

数据库分库分表思路
一. 数据切分
关系型数据库本身比较容易成为系统瓶颈,单机存储容量、连接数、处理能力都有限。当
单表的数据量达到 1000W 或 100G 以后,由于查询维度较多,即使添加从库、优化索引,
做很多操作时性能仍下降严重。此时就要考虑对其进行切分了,切分的目的就在于减少数
据库的负担,缩短查询时间。
数据库分布式核心内容无非就是数据切分(Sharding),以及切分后对数据的定位、整合。
数据切分就是将数据分散存储到多个数据库中,使得单一数据库中的数据量变小,通过扩
充主机的数量缓解单一数据库的性能问题,从而达到提升数据库操作性能的目的。
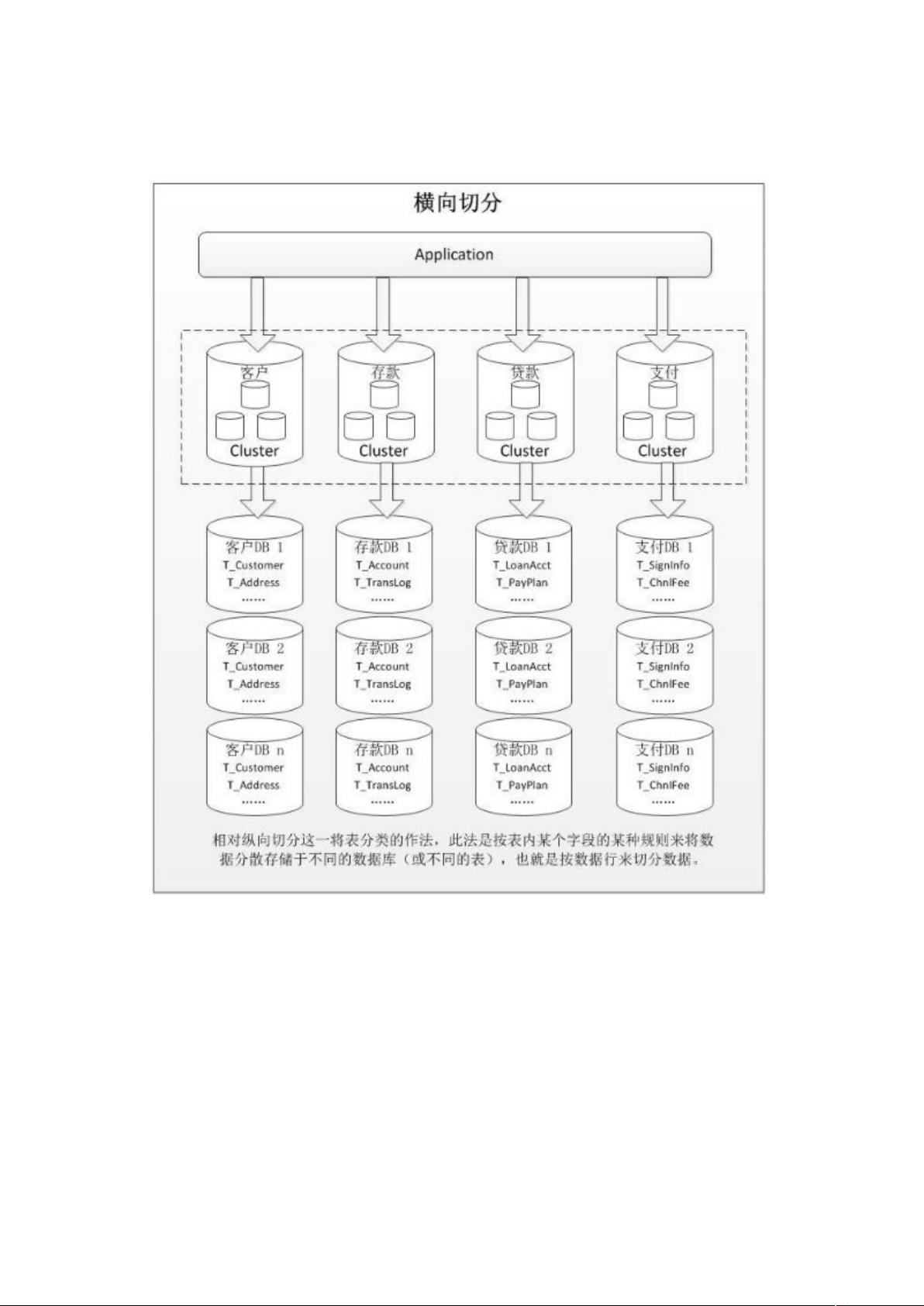
数据切分根据其切分类型,可以分为两种方式:垂直(纵向)切分和水平(横向)切分
1、垂直(纵向)切分
垂直切分常见有垂直分库和垂直分表两种。
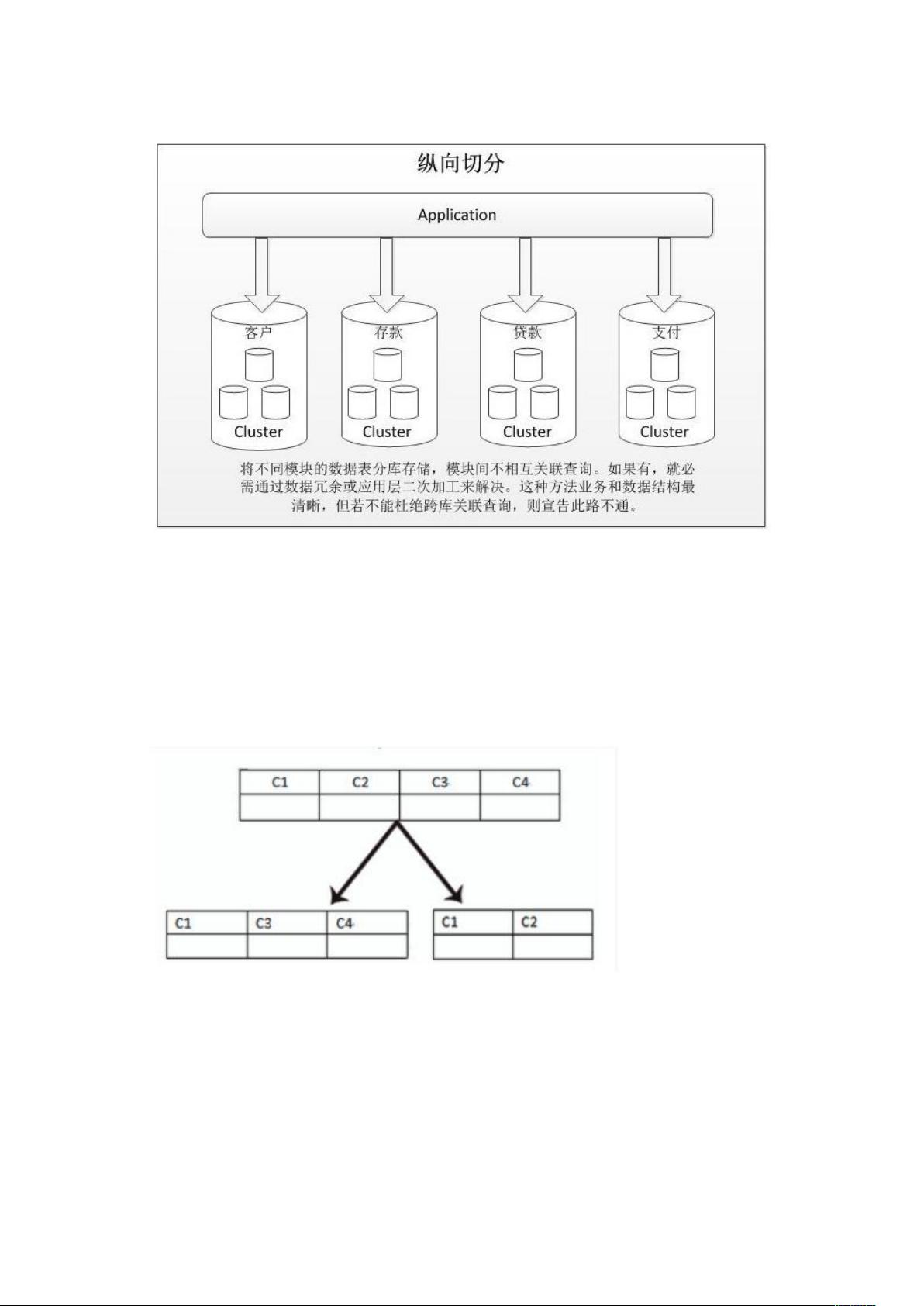
垂直分库就是根据业务耦合性,将关联度低的不同表存储在不同的数据库。做法与大系统
拆分为多个小系统类似,按业务分类进行独立划分。与"微服务治理"的做法相似,每个微
服务使用单独的一个数据库。如图:

剩余21页未读,继续阅读
资源评论


lds0331
- 粉丝: 0
- 资源: 4









最新资源
- 使用网络协议分析器捕捉和分析协议数据包-计算机网络实验报告.docx
- 明清名医全书大成(尤在泾医学全书 ).pdf
- LLC谐振参数计算实例,mathcad格式,列出完整计算公式,软件自动计算并绘出增益曲线,方便修改设计参数,本实例是实际产品的计算,已验证其正确性 送LLC原理详解和设计步骤文档PDF
- 明清名医全书大成(薛立斋医学全书 ).pdf
- 明清名医全书大成(喻嘉言医学全书 ).pdf
- 配置网络路由-计算机网络实验报告.docx
- XXX陶瓷工厂的进销存管理系统的设计与实现毕业设计中期检查表.doc
- 明清名医全书大成(张璐医学全书 ).pdf
- 明清名医全书大成(周学海医学全书 ).pdf
- 七家诊治伏邪方案(1).pdf
- 密封条锯切式裁断机sw18可编辑全套技术资料100%好用.zip
- 浅谈姜、桂、附的临床应用.PDF
- 秦伯未《内经类证》.pdf
- 秦伯未《治疗格律》.pdf
- ESC标定开发流程,文档,ppt
- 清代名医医案精华 陈良夫医案精华.pdf
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


