Learning Rich Features for Image Manipulation Detection
Peng Zhou
1
Xintong Han
1
Vlad I. Morariu
2 ∗
Larry S. Davis
1
1
University of Maryland, College Park
2
Adobe Research
pengzhou@umd.edu {xintong,lsd}@umiacs.umd.edu morariu@adobe.com
Abstract
Image manipulation detection is different from tradi-
tional semantic object detection because it pays more at-
tention to tampering artifacts than to image content, which
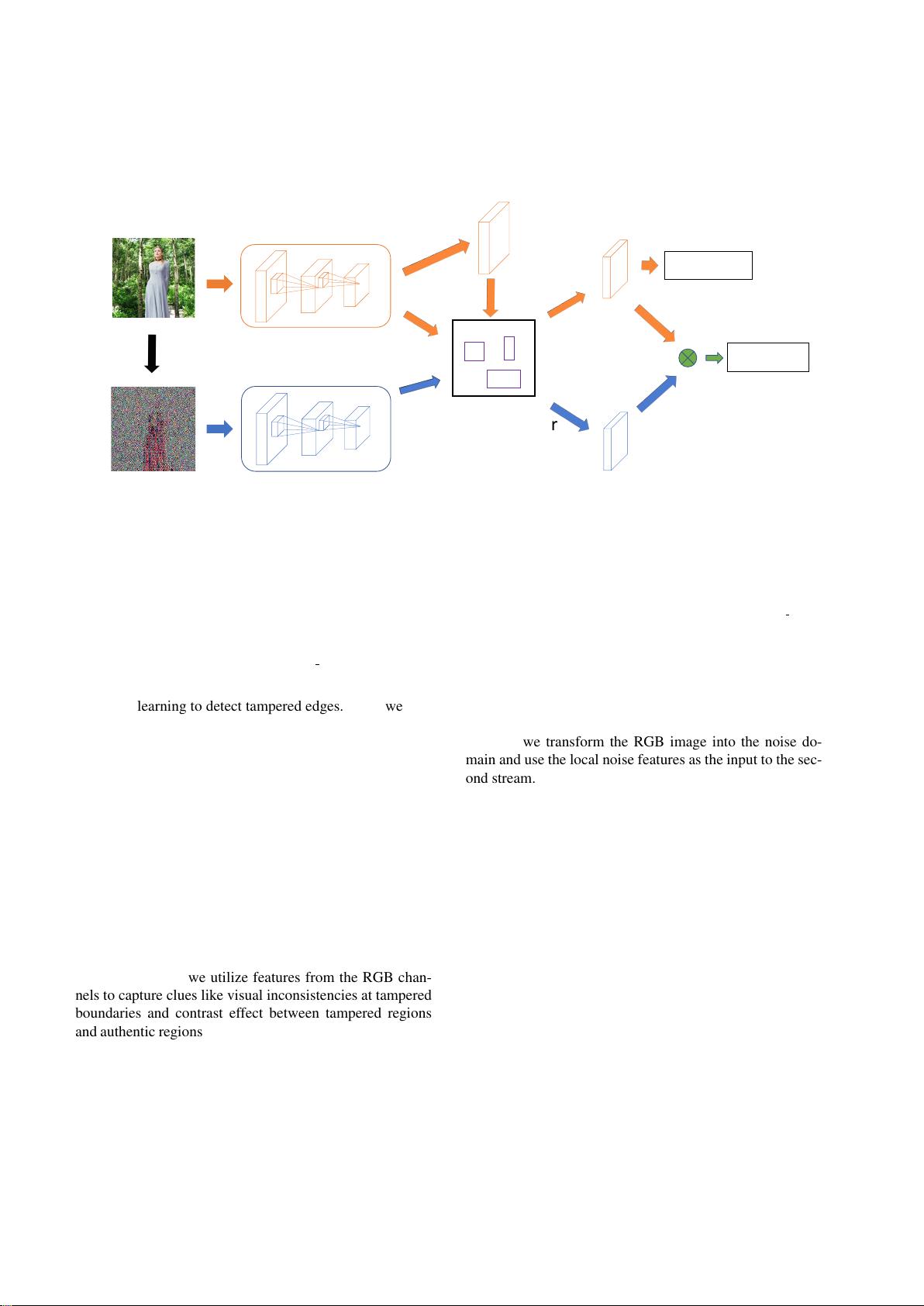
suggests that richer features need to be learned. We pro-
pose a two-stream Faster R-CNN network and train it end-
to-end to detect the tampered regions given a manipulated
image. One of the two streams is an RGB stream whose pur-
pose is to extract features from the RGB image input to find
tampering artifacts like strong contrast difference, unnatu-
ral tampered boundaries, and so on. The other is a noise
stream that leverages the noise features extracted from a
steganalysis rich model filter layer to discover the noise in-
consistency between authentic and tampered regions. We
then fuse features from the two streams through a bilinear
pooling layer to further incorporate spatial co-occurrence
of these two modalities. Experiments on four standard im-
age manipulation datasets demonstrate that our two-stream
framework outperforms each individual stream, and also
achieves state-of-the-art performance compared to alterna-
tive methods with robustness to resizing and compression.
1. Introduction
With the advances of image editing techniques and user-
friendly editing software, low-cost tampered or manipulated
image generation processes have become widely available.
Among tampering techniques, splicing, copy-move, and re-
moval are the most common manipulations. Image splicing
copies regions from an authentic image and pastes them to
other images, copy-move copies and pastes regions within
the same image, and removal eliminates regions from an
authentic image followed by inpainting. Sometimes, post-
processing like Gaussian smoothing will be applied after
these tampering techniques. Examples of these manipula-
tions are shown in Figure 1. Even with careful inspection,
humans find it difficult to recognize the tampered regions.
∗
The work was done while the author was at the University of Maryland
Authentic image Ground-truth maskTampered image
SplicingCopy-moveRemoval
Figure 1. Examples of tampered images that have undergone dif-
ferent tampering techniques. From the top to bottom are the exam-
ples showing manipulations of splicing, copy-move and removal.
As a result, distinguishing authentic images from tam-
pered images has become increasingly challenging. The
emerging research focusing on this topic — image foren-
sics — is of great importance because it seeks to prevent at-
tackers from using their tampered images for unscrupulous
business or political purposes. In contrast to current object
detection networks [28, 18, 10, 32, 16, 31] which aim to de-
tect all objects of different categories in an image, a network
for image manipulation detection would aim to detect only
the tampered regions (usually objects). We investigate how
to adopt object detection networks to perform image manip-
ulation detection by exploring both RGB image content and
image noise features.
Recent work on image forensics utilizes clues such as lo-
cal noise features [35, 26] and Camera Filter Array (CFA)
patterns [19] to classify a specific patch or pixel [11] in an
image as tampered or not, and localize the tampered regions
[19, 9, 6]. Most of these methods focus on a single tamper-
ing technique. A recently proposed architecture [2] based
on a Long Short Term Network (LSTM) segments tampered
patches, showing robustness to multiple tampering tech-
1
arXiv:1805.04953v1 [cs.CV] 13 May 2018
图像处理检测不同于传统的语义对象检测,因为它更注重篡改内容而不是图像本身的内容,这表明需要学习更丰富的特征。
本文提出了一个双流Faster R-CNN网络并训练它端到端以检测给定图像的篡改区域。两个流中的一个是RGB流,其目的是从
RGB图像输入中提取特征以找到诸如强对比度差异,非自然篡改边界等的篡改伪像。另一种是利用从富含隐写分析的模型滤
波器层提取的噪声特征来发现真实和篡改区域之间的噪声不一致的噪声流。然后,作者通过双线性池化层融合来自两个流的
特征,以进一步结合这两种模态的空间共现。在四个标准图像处理数据集上的实验表明,本文的双流框架优于每个单独的
流,并且与具有调整大小和压缩的鲁棒性的替代方法相比,还实现了最先进的性能。