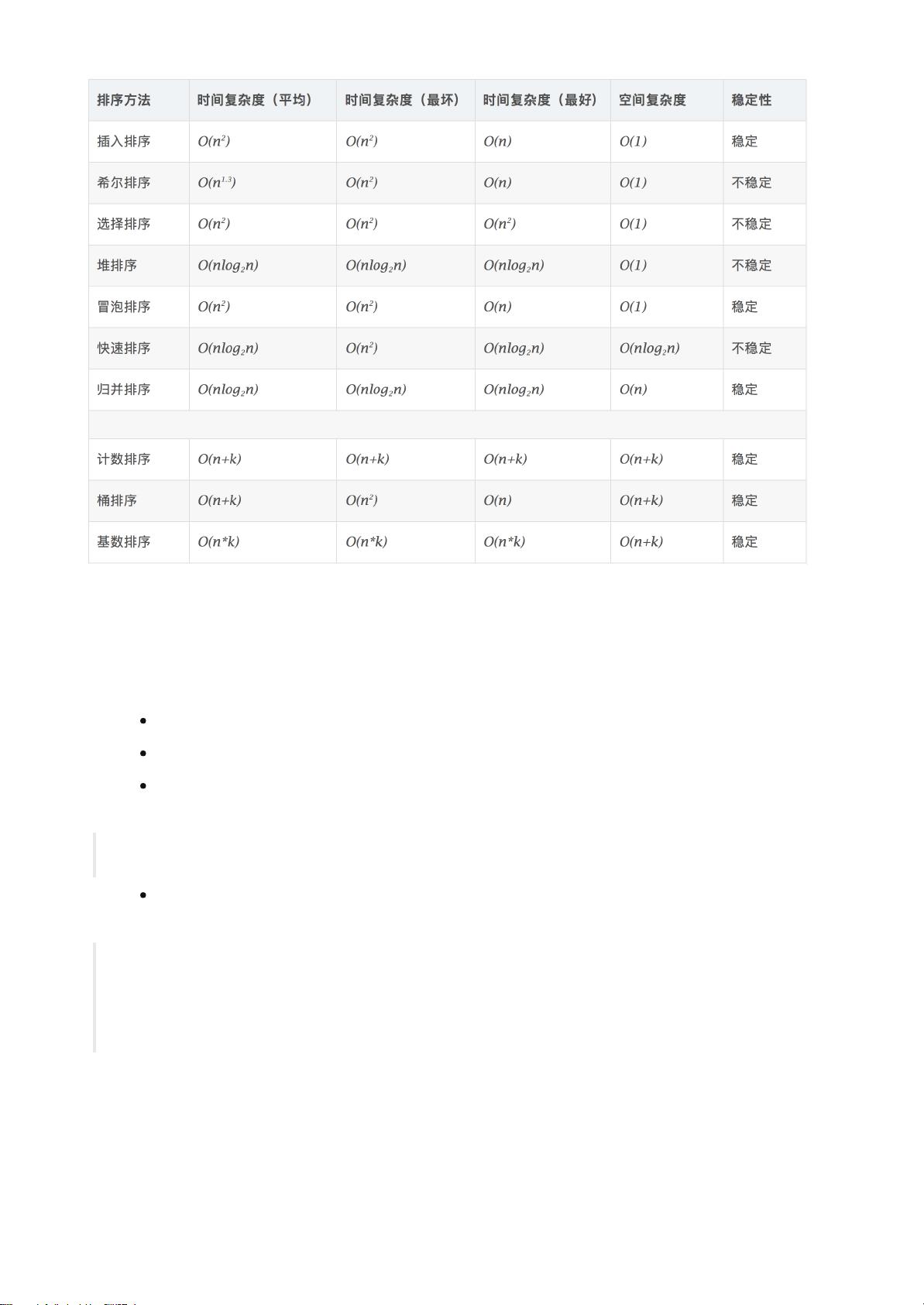
- (176333852)《数据库原理及应用教程(微课版)》关系数据库思维导图源文件
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


