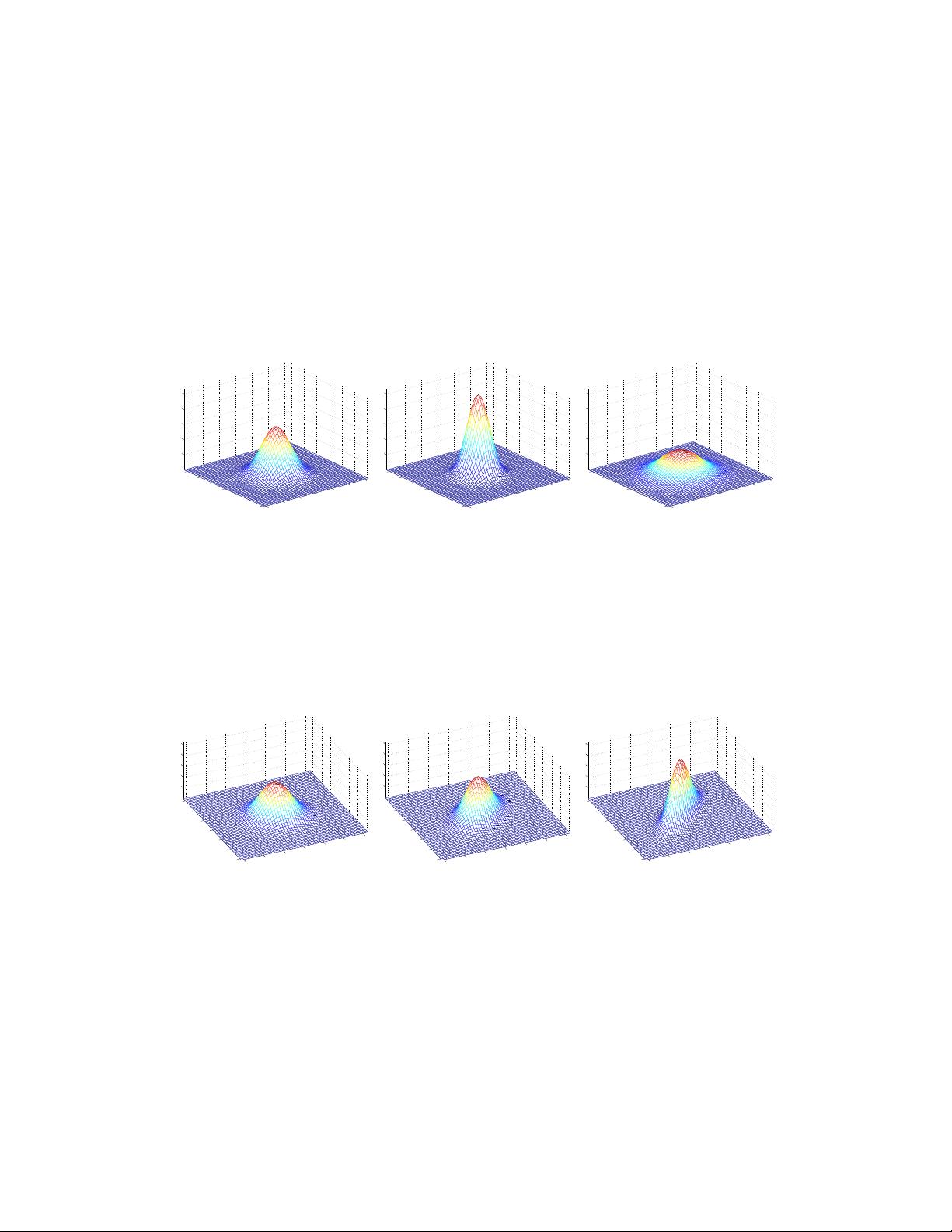
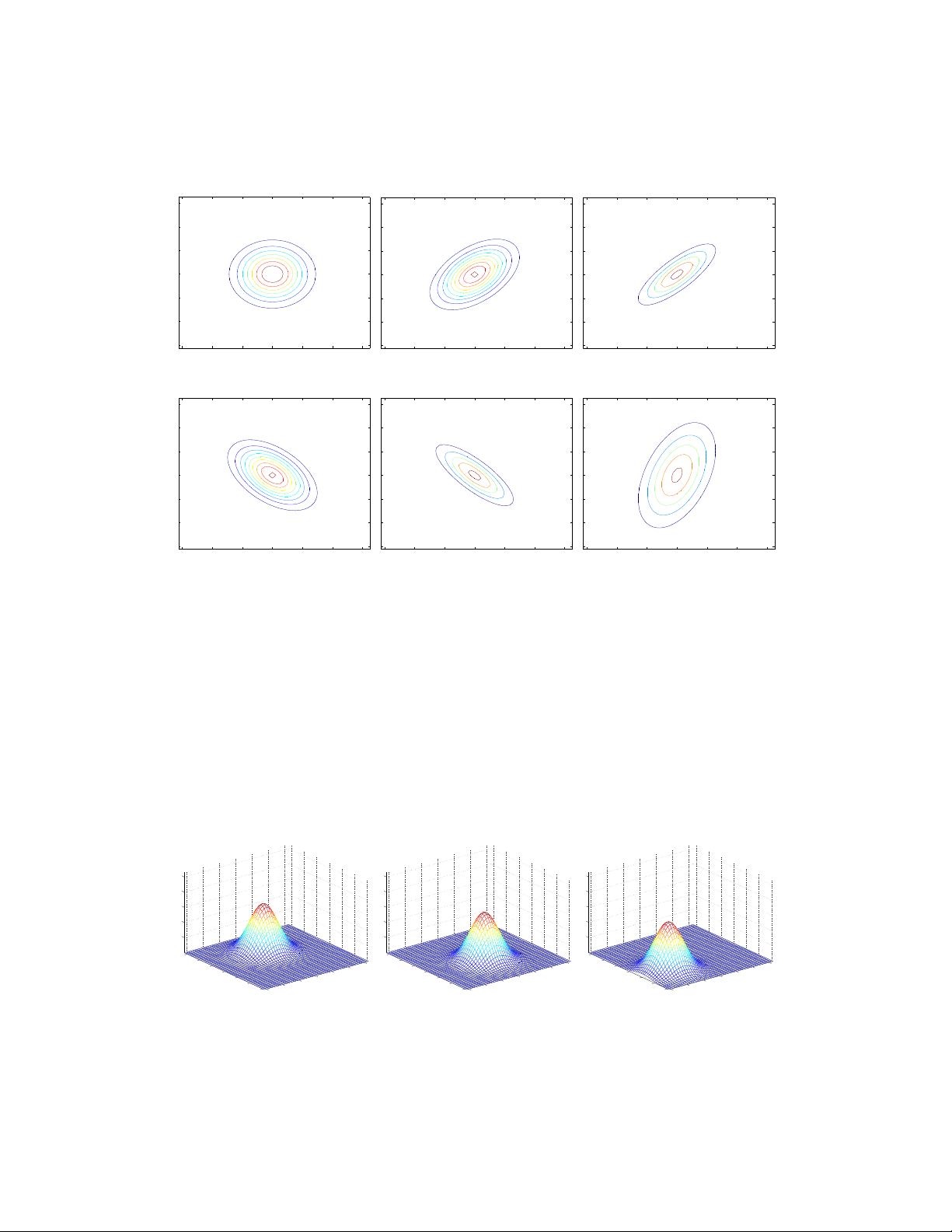
CS229 Lecture notes
Andrew Ng
Part IV
Generative Learning algorithms
So far, we’ve mainly been talking about learning algorithms that model
p(y|x; θ), the conditional distribution of y given x. For instance, logistic
regression modeled p(y|x; θ) as h
θ
(x) = g( θ
T
x) where g is the sigmoid func-
tion. In these notes, we’ll talk about a different type of learning algorithm.
Consider a classification problem in which we want to learn to distinguish
between elephants (y = 1) and dogs (y = 0), based on some featur es of
an animal. Given a training set, an algorithm like logistic regression or
the perceptron algorithm (basically) tries to find a straight line—that is, a
decision boundary—that separates the elephants and dogs. Then, to classify
a new animal as either an elephant or a dog, it checks on which side of the
decision boundar y it falls, and makes its prediction accordingly.
Here’s a different approach. First, looking at elephants, we can build a
model of what elephants look like. Then, looking at dogs, we can build a
separate model of what dogs look like. Finally, to classify a new animal, we
can match the new animal against the elephant model, and match it against
the dog model, to see whether the new animal looks more like the elephants
or more like the dogs we had seen in the training set.
Algorithms that try to learn p(y|x) directly (such as logistic regression),
or algorithms that try to lear n mappings directly from the space of inputs X
to the labels {0, 1}, (such as the perceptron algorithm) are called discrim-
inative learning algorithms. Here, we’ll talk a bout algorithms that instead
try to model p ( x|y) (and p(y)). These algorithms are called generative
learning algorithms. Fo r instance, if y indicates whether an example is a
dog (0) or an elephant (1), then p(x|y = 0) models the distribution of dogs’
features, and p(x|y = 1) models the distribution of elephants’ f eatur es.
After modeling p(y) (called the class priors) and p(x|y), our algor ithm
1