《Kafka原理剖析及实战演练》 第一版 郭俊(Jason Guo) http://www.jasongj.com
DATAGURU专业数据分析社区
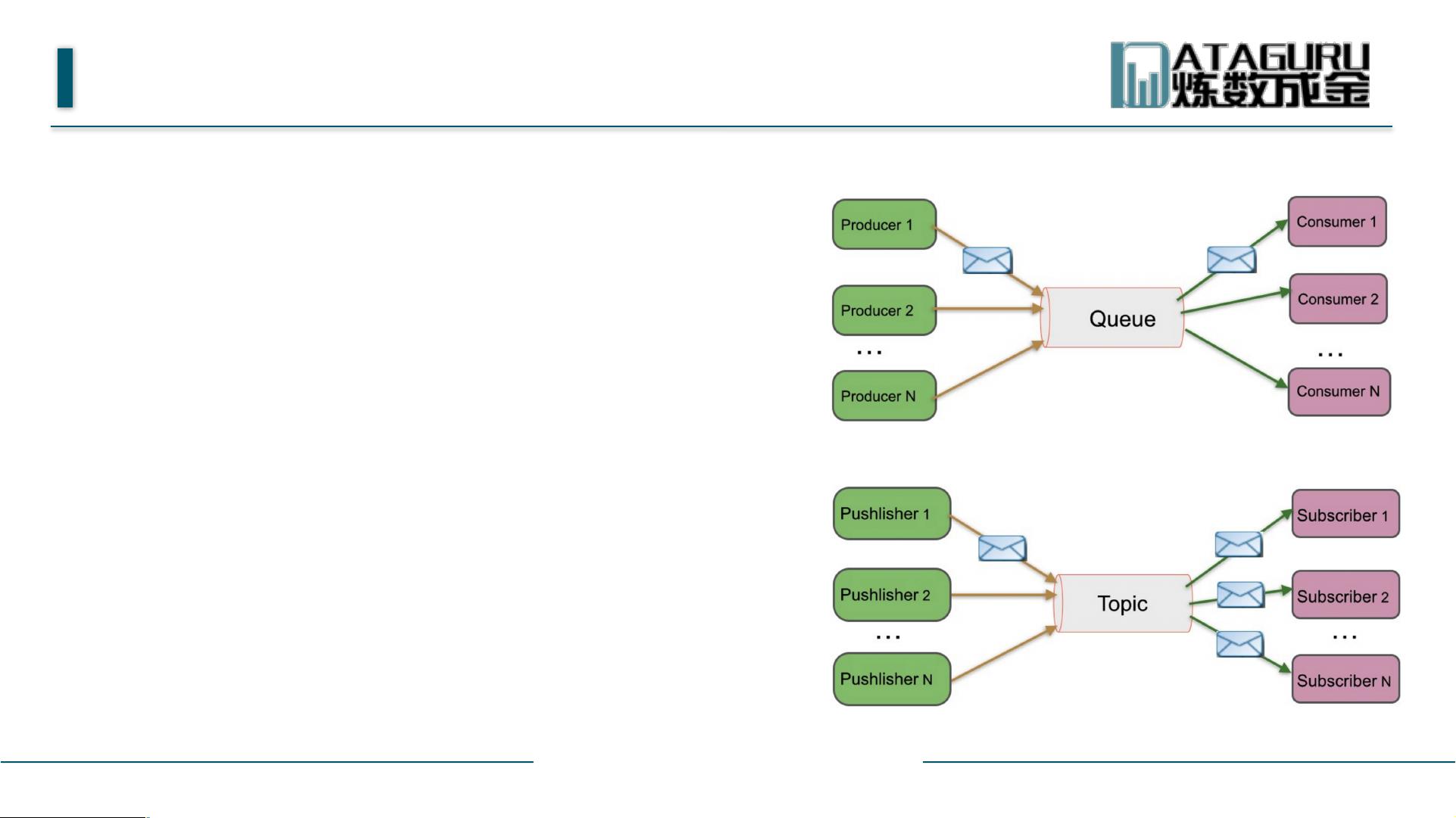
消息系统分类
n Peer-to-Peer
Ø 一般基于Pull或者Polling接收消息
Ø 发送到队列中的消息被一个而且仅仅一个接收者所接收,
即使有多个接收者在同一个队列中侦听同一消息
Ø 即支持异步“即发即弃”的消息传送方式,也支持同步请
求/应答传送方式
n 发布/订阅
Ø 发布到一个主题的消息,可被多个订阅者所接收
Ø 发布/订阅即可基于Push消费数据,也可基于Pull或者
Polling消费数据
Ø 解耦能力比P2P模型更强















